February 02, 2008
Big data is old news
I continue to think the trend towards treating the RDBMS as a dumb indexed filesystem is rather ridiculous. So, here's a rant, coming from an old Data Warehousing guy with an Oracle Certified Professional past, who also happens to be a web developer, distributed systems guy, etc.
Witness the blogosphere reaction to DeWitt and Stonebraker's recent critique of MapReduce. I thought Stonebraker's critique was spot on. Apparently I'm the only person in my Bloglines list that thought so.
A major complaint is that people seem to think Stonebraker missed the point that MapReduce is not a DBMS, so why critique like it were one? But this seemed obvious: there is a clear trend that certain developers, architects, and influential techies are advocating that the DBMS should be seen as a dumb bit bucket, and that the state-of-the-art is moving back to programmatic APIs to manipulate data, in an effort to gain scalability and partition-tolerance. Map Reduce is seen as a sign of the times to come. These are the "true believers" in shared nothing architecture. This is Stonebraker's (perhaps overstated) "step backwards".
My cynical side thinks this is the echo chamber effect -- it grows in developer circles, through blogs, conferences, mailing-lists, etc., self-reinforcing a misconception about the quality of what an RDBMS gives you. From what I've seen on the blogosphere, most web developers, even the really smart ones, have a complete lack of experience in understanding a) the relational model, and b) working with a modern RDBMS like Oracle 10g, MS SQL 2005, or DB2 UDB. And even practitioners in enterprises have a disconnect here (though I find it's not as pronounced). There clearly are _huge_ cultural and knowledge divides between developers, operating DBAs, and true database experts in my experience. It doesn't have to be this way, but it's a sign of our knowledge society leading to ever-more-specialized professions.
Now, to qualify my point, I completely understand that one has to make do with what one has, and come up with workable solutions. So, yes, de-normalize your data if your database doesn't have materialized views. Disable your integrity constraints if you're just reading a bunch of data for a web page. But, please let's remember:
- massively parallel data processing over hundreds or sometimes 1000+ nodes really _has_ been done since the 1980's, and has not required programmatic access (like MapReduce) for a long, long time -- it can be done with a SQL query.
- denormalization is appropriate for read-mostly web applications or decisions support systems. many OLTP applications have a mixed read/write profile. and data integration in a warehouse benefits from normalization (even if the queries do not)
- modern databases allow you to denormalize for performance while retaining a normalized structure for updates: it's called a materialized view.
- many analysts require very complicated, unpredictable, exploratory queries that are generated at runtime by OLAP tools, not developers.
- consistency is extremely important in many data sets. It may not require it for all cases. There definitely is a clear case to relax this in some cases to eventual consistency, expiry-based leasing & caching, and compensations. But, generating the aggregate numbers for my quarterly SEC filings, even if it involves scanning *billions* of rows, requires at least snapshot consistency across all of those rows, lest you want your CFO to go to jail.
- data quality is extremely important in many domains. Poor data quality is a huge source of customer dissatisfaction. Disabling integrity constraints, relaxing normalization for update-prone data, disallowing triggers & stored procs, etc. will contribute to the degrading of quality.
- Teradata has been doing massively parallel querying for almost 25 years (1024 nodes in 1983, the first terabyte DBMS in 1992 with Walmart, many hundreds of terabytes with others now!).
- Oracle's Parallel Server (OPS) has been out for almost 17 years. Real Application Clusters is OPS with networked cache coherency, and is going to be 7 years old this year.
- Take a look at this 2005 report of the top Data Warehouses. This is a voluntary survey; there are much larger systems out there. You'll notice that Yahoo! was running a single node 100 terabyte SMP warehouse. Amazon.com is running a couple of Linux-based Oracle RAC warehouses in the 15-25 terabyte range since 2004.
The point is that there is no magic here. Web developers at Amazon, eBay, Youtube, Google, SixApart, Del.icio.us, etc. are doing what works for them *today*, in their domain. There is no evidence that their solutions will be a general purpose hammer for the world's future scalable data management challenges. There's a lot more work and research to be done to get there, and I don't think it's going to primarily come out of the open source community the way it did for the Web. Sorry.
Look, I think products such as MySQL + InnoDB, are fantastic and even somewhat innovative. They give IBM, MS, and Oracle a big run for their money for many applications.
On the other hand, *no* open source RDBMS that I'm aware of has a general purpose built-in parallel query engine. Or a high-speed parallel data loader. But, if it isn't open source, it doesn't seem to exist to some people. I can understand why ($$ + freedom), though I think usage-based data grids will greatly reduce the first part of that challenge.
It's been 3 years since I discussed (here too) Adam Bosworth's "there are no good databases" blog entry. I felt that many of the problems he expressed have to do with the industry's vociferous ignorance, but I did agree there was room for innovation. The trends towards Column-Oriented DBMS seems to be playing as expected, encouraging innovation at the physical layer. I still haven't seen a good unification of querying vs. searching in general databases yet -- they still feel like independent islands. But, if anything, the vociferous ignorance has gotten worse, and that's a shame.
So, what's the trend?
- Much of the limitations of RDBMS' have nothing to do with the relational model, but have to do with an antiquated physical storage format. There are alternatives that are fast emerging. Take a look at the latest TPC-H benchmarks. Between ParAccel and EXASOL, not to mention Stonebraker's Vertica, there's a revolution underway.
- I do think parallel data processing will graduate out of its proprietary roots and become open source commoditized. But this is going to take a lot longer than people think, and will be dominated by commercial implementations for several more years, unless someone decides to donate their work (hint).
- I think the trend will be towards homegrown, programmatic data access and integrity solutions over the coming years, as a new generation re-learns data management and makes the same mistakes our parents made in the 1960's and 70's, and our OODBMS colleagues made in the 1990's. Whether this is maintainable or sustainable depends on who implemented it.
- I think the Semantic Web may actually turn out to be the renaissance of the RDBMS, and a partial way out of this mess. RDF is relational, very flexible, very partitionable across a column-oriented DBMS on grid, solves many of the agility problems with traditional schema and constraints, and simplifies some aspects of data integration. The obstacles will be: making it simpler for everyday use (eliminating the need for a degree in formal logic), and finding organizations who will make the leap.
January 30, 2008
Relations in the cloud
I've been hearing a lot about how the RDBMS are no longer appropriate for data management on the Web. I'm curious about this.
Future users of megadata should be protected from having to know how the data is organized in the computing cloud. A prompting service which supplies such information is not a satisfactory solution.Activities of users through web browsers and most application programs
should remain unaffected when the internal representation of data is changed and even when some aspects of the external representation are changed. Changes in data representation will often be needed as a result of changes in query, update, and report traffic and natural growth in the types of stored information.
I didn't write the above, it was (mostly) said 38 years ago. I think the arguments still hold up. Sure, Google and Yahoo! make do with their custom database. But, are these general-purpose? Do they suffer from the same problems of prior data stores in the 60's?
Certainly there's a balance of transparency vs. abstraction here that we need to consider: does a network-based data grid make a logical view of data impossible due to inherent limitations of distribution?
I'm not so sure. To me this is just a matter of adjusting one's data design to incorporate estimates, defaults, or dynamically assessed values when portions of the data are unavailable or inconsistent. If we don't preserve logical relationships in as simple a way as possible, aren't we just making our lives more complicated and our systems more brittle?
I do agree that there's a lot to be said about throwing out the classic RDBMS implementation assumptions of N=1 data sets, ACID constraints at all times, etc.
I do not agree that it's time to throw out the Relational model. It would be like saying "we need to throw out this so-called 'logic' to get any real work done around here".
There is a fad afoot that "everything that Amazon, Google, eBay, Yahoo!, SixApart, etc. does is goodness". I think there is a lot of merit in studying their approaches to scaling questions, but I'm not sure their solutions are always general purpose.
For example, eBay doesn't enable referential integrity in the database, or use transactions - they handle it all in the application layer. But, that doesn't always seem right to me. I've seen cases where serious mistakes were made in the object model because the integrity constraints weren't well thought out. Yes, it may be what was necessary at eBay's scale due to the limits of the Oracle's implementation of these things, but is this what everyone should do? Would it not be better long-term if we improved the underlying data management platform? I'm concerned to see a lot of people talking about custom-integrity, denormalization, and custom-consistency code as a pillar of the new reality of life in the cloud instead of a temporary aberration while we shift our data management systems to this new grid/cloud-focused physical architecture. Or perhaps this is all they've known, and the database never actually enforced anything for them. I recall back in 1997, a room full of AS/400 developers were being introduced to this new, crazy "automated referential integrity" idea, so it's not obvious to everyone.
The big problem is that inconsistency speeds data decay. Increasingly poor quality data leads to lost opportunities and poor customer satisfaction. I hope people remember that the key word in eventual consistency is eventual. Not some kind of caricatured "you can't be consistent if you hope to scale" argument.
Perhaps this is just due to historical misunderstanding. The performance of de-normalization and avoiding joins has nothing to do with the model itself, it has to do with the way the physical databases have been traditionally constrained. On the bright side, column-oriented stores are becoming more popular, so perhaps we're on the cusp of a wave of innovation in how flexible the underlying physical structure is.
I also fear there's a just widespread disdain for mathematical logic among programmers. Without a math background, it takes a long time for one to understand set theory + FOL and relate it to how SQL works, so most just use it as a dumb bit store. The Semantic Web provides hope that the Relational Model will live on in some form, though many still find it scary.
In any case, I think there are many years of debate ahead as to the complexities and architecture of data management in the cloud. It's not as easy as some currently seem to think.
January 14, 2008
Shared, err, something
From (the otherwise great book) Advanced Rails, under Ch. 10, "Rails Deployment"...
"The canonical Rails answer to the scalability question is shared-nothing (which really means shared-database): design the system so that nearly any bottleneck can be removed by adding hardware."
Nonsensical, but cute.
This seems like a classic case of Semantic Diffusion. It's funny how people find a buzzword, and latch onto it, while continuing to do what they always did. "We're agile because we budget no time for design" -- "We're REST because we use HTTP GET for all of our operations" -- "We're shared nothing because we can scale one dimension of our app, pay no attention to the shared database behind the curtain, that's a necessary evil".
A shared nothing architecture would imply:
- each Mongrel has its own Rails deployment with its own database
- that database had a subset of the total application's data
- some prior node made the decision on how to route the request.
...And we don't always do this because some domains are not easily partitionable, and even so, you get into CAP tradeoffs wherein our predominant model of a highly available and consistent world is ruined.
Now, I know that some would ask "what about caches?". The "popular" shared-something architecture of most large scale apps seem to imply:
- each app server has its own cache fragment
- replicas might be spread across the cache for fault tolerance
- the distributed cache handles 99% of requests
- what few writes we have trickle to a shared database ( maybe asynchronously)
Which does help tremendously if you have a "read mostly" application, though it doesn't help reduce the scaling costs of shared writes. Good for web apps, but from what I've seen (outside of brokerages) this has not caught on in the enterprise as broadly as one would hope, except as an "oh shit!" afterthought. Hopefully that will change, where appropriate, but recognize that these caches, whether memcached, or Tangosol, or Gigaspaces, or Real Application Clusters are about making "shared write" scalability possible beyond where it was in the past; it doesn't mean you're going to scale the way Google does.
Here's one of Neil Gunther's graphics that shows software scalability tradeoffs based on your data's potential of contention, or your architecture's coherency overhead:
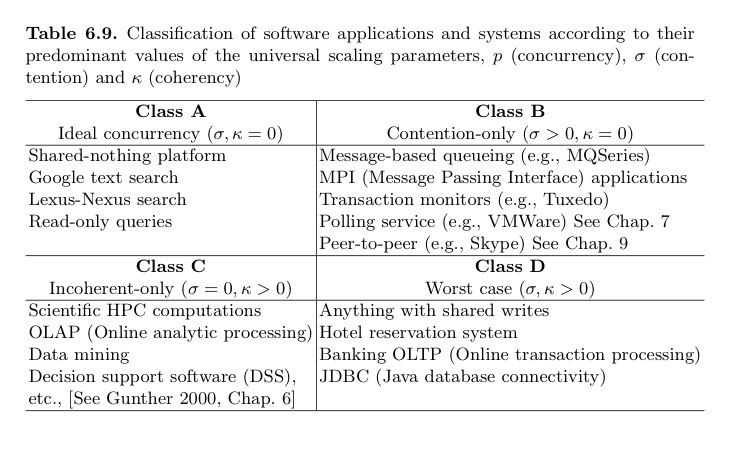
The universal scalability equation is:
C(N) = | N 1 + σN + κN (N − 1) |
Where, for software scale, N is the number of active threads/processes in your app server, σ is the data contention parameter, and κ is the cache coherency-delay parameter. Read the Guerilla Capacity Planning Manual for more details, or pick up his book.
I like this model, but there are some caveats: Firstly, I don't quite understand why Tuxedo is in Class B, yet OLTP is in Class D. Secondly, Class D's examples are so high-level that they may be misleading. The real problem here is "shared writes", which can be further broken down into a) "hotspots", i.e. a record that everyone wants to update concurrently, and b) limited write volumes due to transaction commits needing durability.
Having said this, this model shows the fundamental difference between "Shared-Nothing" and our multi-node, distributed-cache "Shared-Something". Shared-nothing architectures are those that have near-zero contention or coherency costs. Whereas shared-something is about providing systems that enhance the coherency & contention delays for Class D software, but doesn't eliminate them. They're helping the underlying hardware scalability, but not changing the nature of the software itself.
For example, write-through caching, whether in Tangosol or in a SAN array's cache, for example, can help raise commit volumes. Oracle RAC has one Tlog per cluster node, also potentially raising volumes. Networked cache coherency eliminates disk latency. But the important thing to recognize is that the nature of the software hasn't changed, we've just pushed out the scaling asymptote for certain workloads.
Anyway, let's please call a spade a spade, mm'kay? I just don't like muddied waters, this stuff is hard enough as it is....
January 03, 2008
The good in WS-*
Ganesh:Believe me, it would greatly clear the air if a REST advocate sat down and listed out things in SOAP/WS-* that were good and worth adopting by REST. It would not weaken the argument for REST one bit, and it would reassure non-partisans like myself that there are reasonable people on both sides of the debate.I'll bite. I'll look at what I think are "good", what the improvements could be in a RESTful world, and what's actually happening today. My opinions only, of course. I will refrain from discussing those specs I think are bad or ugly.
The good:
WS-Security, WS-Trust, and WS-SecureConversation
What's good about them?
- They raise security to the application layer. Security is an end-to-end consideration, it's necessarily incomplete at lower levels.
- Message-level security enhances visibility. Visibility is one of REST's key design goals. REST should adopt a technology to address this.
- It's tied to XML. All non-XML data must be wired through the XML InfoSet. XML Canonicalisation sucks.
- WS-Security itself does not use derived keys, and is thus not very secure. Hence, WS-SecureConversation. But that's not well supported.
- WS-Trust arguably overlaps with some other popular specs. Some OASIS ratified specs, like WS-SecureConversation, rely on WS-Trust, which is still a draft.
- For WS-Trust and WS-SC, compatibility with only one reference implementation is what vendors tend to test. Compatibility with others: "Here be dragons".
- SixApart has mapped the WSSE header into an HTTP header
- We could use S/MIME. There are problems with that, but there is still reason to explore this. See OpenID Data Transport Protocol Draft (key discovery, and messages) for examples of how this would work.
- One challenge that I have not seen addressed yet in the REST world is the use of derived keys in securing messages. WS-Security has this problem: reusing the same asymmetric key for encryption is both computationally expensive and a security risk. WS-SecureConversation was introduced to fix this and make WS-Security work more like SSL, just at the message level. SSL works by using derived keys: the asymmetric key is used during handshake to derive a symmetric cryptographic key, which is less expensive to use.
I recall Rich Salz, almost 3 years ago, claiming that an SSL-like protocol (like WS-SecureConversation) could not be RESTful because it has state. This isn't entirely true; authorization schemes like HTTP digest require server-side state maintenance (the nonce cache) and we don't seem to complain that this breaks HTTP. (Digest interoperability itself is often broken, but that's another story). REST stores state in two spots: (a) on the client, and (b) in resources. So, the answer seems to be, ensure the derived key (and metadata) is identified by a URI, and include a URI in the HTTP header to identify the security context. Trusted intermediaries that would like to understand the derived keys could HTTP GET that URI and cache the result. You'd probably have to use an alternate authentication mechanism (HTTP Basic over SSL, for example) to bootstrap this, but that seems reasonable. I'd like to see the OpenID Data Transport Protocol Service Key Discovery head in this direction.
WS-Coordination and WS-AtomicTransaction
What's good about them?
- Volatile or Durable two-phase commit. It works across a surprising number of App servers and TP monitors, including CICS, Microsoft-DTC (WCF), and J2EE app servers like Glassfish or JBoss. It will be very useful to smooth interoperability among them.
- It needs more widespread deployment. People are making do (painstakingly) with language-level XA drivers when they need 2PC across environments, so it may take a while for WS-AT to gain traction.
- Most of my problems with WS-AT are problems that apply equally to other 2PC protocols. I list them here because they will become "promoted" in importance now that the vendor interoperability issues have been solved with WS-AT.
- Isolation levels & boundaries. As I've mentioned in my brief exchange with Mark Little (and I'm sorry I didn't continue the thread), I think there will be lurking interoperability and performance problems. For example, isolation boundaries are basically up to the application, and thus will be different for every service interface. Like XA, the default isolation for good interop will likely be "fully serializable" isolation, though it's not clear that a client can assume that _all_ data in a SOAP body would have this property, as there might be some transient data.
- Latency. Like any 2PC protocol, WS-AT is only viable in a low-latency environment like an intranet, and specific data items cannot require a high volume of updates. A typical end-to-end transaction completion involving two services will require at minimum 3 to 4 round-trips among the services. For example, given Service A is the transaction initiator and also is colocated with the coordinator, we have the following round trips: 1 for tx register, 1 for a 'read' action, 1 for a 'write' action, and 1 for prepare. If your write action can take advantage of a field call, you could reduce this to 3 round trips by eliminating the read. The number of trips will grow very fast if you have transaction initiators and coordinators that are remote to one of the participating services, or if you start mixing in multiple types of coordinators, such as WS-BusinessActivity.
Here is a latency-focused "when distributed transactions are an option" rule of thumb: be sure any single piece of data does not require transactionally consistent access (read OR write!) any quicker than ( 1 / N*d + c ) per second, where N = number of network trips required for a global transaction completion, d is the average latency between services in seconds, and c is the constant overhead for CPU usage and log disk I/O (a log write is usually required for each written-to service + the coordinator). If you exceed this rate, distributed transactions will hurt your ability to keep up. This rule does not account for failures & recovery, so, adjust for MTTF and MTTR...
An example best case: In a private LAN environment with- 0.5ms network latency (i.e. unsaturated GigE)
- "write only" transaction (3 trips) from Service A to Service B
- a "c" of 3 disks (coordinator, service 1, service 2) with 1 ms log write latency (which assumes a very fast write-cached disk!)
- Availability. Again, this isn't really WS-AT's fault, as this problem existed in COM+ and EJB before it, but WS-AT's potential success would catapult this into the limelight. Here's the sitch: Normally, if you enroll a database or a queue into a 2PC, it knows something about the data you're accessing, so it can make some good decisions about balancing isolation, consistency, and availability. For example, it may use "row locks", which are far granular than "table locks". Some also have "range locks" to isolate larger subsets of data. The component framework usually delegates to the database to handle this, as the component itself knows nothing about data and is usually way too coarse grained to exclusively lock without a massive impact on data availability.
In WS-land, a similar situation is going to occur. WS stacks tend to know very little about data granularity & locking, while DBMS do. So, most will rely on the DBMS. Yet relying on the DBMS to handle locks will defeat a lot of service-layer performance optimizations (like caching intermediaries, etc.), relegating most services to the equivalent of stateless session beans with angle brackets. This doesn't seem to be about what SOA is about. So, what's the improvement I'm suggesting here? Service frameworks need to become smarter in terms of understanding & describing data set boundaries. RESTful HTTP doesn't provide all the answers here, but it does help the caching & locking problem with URIs and ETags w/ Conditional-PUT and Conditional-GET.
- Firstly, there's the question of whether it's possible to have ACID properties across a uniform interface. The answer to me is: sure, if you own all the resources, and you don't care there is no standard. With standard HTTP/HTML hypermedia, one just has to bake support into their application using PUT/POST actions for boundaries. Picture any website with an "edit mode" with undo or confirm, and you've pretty much enabled the ACID properties. Unfortunately, each site would have a non-standard set of conventions to enable this, which hurts visibility.
- Enabling a standard (visible) protocol for REST across different resources might be possible; Rohit has sketched this out in his thesis for 2-way agreements (i.e. the REST+D style), which is effectively a one-phase commit, and for N-way resource replicas (i.e. the ARREST+D style), and he also showed how the implementation would fit into the current Web architecture. We're already seeing his work popularized. Anyway, for a distributed commit, one possibly could extend the MutexLock gateway to support snapshot isolation, and also act as a coordinator (moving this to a two-phase protocol). But the caveats above apply -- this would only be useful for REST inside an intranet and for data that is not very hot. You still would require a Web of Trust across all participants -- downtime or heuristic errors would lock all participating resources from future updates.
WS-Choreography Description Language
What's good about it?
- It's an attempt to describe functional contracts among a set of participants. This allows for bi-simulation to verify variance from the contract at runtime. Think of it like a way to describe expected sequences, choices, assertions, pre & post-conditions for concurrent interactions.
- I think that the world of computing gradually will shift to interaction machines as a complement to Turing machines, but this is going to take time. WS-CDL is very forward thinking, dealing with a topic that is just leaving the halls of academia. It may have been premature to make a spec out of this, before (complete) products exist.
- See this article for some interesting drawbacks to the current state of WS-CDL 1.0.
- WS-CDL is tightly coupled to WSDL and XSDs. It almost completely ignores Webarch.
- Not much, that I'm aware of.
Security Assertions Markup Language (SAML)
What's good?
- Federated security assertions for both web SSO and service-to-service invocations.
- Trust models based on cryptographic trust systems such as Kerberos or PKI.
- Both open source implementations and vendor implementations.
- It doesn't have a profile to take advantage of HTTP's Authorization mechanism; this is because browsers don't allow extensibility there. It's not a deal-breaker, it's a smell that goes beyond SAML (browsers haven't changed much since Netscape's decisions in the 90's).
- It assumes authentication is done once, and then stored in a cookie or a session. To be RESTful, it should be either asserted on each request, or stored in a resource, and the URI should be noted in an HTTP header or in the body as the reference to the assertion (similar to OpenID).
- While the actual Browser profiles are generally RESTful, the API for querying attributes, etc. is based on SOAP.
- SAML over SSL is easy to understand. SAML over XML Signature and Encryption is a bitch to understand (especially holder-of-key).
- It is a bit heavyweight. Assertions contain metadata that's often duplicated elsewhere (such as your transport headers).
- There are several different identity & attribute formats that it supports (UUID, DCE PAC, X.500/LDAP, etc.). Mapping across identifiers may be useful inside an enterprise, but it won't scale as well as a uniform identifier.
- OpenID 2.0. It doesn't cover everything, there's questions about phishing abuse, but it's probably good enough. SAML is a clear influence here. The major difference is that it uses HTTP URIs for identity, whereas SAML uses any string format that an IdP picks (there are several available).
The questionable:
WS Business Process Execution Language (WS-BPEL)
What's good?
- Raising the abstraction bar for a domain language specifying sequential processes.
- It's more focused on programmers (and hence, vendors selling programmer tools) than on the problem space of BPM and Workflow.
- It relies on a central orchestrator, and thus seems rather like a programming language in XML.
- Very XML focused; binding to specific languages requires a container-specific extension like Apache WSIF or JCA or SCA or ....
- BPEL4People and WS-HumanTask are a work in progress. Considering the vast majority of business processes involve people, I'd say this is a glaring limitation.
- BPEL treats data as messages, not as data that has identity, provenance, quality, reputation, etc.
- I think there is a big opportunity for a standard human tasklist media type. I haven't scoured around the internet for this, if anyone knows of one, please let me know. This would be a win for several communities: the BPM community today has no real standard, and neither does the REST community. The problem is pretty similar whether you're doing human tasks for a call center or for a social network, whether social or enterprise. Look at Facebook notifications as a hint. Semantics might include "activity", "next steps", "assignment", etc. One could map the result into a microformat, and then we'd have Facebook-like mini-feeds and notifications without the garden wall.
- As for a "process execution language" in the REST world, I think, if any, it probably would be a form of choreography, since state transitions occur through networked hypermedia, not a centrally specified orchestrator.
Other questionables include SOAP mustUnderstand, WS-ReliableMessaging and WS-Policy. But I don't really have much to say about them that others haven't already.
Phew! Wall of text crits you for 3831. So much for being brief...December 31, 2007
Continuing the debate
Some comments on this and that, because JJ's comments truncate at 3000.
- "Talking with Subbu, I think I understand the disconnect. He works for Yahoo (same would be true for Amazon, Google, Microsoft Live...). For these people, who operate vast data centers, every CPU cycle counts. It speaks directly to their user base: if yahoo is sluggish people will switch to Google and vice versa. I, on the contrary, work as an IT architect. "
Subbu is ex-BEA. I think he understands IT architecture, thanks.
- "For IT, If I can reuse a piece of code 2-5 times, this is a tremendous savings: imagine the cost of duplicating assets in IT? re-implementing, re-testing, integrating? how about maintenance? now I need to apply my changes to several code bases in different technologies?"
I've discussed this in email with you, but besides the technical challenges, SOA reuse is a pipe dream for most organizations because they are not willing to change their investment evaluation windows or mindset about the economics of software. Most are just looking to improve their agility -- which is about the way we design interfaces & interactions, not about reused logic.
- "Guys, in the Ganesh's style, I have news for you. There has been a big composite system running for decades: EDI. "
It's not news. Mark Baker has been talking about EDI for years as an example of interchange with a type of uniform interface.
- "Stu, I may misunderstand your point but you seem to say that one thing (we need actions) and the opposite (a uniform interface gives more loose coupling, therefore don't use actions)."
What I agreed with you was that we need a *contract* to generate shared understanding. I did not claim that we needed specific actions to generate shared understanding. On the other hand, I do think it would be useful to define higher-level abstractions in terms of uniform operations, though I am not convinced this will enhance interoperability.
- Your definition of loose coupling seems to reflect a very producer-focused view of services.
For example:
"RESTful Web Services indeed offer a coupling worse than CORBA, much worse because at least with CORBA you have an explicit interface to re-write the implementation on the opposite side. So in REST, if Pi changes, someone has to communicate to the other side (pick your method: email, blog, telephone, SMS...) what has changed."
Last I checked, Yahoo!, Google, or Amazon do not email me whenever they change Pi.
" As a matter of fact, thinking that any uniform interface is going to do the job is the biggest fallacy of the decade."
You have not demonstrated this beyond a bunch of hand waving that somehow "action oriented interfaces" are going to enable evolvability. I don't see it happening very often in practice. We'll see when your article comes out, but again, I caution against writing an article that is based on a strawman of your own design.
- Guy, this is no heresy, this is a fact and you know, facts are stubborn: our world is made up of actions, it is not "uniform".
This is not a fact, it is your opinion. This is sort of like saying "the world is not made up of objects" or "functions" or any of the many abstractions & constraints we choose to model our information systems. One idea is to take a look at Alexander Galloway's book _Protocol_ (if you don't mind philosophy). It talks a lot about the control structure of internetworks and how it is this very uniform control that enables an explosion of diversity at higher levels.
- "Eliminating Pi and Ci is the worst architectural choice you can make. It means a) your implementation is directly wired at the Pe and Ce levels and b) you constantly rewrite application semantics protocols on top of this uniform interface"
:Shrug:. I think the best bang for the buck is to lower the barrier to change for consumers by completely decoupling Pi and Ci from their external representaitons. You want to lower the barrier to change for producers by tying Pe and Ce more to Pi and Ci.
Example: You want to enable people to buy books from you. Do you
a) expose your API with WSDL?
b) conform to what clients already understand and build a set of uniform resources (like a website)?
(b) arguably requires more thought than (a) but has been more successful in practice. And there are plenty of web frameworks that are closing the gap with how productive it is to expose resources.
Your argument seems to reflect to a desire to make external representations align to the programmer's reality as much as possible, instead of designing the external interface to induce properties for the overall system. That's contrary to good architecture, especially "collaborative systems" architecture, as Rechtin & Maier would call it, where there is no overall owner or controlling entity.
One could argue, that the enterprise isn't like this -- it has a controlling entity (the CIO, or whatever). Except most enterprises that I've seen are decentralized messes, run with a Feudal governance model, or a Federal (i.e. politicized) model. But, it is not centralization vs. decentralization that matters, it is the balance of power. Thus I believe most large organizations could use with a dose of uniformity baked into their systems architecture -- it will help them gain quite a bit of traction in maintaining that balance.
- "XML, XSD, WSDL, SCA, BEPL, WS-CDL (and ebBP), WS-TX(and WS-CAF), WS-Security, WS-Eventing"
Half of these are not implemented widely. WS-Eventing and CDL probably will never be. SCA, I continue to note, is an implementation-level technology and doesn't enhance interoperability at the Ce / Pe level in any way. They help link Ci / Pi to the external representation, and frankly I could see an SCA binding for RESTful interfaces, though I think there would be gaps for dealing with link traversal.
- "They will understand that they have a lot of work to do, very hard work (not just to establish a robust communication infrastructure), to come even close to what WS-* has to offer today (not tomorrow, not in ten years)."
WS-* doesn't offer half of what you seem to claim it does today. Yes, it's a useful stack, yes it has some benefits, but reuse and loose coupling are not part of them.
- "(Stu I will also respond on choreography -I am not caught up on choreography, choreography is just another way to express Pe and Ce in a single artifact. It also adds some sequencing of operation compared to WSDL alone)."
WSDL alone does not specify much about the semantics or constraints on interactions beyond MEPs and expected data types. Ordering constraints are fundamental! In WSDL today, you understand them by reading a human language document! We're back to this fiction that somehow WS-* provides you a machine-readable contract. It doesn't. It gives you tiny slices of it to help generate code or activate your security or messaging subsystem, but the rest is an exercise for the reader.
Anyway, I think I'm finished debating you for a while. Please don't take this as implicit support for the ideas I have not directly addressed. You are on the right track in some ways, and very far away off in others. I look forward to your article -- if you'd like feedback on a draft, I am willing to look at it purely to ensure there are no major strawmen :-)
In any case, off to a New Years party. Happy new year!
December 19, 2007
SimpleDB simply sucks
I mean, I really like the idea of Amazon's SimpleDB. Auto-indexing is great. Scalable is great. The price is great. Forget that their REST API is a joke that will have to change as soon as people start losing or corrupting their data. Why the fuck are they throwing out relational theory? The database barely even supports 1st normal form! You can't do any kind of aggregate operation -- no count, min, max, avg, grouping! There are no integrity constraints anywhere!
Take a look at the example they give:
| ID | Category | Subcat. | Name | Color | Size | Make | Model |
|---|---|---|---|---|---|---|---|
| Item_01 | Clothes | Sweater | Cathair Sweater | Siamese | Small, Medium, Large | ||
| Item_02 | Clothes | Pants | Designer Jeans | Paisley Acid Wash | 30x32, 32x32, 32x34 | ||
| Item_03 | Clothes | Pants | Sweatpants | Blue, Yellow, Pink | Large | ||
| Item_04 | Car Parts | Engine | Turbos | Audi | S4 | ||
| Item_05 | Car Parts | Emissions | 02 Sensor | Audi | S4 | ||
| Item_06 | Motorcycle Parts | Bodywork | Fender Eliminator | Blue | Yamaha | R1 | |
| Item_07 | Motorcycle Parts, Clothing | Clothing | Leather Pants | Small, Medium, Large | Black |
Let's ignore that item_07 has the Color & Size backwards. You'll note that Color and Size are multi-valued attributes. If you look up Multi-Valued Attributes in any relational textbook, they'll usually say something like: "Abandon all hope, ye who enter here."
Lately, however, even the diehards are allowing for nested relations & complex types inside domains, so this in and of itself isn't a bad thing if you treat them as nested relations. With that interpretation, this table is intended to manage "names & options for a particular item". It is interpretable in (at least) 1NF. I can retrieve "item_01", for example, I know that this Cathair Sweater comes in Siamese and Small, Medium, and Large.
But, the danger is if you treat this as a table for, oh, say, ordering items! One needs to know if this is a Small or a Large sweater. The only way to get to 1NF is to treat {ID, Color, Size} as a compound primary key. All of your multi-valued attributes become implicitly a part of your primary key! But there are no integrity constraints, so you better make sure your code and gateway API understands that in the above ITEMs table the primary key for item_01 through item_03 and item_06 through item_07 is {ID, Color, Size} and for item_04 & item_05 it is just {ID} -- for now!
So, while it is possible to treat SimpleDB with some level of logic, beware that it's not necessarily designed to be logical.
I also am looking forward to the nightly SimpleDB extracts to MS Excel or SQLite, or Oracle or MySQL so I can, you know, query my data for trends & business analysis. On the bright side, maybe this is Amazon's way of convincing you to build your data warehouse early.
A rant, followed by RESTful choreography
This entry is a response to this entry from JJ. The first part of this is a rant of frustration. The second part is a discussion about the use for choreography in RESTful services.
[RANT]
"These were the only two people that had the courage to go to the end of the discussion even though they saw some limitations to the REST approach. Others, have stopped all communication as soon as they understood the problems with REST."JJ, I hope might occur to you that people in the REST community do have their own priorities, and answering your pages & pages of debate is not necessarily one of them. I'd personally like to take the time to get into this in detail, but time has been scarce leading up to the holidays.
Secondly, you have not exactly been providing a lot of incentives to participate. You have consistently put words in the community's mouth, you have made outlandish and derogatory claims about the future of REST, made erroneous assumptions as to the motivations of the community, and have questioned the level of knowledge & competency in the community. Yet you expect people to actually give you the time of day.
In short, I believe you are acting like a bully, someone who challenges all to a duel, but claims victory before anyone has the energy & time to go several rounds with you. I don't think many are that interested in trying to prove their architecture "street cred" with you, they really just want to build better network-based software.
Thirdly, it feels as if there is no way to actually have a fruitful conversation with you via your blog because it seems you're not trying to understand how REST might fit into your set of priorities. You seem to be primarily trying to poke holes in it and ultimately try to limit its potential audience in the enterprise. That in and of itself is a good thing, but when you are tearing down strawmen of your own making, it becomes very difficult to communicate.
Most debate rounds so far have resulted in you flooding your blog with observations that are either misrepresentations of REST (redefining terms as you see fit, denying explanations that are spelled out in Roy's thesis, etc.) or are orthogonal to REST (even if interesting & worthy of discussion!). You seem to continue to claim that when REST doesn't somehow auto-magically fix a particular problem, it is a reason to ignore/discard/mock it as a failed architectural style, and to deride the community as a bunch of loons. It's extremely discouraging to have a debate when you continue to flout common courtesy in this way.
Obviously we'd like someone like you to understand where we're coming from, and many of us would like to understand your concerns -- but there's only so much time in the day. Please be patient.
[/RANT]
Having said this, I haven't exactly given up, and hope to have more time to discuss some of your observations. Here are a couple of responses to your latest entry:
"The fact and the matter is that you CANNOT DO WITHOUT A CONTRACT to establish the shared understanding."
This has been the core argument I've seen you make, and I agree with it, but I think WS-* vs. REST is irrelevant here, as they address different concerns. So I think it's time we looked at doing this problem in detail. I do not believe that the WS-* stack gives you any such thing today, and mainstream WS-*, as it currently is led, is not heading in any clear direction to support this. WS-CDL, SCA, and WS-Policy will not get you there, not even 15% of the way, and probably will make life worse.
Today, in WS-* land, a contract is described by human-readable documentation, with certain degenerate yes/no policies described by WS-Policy. WSDL does not give anyone a shared understanding; at best, it is a template to generate code. A developer has to read the documentation that goes with the interface to know ordering constraints, non functional SLAs, any guards, preconds, postconds, etc. WS-CDL is not mainstream and is likely not an option (will discuss below).
SCA is not a pervasive solution to this because it is just an implementation-level container & component composition model -- it's a multi-language (but still Java-centric) alternative to the J2EE deployment model and EJB. It will not be adopted by Microsoft. And it doesn't (yet) help to specify contractual constraints any more than the WS* specs do.
Now, in REST, today, the contract is defined by the transfer protocol, the media type (which is usually a human readable spec), and perhaps an independent contract addendum to talk about specific ordering constraints (though forms & link traversal provide this information too), SLAs, etc. But in REST, just like in WS-*, there is no reasonable way to create a machine-readable shared contract of interactions & expectations.
So far, I would claim the difference is that due to the uniformity constraint, RESTful services naturally have a lot more loose coupling between service implementations than if we defined our own semantic community for service interfaces that include actions unique to a particular business domain. The data transfer protocol should not have to deal with business-semantics!
I *think* that what you're getting at is that you need a choreography language to truly build a shared understanding at a business-action level. If so, I agree! And I think this actually would be *great* for both REST and WS-* if the mainstream would embrace it.
In a RESTful choreography, all interactions, units of work, etc. should boil down into some kind of primitive uniform interface that everyone understands.
So, one might wonder -- what about WS-CDL? Sadly, WS-CDL has a number of problems:
- It doesn't seem to be generating a lot of popularity,
- It has some notable issues so far, mainly because it was blazing new trails way ahead of its time in a committee venue that's not built for such innovation;
- it embraced WSA without giving any love to Webarch, to its detriment;
- it also doesn't have a compact syntax, so many early adopters, especially those that don't like GUI modeling tools, aren't going to touch it.
But it serves as a model to improve on and a set of invaluable lessons.
A choreography language to describe RESTful interactions is absolutely doable, in my opinion.
To me, RESTful choreography would actually fix one of the bigger problems with WS-CDL today: it tightly binds the choreography to a particular WSDL and set of XML namespaces. Yet, a choreography arguably should be reusable across a variety of operation-level interfaces and/or schema documents. Furthermore, a set of services may participate in a variety of choreographies, particularly if we want any sort of reuse.
In short, the WSA way to improve WS-CDL so that it is more "reusable" would be to provide some kind of indirection between WSDL and the choreography and role descriptions.
The Webarch way would be to eliminate variation in the primitive bindings available in any ground choreography, and enforce uniformity. Hyperlinking would also provide a much easier time of managing tokens, identity references and channel references, I think.
"The fact and the matter is that a Result Set IS-NOT a resource"
Sez you.
A result set absolutely can be a resource: when I go to Google and get back a page search results, that's a resource (it has a URI, after all). Anything with identity, no matter how transient or persistent, is, by definition, a resource.
"For those of you who are not convinced yet, I suggest that tomorrow you try to drive your car with a (GET,PUT) interface (no links allowed) and then you tell me how you felt: : a state machine is a state machine and there is no way around it"
This is an absurd strawman. If you have no links, you're not doing REST, sorry. I have no idea what you're trying to prove by suggesting one can't drive a car via hypermedia.... what would the benefit be even if we tried?
"It has been notorious that REST is really bad at versioning (I am preparing an article on this topic that will be published early January)..... Have you tried to bake in versioning in a RESTful resource access? you mean that the URI of the resource depends of the version? Ouch..."
It has only been notorious in your own mind. I caution against writing an article based on a strawman of your own making.
Versioning information is usually included in representation state, not in the URI. There are times where you may want a new resource altogether, but that depends on the extent of the change and whatever backwards compatibility policy you are following.
"The second detail they missed is that Amazon is probably going to publish BigDB at some point and maybe they will want to develop a true CRUD, SQL based API. Have you ever tried to implement this kind of API in a RESTful way? huh? you mean you can't?"
This is the kind of "putting words in people's mouth" I ranted about above.
No one is claiming that REST is the only type of architectural style that's appropriate. Remote Data Access styles like SQL gateways are very useful. Just don't expect millions of diverse users to hit your SQL service with good scalability, reliability, and visibility! I mean, even in component-oriented SOA one tends not to expose a generic SQL endpoint except in scenarios where a generic interface for a relatively small audience is required.
The points against Amazon are that they're claiming that SimpleDB has a "REST API", but they are making a mockery of the term. Their implementation is running *against* the way the web is supposed to work, and means that no pre-fetching user agents or intermediaries can safely be used with SimpleDB as they may be a source of data integrity problems. This has nothing to do with religion, it's about Amazon's REST API author being completely oblivious to 15 year old architecture and recent history like the Google Web Accelerator.
November 13, 2007
To see what is in front of one's nose requires a constant struggle
Monsieur Dubray has posted nearly 5 blog entries critical about REST.
Almost everything Mr. Dubray claims "you're on your own" with REST is either a tremendous misunderstanding, an emotionally projected argument, confuses implementation technologies with protocol-based interoperability (e.g. SCA and SDO are jokes until it binds to the Microsoft stack, JJ), or it is in area where you're equally on your own with WS-*.
Contracts? WSDL is not a contract. XSD is not a contract. WS-Policy neither. They're interface descriptions. True contracts? You're on your own. By the way, REST relies on *very clear* contracts, as clear as anything in a well designed SOA. The difference is in how the architecture determines & applies them.
Versioning? XSD is notoriously flawed in this regard (though they're working on it). And there is more than that -- SLAs (no standard), security (WS-SecurityPolicy covers only some use cases), etc. You're on your own.
I had begun writing a point-by-point debunking, but, life's too short, and I'm busy enjoying Cancun at the moment. No one denies there's a lot of work to do in applying REST (or successor styles) to enterprise work, but that doesn't mean we shouldn't try. JJ, if you would like to have a reasonable conversation about this, let us know, otherwise please keep insulting us, any press is good press. ;-)
REST as a style in support of enterprise SOA is like XML, circa its release in 1997 -- great promise without a lot of satellite specs & infrastructure supporting it (in security, for example, though this is probably going to be fixed next).
WS-* is where CORBA was circa 1997: it will be used to implement some good systems, but there will also be some high profile failures. A number of the specs will likely never be adopted by the mainstream (see WS-CDL, WS-Eventing), though some will definitely improve some ridiculous vendor interoperability disputes (e.g. WS-TX, WS-RM). Plenty of pundits (now bloggers) sing of its imminent triumph (channelling Orfali, Harkey and Edwards), but overall, the framework will not help solve the problem that was used to sell its adoption in the first place: increased agility, reuse, and visibility in IT. I think many WS-* tools actively *hinder* an SOA architect from achieving these goals.
November 10, 2007
RESTful normalization
Why is RESTful design thought to be hard? I said this during Sanjiva's talk at QCon, but here's my one line summary
RESTful design is like relational data normalization.
Even though both are driven by principles, both are an art, not a science. And the popular alternatives, unfortunately, tend to be driven by craft and expediency.
The analogy could be taken further: "good RESTful designs" today, of the WADL variety, are very similar to 1NF. With ROA and the "connectedness principle", we're just starting to move into 2NF territory, I think.
Witty aporisms abound: "The Key, the Whole Key, and Nothing but the Key, So Help me Codd" sounds a lot like "Cool URIs Don't Change".
We haven't quite yet found the RESTful 3rd Normal Form "Sweet Spot".
"Everyone knows that no one goes beyond 3NF", so perhaps RDF and the Semantic Web are REST's 6th Normal Form, because they "scare people". Amusingly, Chris Date actually seems to think so.
I just *really* hope we don't have to go through 20+ years of defending REST the way Codd & Date had to defend the relational model against unprincipled alternatives, a debate that continues to some degree almost 40 years after Codd's original paper. If, in 2037, we're still debating the merits of Roy's thesis, I'd rather be a bartender...
November 09, 2007
QCon San Francisco, Day 2, thoughts
The REST track, hosted by Stefan, was great fun -- Floyd mentioned to me that the track in London wasn't so packed, but the room in San Fran was standing-room only for some of the talks. Stefan has rough notes of most of the proceedings on his site, so here are my reflections.
Steve Vinoski's talk was a good introduction to the crowd on REST's constraints and the desirable properties brought out of those constraints. "SOA Guy" brought out common counter-arguments from the SOA architect's position. A favorite point: SOA does not stand for "Special Object Annotations" :-) I also learned that we share a love of Mountain Dew (sadly decaffeinated in Canada, though).
One question from the crowd was: Isn't REST just pushing the interoperability protocol to the data type, not solving the interoperability problem? Here's my take: application protocols are about expectation management. Even though it's generic, the HTTP methods + metadata + response codes provide a wide range of signs, signals, and expectations for communication. So, while it's not aligned to what you're doing specifically, it means that we can discover & communicate, generically, almost any piece of information -- a very valuable form of interoperability.
This does not, of course, solve the the data (MIME) type tower of babel. That's the next battle. There is a tradeoff between intertwingling syntax and semantics. Doing so, like with XML Schema and its ilk, is easier for programmers, but harder to interoperate if the domain is business-biased. There's more potential for disagreement when designing a data format for an industry than for some general-purpose infrastructure. On the other hand, using a generic syntax, whether Microformat-based XHTML, is a bit harder to program with, requiring tools support, but arguably could lead to better interoperability. And, taking this progression further, a completely generic logical data format, like RDF/XML, is even harder to program for, but once the tools exist (similar to SQL query engines), the potential is vast.
A more few reflections. Why do people misunderstand REST? For example, REST and WOA are about anarchy & avoiding standardization according to this gentleman. Who are these WOA people he speaks of? This strikes me as a projected argument, something that's derived from the emotional reaction of "I'm afraid you are saying X", when the Other isn't actually saying X. It reminds me of the early days of Extreme Programming, where pundits claimed "Egads, XPers say you should not design your software!"
Another example, is "You REST people think it will take everything over and be the only architecture!" Which is again, an emotionally projected argument, something I don't think anyone is actually saying. The points are that effective architecture at scale requires emergent properties to be induced through constraints, and that networked hypermedia might be a shift in thinking in the way that objects were a shift, and deserves attention. (Apparently we're in the mid-70's Smalltalk phase of that revolution, however. :-)
There are two common angles where I think people miss the point of REST here:
- When people don't believe there's such a thing as emergence;
- When people don't get/remember or relate solid software engineering principles to their distributed systems. In particular: interface segregation, and stable dependencies and abstractions. REST is really just a pattern that takes those principles seriously for a collaborative information system.
On to the further talks....
Sanvija's talk brought out the most useful debate of the day -- there's so much more dialogue that could (and SHOULD) happen on every one of those slides, to absorb where we misunderstand each other. Stefan's blog entry captures a lot of my questions and comments that I made during this session; afterwards I thanked Sanjiva for putting up with me. ;-) Hopefully this one will be posted in InfoQ.com sooner rather than later, it was a fun time.
Pete Lacey went through demonstrating the 'ilities' of REST, where he discussed the constraints and properties in more detail and, in code showed an XHTML-based (but also Atom and plain XML representation-based) REST API for an expense reporting system. He proceeded to show integration via a Microformat browser, curl, ruby, Microsoft Excel, and Word.
This sort of demo is very important, as it's the only way I think people will begin to get what serendipitous reuse is about. Not everything is encoded in a managed business process -- Microsoft Office still glues a vast amount of business activity together!
Dan Diephouse discussed building services with the Atom Publishing Protocol. I enjoyed this: it was hands on, code-oriented, and wasn't just a love-in: we spoke equally of the benefits and current open challenges with this approach to publishing data on the web.
And, though I met him at lunch, I unfortunately missed Jim Webber's final talk of the track day, due to some work commitments! Hopefully I'll catch the video when it's posted on InfoQ.
QCon San Francisco, Day 1, thoughts
Kent Beck gave the first keynote speech at QCon, which was a good talk on the trend towards honest relationships, transparency, and sustainable commitments in software development: the "agile way" is aligned with the broader business trends like Sarbanes-Oxley, greater transparency, board and management accountability, etc.. He claimed during the keynote (I'm paraphrasing):
"Agility is an attitude regarding one's response to change."
I asked him the following two part question:
"There seem to be two trends in industry -- the Agile methods movement, which is about Agility as an attitude, and the Agile architectures movement, which is about introducing enterprise-level and "systems of systems" level architectures that help to enable greater agility. The questions are:
1. Do you believe architecture actually can enable greater agility? Regardless of what religious school you belong to, SOA, REST, Data Warehousing, etc.
2. How do Agile teams, with the attitude, build productive relationships with Enterprise Architecture teams, whose goals and attitudes often are at odds with the executing team?"
Kent's Answer for #1 (paraphrasing): "I've always believed that design matters, from the smallest implementation detail, to the largest architectural arrangement of software. Design can enhance communication."
Kent's Answer for #2 (paraphrasing again): "It can be a hard thing, but it's important to recognize that the EA saying 'you can't code without our approval', and the developer having to wait three months, doesn't have to be about a power struggle. There are two different principles and values at play here, both attempting to get to agility. The goal must be to get past the noise of the specifics like 'you need to build things this way' and find a shared understanding of the principles that underlie such decisions. If I, as an Agile team leader, believe in principles like the time value of money, or in the lean principle of flow, I'm going to try my best to ensure that there is a shared understanding of their impacts. Similarly I would hope to understand the principles that underly the EA's decisions and policies. It's the only way to get past the politics."
Richard Gabriel, always thought provoking, gave two talks that I attended. The first was:
"Architectures of extraordinarily large, self-sustaining systems"
So, assuming a system that was trillions of lines of code, millions of elements, thousands of stakeholders, beyond human comprehension, and must provide advantages over an adversary, how would you design such a system?
Firstly, a reflection on the requirements. The "gaining advantages over an adversary" part of this description seems to be similar to the Net Centric Warfare (NCW) movement -- it's very Strategy as Competition oriented, I'm not sure I agree it's the right frame of mind for thinking of this sort of thing, but it probably belies who is funding the effort. Lately I have noticed that NCW is becoming more and more "Web-like" and less "SOA-like". The publication, Power to the Edge, a revised treatise on NCW concepts, really screams out "Web!", or at least some successor to it. Strassmann more or less predicted this in the early 90's while he was running the DoD, and correctly surmised that it's political and human comprehension that's holding up the transition.
Back to the talk. Dick Gabriel explored three approaches to design:
- inverse modeling is tractable -- meaning, we can work out the design of the system top-down, and in advance
- inverse modeling is intractable -- meaning, stepwise refinement (ala. 'agile design')
- evolutionary design -- wherein we use evolutionary techniques, such as genetic algorithms, to "grow" a solution. The design is indistinguishable from the implementation this case.
On #3, he pointed to Adrian Thompson's work on Evolutionary Electronics. This was some of the creepiest, coolest, and most bizarre results one could imagine: Adrian literally "grew" a 10x10 section of an FPGA, using genetic algorithms, to solve a simple tone discrimination task. It executes the task flawlessly. The problem is, they don't actually know how it all works! See the paper here.
Reflection: I was surprised he did not speak about the work on "collaborative systems" or "systems of systems" by Mark Maier (of IEEE 1471-2000 fame) and Eberhardt Rechtin. This approach fits in with Roy Fielding's REST dissertation on the beginnings of an architecture science: inducing emergent properties on a system by way of constraints. I was going to speak with him about it, but he was mobbed by several attendees at the end, and figured I'd get my chance some other day....
Dick noted that "the Internet" as a whole isn't really an "ultra large scale system" that he's looking at because it doesn't have a directed purpose. This is curious -- the Web, an application of the internet, had a goal: increase the sharing information of any type, globally, exploiting Reed's law.
The Web doesn't have an adversary though... does it? Hmmm, maybe it does.
Dick's second talk was a repeat of his OOPSLA presentation 50 in 50, a whirlwind tour of many programming languages over the past 50 years, accompanied by music. This presentation is available via OOPSLA podcast, and while it doesn't quite work without the visuals, I recommend it if you're interested in how much creativity there has been out there (and how, we're only starting to regain some of that creativity now after 10+ years of JavaJavaJava). Hopefully the slides will be eventually made available as a Quicktime...
October 26, 2007
But sometimes things do change
"So after the show, the SOA advocates shuffled off to meet with Michael and I for a spot of coffee and confrontation.... During a relaxed and wide ranging conversation exploring resource oriented versus message based architectures, I suddenly realised, there was no argument anymore. Getting all those silly vendors to agree on something, anything was the battle, but going forward, its obvious the Web has won. All we have to do now is to help those pour souls still trapped in Middleware hell to walk into the light and pass the bovril and blankets. If you know someone still slipping around on the SOAP, dont hate them, just warn them the longer they continue the sillier they look. They deserve your sympathy, not hate. Just give them lots of hugs!"
Thanks, Paul, this made my day.
Hugs, not hate, is the approach I've been taking since mid-2006 within BEA on this topic, with some success, at least in consulting. Though a whole division of BEA figured this out on their own a long while ago.
The more things change...
Technology moves quickly? bah!
From: Stuart Charlton <stuartcharlton@hotmail.com>
Subject: Re: [dist-obj] Was Souls, Now S2S, P2P.. Web Services
Date: February 28, 2001 5:26:53 PM EST (CA)
To: Mark Baker <distobj@acm.org>
Cc: dist-obj@distributedcoalition.org
> Stu!
Mark!
> It looks to me like you're only considering the RPC use of SOAP. SOAP
> is so much more than RPC, but also so much less than a lot of people
> think. For instance, SOAP defines no application semantics. It relies
> on an application protocol to do that, such as HTTP. Almost all of the
> benefit that is attributed to SOAP in the press, is made possible by
> HTTP. In fact, you don't even need SOAP. All it adds is;Yes. I did an "XML messaging without SOAP" project back in September when I
was running the "new hires" training program for a Wall Street bank.We really didn't want to use a CORBA/COM bridge to talk have VB talk to our
Enterprise JavaBeans. Most of the "ease of development" came out of HTTP.
We created a generic-data DTD (simplified XML-Data), and a simple invocation
DTD and would basically call / query our beans using a very thin servlet
that did reflective calls on the beans. We put an IE component inside our
VB application to render our data using XSL.Didn't need SOAP then, don't (really) need it now. :) But it seems to be
the direction everyone's moving in...[snip]
Cheers
Stu
October 22, 2007
The Web: Distributed Objects Realized!
Here are the slides from me and Mark Baker's half-day OOPSLA tutorial.
It's a slightly different twist on the "why and when is REST useful?" question.
Here's a motivating paper we also wrote -- it's on GooDocs but I've provided a local link for now.
October 18, 2007
On Chaos in IT
...in part Stefan has a good point, namely that IT systems currently suck. But where I'd disagree is that the goal of IT should be to create such a chaotic system with so little governance and control. This is one challenge I have when people talk about applying Web principles to the enterprise, it misses out on a fundamental difference between businesses and the internet. Namely that of compulsion.
I think the point is that the Web is an architecture of participation, wherein we set up constraints to enable value by converging on a small number of strong rules, even if you diverge in many other aspects. And even in businesses, people disagree on issues, but still need to work together.
People have often referred enterprise architecture as "city planning", primarily because the business does not speak with one voice -- it is very typically decentralized. Weill & Ross' excellent book IT Governance discusses the variety of governance styles, and very few are "Monarchy" or "Duopoly", wherein the compulsory standards will be likely adhered to. "Feudal" seems to be the dysfunctional norm, where each profit center doing what it wants, and "Federal" as an acceptable, if politicized, alternative.
The other note, similar to what John Hagel & John Seeley Brown have been saying, channeling Drucker, is that the borders of the enterprise are dissolving, and interaction is occurring outside of its walls at an increasing rate. Why adopt an architecture that is inwardly focused, when all results, most opportunities, and threats are on the outside of the legal fiction of the organization?
I guess the core question is whether the large organization *fundamentally* tends towards convergence or divergence in nature. If it's divergent, you're rarely going to get broad compulsory agreement on many domains of value, and even when you do, you need to invest heavily to maintain that agreement.
The alternative is to adopt a collaborative agreement, wherein the participants have incentives to join, and the benefits are emergent. With the web, the assumed incentive is exchanging and transforming an ever increasing amount of wildly diverse information.
Of course this is not the end of history, but I think it's a step towards better IT.
October 16, 2007
Rechtin
A paraphrase from the late, great, Eberhardt Rechtin:
"Most architectures are the products of deliberate and centrally controlled development efforts. There was an identifiable client or customer (singular or plural), clearly identifiable builders, and users. The role of the architect existed, even if it was hard to trace to a particular individual or organization. The system was the result of a deliberate value judgment by the client and existed under the control of the client.However , many systems are not under central control, either in their conception, their development, or their operation. The Internet is the canonical example, but many others exist, including electrical power systems, multinational defense systems, joint military operations, and intelligent transportation systems. These systems are all collaborative in the sense that they are assembled and operate through the voluntary choices of the participants, not through the dictates of an individual client. These systems are built and operated only through a collaborative process."
"In a collaborative system, the greatest leverage in system architecting is at the interfaces. The greatest dangers are also at the interfaces. When the components of a system are highly independent, operationally and managerially, the architecture of the system IS the interfaces. The architect is trying to create emergent capability. The emergent capability is the whole point of the system; but, the architect may only be able to influence the interfaces among the nearly independent parts. The components are outside the scope of and control of the architect of the whole."
"Virtual collaborative systems lack both a central management authority and centrally agreed-upon purposes. Large-scale behavior emerges, and may be desirable, but the overall system must rely upon relatively invisable mechanisms to maintain it."
"The Web is even more [of a distributed collaborative system] than the Internet in that no agency ever exerted direct central control, except at the earliest stages. Control has been exerted only through the publication of standards for resource naming, navigation, and document structure. Although essentially just by social agreement, major decisions about Web architecture filter through very few people. Web sites choose to obey the standards or not, at their own discretion. The system is controlled by the forces that make cooperation and compliance to the core standards desirable. The standards do not evolve in a controlled way, rather they emerge from the market success of various innovators. Moreover the purposes the system fulfills are dynamic and change at the whim of the users."
"A collaboration is a network good; the more of it there is the better. Minimize entrance costs and provide clear conformance criteria."
October 11, 2007
Planned vs. Seredipitous Reuse
One problem with SOA is that it is very "heavy", with a partial focus, like CBD before it, on planned reuse.
In some industries, planned "product line" reuse has been shown to work, such as with car platforms. It's also appropriate for very general purpose programming libraries, etc., and could also be appropriate in software (there's a fair amount of "software product lines" literature out there).
From this viewpoint, "build it and maybe people will use it later" is a bad thing. SOA proponents really dislike this approach, where one exposes thousands of services in hopes of serendipity -- because it never actually happens.
Yet, on the Web, we do this all the time. The Web architecture is all about serendipity, and letting a thousand information flowers bloom, regardless of whether it serves some greater, over arching, aligned need. We expose resources based on use, but the constraints on the architecture enables reuse without planning. Serendipity seems to result from good linking habits, stable URIs, a clear indication of the meaning of a particular resource, and good search algorithms to harvest & rank this meaning.
This difference is one major hurdle to overcome if we are to unify these two important schools of thought, and build better information systems out of it.
October 04, 2007
Zimbra
I missed this a few weeks back... Zimbra was acquired by Yahoo!. Zimbra's CTO, Scott Dietzen, was BEA's former CTO.
This is great news for a great company. I can only hope this will make their technology more mainstream. We need competitors to Exchange & Outlook, dammit.
Dynamo
A detailed technical paper on Amazon's advanced key-value storage system. A great practical example of the CAP theorem in action, wherein we sacrifice some consistency for greater availability and partition tolerance.
on ESBs and disposable software
Another Dev2Dev blog post, which I should use more often when the word "BEA" appears here...
On effective architecture
Sometimes we keep talking past each other in these debates about architecture.... SJ claims that REST isn't an architectural style after all, but rather a design pattern. And in the comments, client-server isn't a style either.
Well I've been known to use "architectural pattern" as a synonym for style, in that it is a set of interactions and/or constraints that provide particular benefits. But it's not about implementation mechanics.
IF we want to play the definition game, I would not trust Wikipedia. Here's Clements, Bass, Kazman, and Northrop -- pretty reputable people in the software field -- describing architectures & styles, in p25 of their book:
For example, client-server is a common architectural pattern. Client and server are two element types, and their coordination is described in terms of the protocol that the server uses to communicate with each of its clients. Use of the term client-server implies only that multiple clients exist; the clients themselves are not identified, and there is no discussion of what functionality, other than implementation of the protocols, has been assigned to any of the clients or to the server. Countless archtiectures are of the client-server pattern... but they are different from each other.An architectural pattern is not an architecture, then, but it still conveys a useful image of the system -- it imposes useful constraints on the architecture, and in turn, on the system....
...Choosing an architectural pattern is often the architect's first major design choice. The term architectural style has also been widely used to describe the same concept.
This sort of thing applies to other fields. In organizational design, we also have a number of patterns with a variety of benefits: functional, geographic, matrix, customer segmented, etc.
This got me thinking about a talk I gave at BEA's Worldwide SOA Practice Meeting in Boston last week. It was about "alignment vs. effectiveness" in architecture, and dealt directly with this topic. The MIT Sloan article Avoiding the Alignment Trap in IT was the inspiration, along with elements of Roy's recent presentation. The reaction was very positive, but a few didn't get it (though admittedly I plowed through the preso in 1 hour) or didn't agree (though they didn't say why).
Anyway, here's the story:
SOA is a way of describing architecture. I am not talking about Business Services Architecture here, which strikes me as an attempt of rejigging organizational design theory with technology concepts -- something that seems valuable but still lacks clarity.
I'm talking about describing arrangement of software. With SOA, instead of describing an architecture in terms of components, connectors, data elements, etc., I describe it in terms of interfaces, implementations, and contracts, which includes descriptions all of the data elements.
And here is where I believe the disconnect lies: SOA principles have everything to do with alignment of IT assets with the organization. And for good reason: we've often ignored business needs in favour of technical justifications, and SOA is more about a framework for thinking about "what to deploy where" -- alignment -- then helping you to arrange the interactions in an effective way. The problem is, that we seem to have forgotten about effectiveness!
For example, REST doesn't tell you how to build a web site. It doesn't tell you what should link to what, why, and when. That's what a lot of the SOA work has been about: of your candidate services, which should be deployed, and where, and how do their contracts interrelate? On the other hand, if your business requirements need a certain level of scale, interoperability, etc., then a RESTful style would be a class of SOA that would be very beneficial to your problem.
See, effectiveness, which is how well an architecture will perform in practice, given the constraints & properties you apply to it, is where the many years of a systems architect's experience comes in. This is an understanding of how certain interactions have certain tradeoffs associated with them.
Another view of the problem: SOA folks often suffer from an ailment I call "producer-itis", meaning that they focus from the service producer's vantage point. The consumer's vantage point -- those that will actually use the services, whether humans or other services -- is often secondary. Now, think tanks such as ZapThink and CBDI have long advocated "twin track analysis", where producer and consumer considerations are both taken into account, and indeed, this might be the biggest drive for SOA in the first place! But many SOA analysts have embedded the "WSDL metamodel" into their brain, which is of the "if you build it they will come" variety of architecture -- I deploy an interface, I register it, you use it. Ignoring that the classes of consumers are likely to be way more heterogeneous and large scale than the producers, if your SOA initiative is successful. ;-)
The business requirements, for example, may require a particular interaction pattern (or "message exchange pattern", ugh) between services today, but that says nothing about the properties I gain or lose from such an exchange. Or what happens when the business changes. With SOA, we seem to have devolved in to describing architecture as a passive observer writing down observational behaviour for a contract, instead of influencing interactions based on how effective they will be in practice.
Without appropriate application of architectural styles, we risk becoming fully aligned, but unable to get anything done -- the alignment trap.
This isn't implementation to me. This seems to be about two schools of thought on form - one that contorts itself to remain aligned to the business, and one that understands, at a more abstract level, the nature and tradeoffs of interactions between elements. I think they're both relevant, but clearly we seem to talk past each other because they represent different value systems.
September 27, 2007
The next programming language
The latest fad seems to be picking the "next great programming language" that will take advantage of multi-core processors, fit the web's architecture well ,but still be general purpose enough to process traditional tasks such as file I/O.
Erlang seems to be the "new new thing" that people are buzzing about.
Here's my guess: Golog. Specifically, some future variant of IndiGolog. This is based on personal research, and since I doubt anyone actually will take it seriously, I'm not going to really say much about it other than it is the most exciting thing I've seen in programming, data management, and integration since, well, I owned my first Commodore 64.
August 27, 2007
What's it about?
In recent technology trends, such as SOA, or EA, or "Social Computing", I often observe crusaders that want so badly to accomplish something useful under the umbrella of investment, hype, and energy surrounding their selected trend that they try very hard to make the idea as "abstract as possible". They do this so the trend doesn't melt away as soon as the underpinning technology proves itself fatally flawed.
"It's not about the technology" is the byline of such approaches.
Recently I read an entry by Andrew McAfee that crystalized what has always annoyed me about this phrase over the years.
"Sometimes, at least in part, it is about the technology."
July 26, 2007
Semiotics and REST
I think the biggest confusion about REST is that it's not a protocol, it's a way to think about extremely big information systems. To compare prior models with REST, one has to think about the problem of information management & manipulation in network.
Traditionally, distributed systems saw data as globally consistent -- one used two-phase commit to ensure this consistency.
However, many organizations have applications with "copies" of data, or with their own independent database, and use replication or messaging to enable a level of partial consistency. With this approach, one can view the network as having "autonomous" services, each with its own independent view of information. The latter is more common in practice in most enterprises, it's the most scalable, and is also the view that SOA tends to take.
One of my favorite discussions of the implications of an "autonomous" model of information management is from Pat Helland. This idea, one I blogged about way back in late 2003, is a separation between "data on the outside" vs. "data on the inside", which he discussed at the Microsoft PDC and also captured in this article. "Data on the inside" is service-private data. No one can see it except the service itself, it is encapsulated. "Data on the outside" includes messages & reference data (where messages typically are the means of conveying reference data).
In this approach, information may be represented differently between service boundaries (e.g. Inside, with an RDBMS, for example, and outside, with an XML document).
But, here is the key point: there is a shared meaning, or concept behind both representations of the data, and the service implicitly has a 3-way "mapping" between the inside representation, the conceptual meaning of the information, and the outside representation.
This three-way relationship is also known as a semiotic relationship: between the symbol, an object, and the concept. Without this relationship, it's very hard to communicate ideas whose substance evolves over time with any precision or integrity, and arguably it's one of the cornerstones of information management theory.
To contrast the two models of REST and SOA:
In SOA, this "conceptual mapping" is implicit in the service boundary. Many such mappings may be conveyed through a service boundary. They are always there, but are usually tacit, or encoded in an application-specific manner.
In REST, this semiotic "mapping" between an information concept, the inside of a service & the data represented outside a service, is called a resource. And each resource is given one or more unique identifiers in a uniform syntax.
In SOA, the service contract is the key abstraction of an information system. It forces the information system into a model where everything is viewed as a shared agreement between one or more producers & consumer of messages.
In REST, the resource is the KEY abstraction of a global information system. One service = one resource. It forces the whole information system into an application model where all actions are generalized into uniform methods of sign (representation) exchange. And the representations themselves contain uniform links to other resources, ensuring that no out-of-band information is ever required to interact with the system -- connected resources, pulled and manipulated as desired, become the engine of any agent's desired ends.
The caveat:
Using REST for the problem-space that WS-* is intended to solve still requires a lot of work by industry. There aren't enough standards to make this as easy as it could be. Though the publication of Atompub, the burgeoning Microformats effort, etc., we're in a very good state.
The point of these debates, yet again:
To me, it is not that WS-* sucks, or that REST is a faddish religion. It is that vendors are not addressing fundamental problems in the application model that SOA derives from, i.e. a hybrid of component-based development, OO-RPC, and messaging-oriented middleware. It is bound to hit a wall of our own making, as currently practiced.
We've been trying one variant or another of this approach for 15+ years, and only recently have gotten reasonably good at it. We convinced ourselves that XML Infosets would solve the political and usability challenges. But even if we standardize transactions, and security, and reliability in XML infosets, we still do not have a very scalable, interoperable, or loosely coupled model for information systems -- because everyone will still be inventing their own!
The real problem lurking was that we, with SOA, weren't treating information as an asset: a resource that can evolve over time. Even if we knew that these resources existed, and should be managed with care, they were tacitly hidden in our IDL, schemas, and WSDLs, or in a "governance document" of some sort. We weren't enabling a low-barrier to entry to access those resources in our information systems. And we weren't connecting our services together into a web, where discovery was a natural act.
Yet the World Wide Web has effectively nailed a good chunk of these problems. We could re-invent the Web in XML -- but why? Couldn't we use it for its strengths, while integrating the WS-* technologies where they really add value in enhancing (instead of replacing!) the Web?
July 17, 2007
OOPSLA
Mark Baker and I will be giving a half-day tutorial at OOPSLA 2007 this year in Montreal, entitled The Web: Distributed Objects Realized!. It will be a general tutorial on the RESTful web, targeted at practitioners, with a focus more on architecture & design than on implementation. Looking forward to it! Hopefully I'll get a chance to meet a few of you.
July 03, 2007
iPhone and RESTful HTTP
Ok, I'll stop gushing about the iPhone. But one thing I noticed on the developer guide was that the iPhone doesn't use RTSP/RTP for video streaming, but rather HTTP byte-ranges.
This is yet another big reason for servers to support full HTTP 1.1. Hopefully pipelining won't be far behind :-)
Another interesting note is that, as expected, Web / Phone / Email / GMaps integration is purely conducted via hyperlinks, i.e. the tel:, mailto:, or http: schemes. URIs with a "maps.google.com" authority are redirected to Apple's implementation of GMaps. Numbers in text that look like telephone numbers without an explicit anchor are automatically inferred as hyperlinks.
July 02, 2007
iPhone impressions
I managed to snag an iPhone from an AT&T store near the D.C. Area on Friday. Its a gorgeous device , and I've been playing with it constantly all weekend. I typed 3/4 of this entry with it at the Dulles airport lounge. Here are my initial thoughts:
- screen quality and font rendering shine. I can read large blocks of text with ease.
- the keyboard takes getting used to. In portrait mode I find that one finger is sufficient, as thumbs tend to be a bit fat. On landscape mode I am typing as fast, if not faster than my BlackBerry. I remember how it took a while for BB users to learn thumb mastery.. This is similar. I can see it eventually becoming aecons nature. The issue, of course, is touch typers are used to looking at the screen, not the keys. iPhone's predictive text takes advantage of this habit, by highlighting the corrections dynamically. Unfortunately, the prediction isn't so smart while you're learning to type, so its still useful to watch the keys to see which you've hit.
- no cut & paste is annoying, not a deal-breaker (yet), but if they don't fix it I will be grumbly
- I used my phone for around 8 and a half hours yesterday before the battery whined. This was true usage over a 12 hour period, where I took 50 photos with it, played politcal songs on the speaker while outside the White House gates, and surfed on EDGE extremely often
- initial accessories suck- the Case-Mate leather belt holster I bought broke within a day. I returned it.
- No problems seeing the screen in bright sunlight
- weird bugs in Safari -- textboxes don't show scrollbars, and so I can't easily move around the contents and edit a large blog entry, for example. Facebook mostly works, though I can't set status due to the box disappearing immediately. I'm curious how iPhone will affect the whole AJAX thing: it completely destroys the premise that "user will always have a mouse", and makes you rely less on onmouse* events, unless Apple finds better ways to emulate mouse events with the multi-touch.
- AT&T is, well, AT&T... I've found the iPhone allows for a-la-carte international roaming immediately (at least for Canada). Buy I can't activate an international roaming discount plan until Monday since that department is closed on weekends. Normally they make you wait 90 days before allowing you to roam, but can make "exceptions" if you run through another credit check. The paranoia of this industry continues to astound... they must have been defrauded one time too many.
- call quality is great, no issues there
- the video player is made of awesome
- I've rarely used MMS as it didn't work right on my BlackBerry for a long time, so I don't miss it
In all, a good experience that I hope will only improve.
June 27, 2007
I, for one, welcome our new iPhone overlords
I'm flying to D.C. this weekend to visit a friend & try to snag an iPhone. I have a U.S. SSN from a few years ago, and a U.S. address -- hopefully it works out.
Roaming in Canada will be a bit pricey, but between my work use of the phone (which pays for a large chunk of the bill) and my existing Rogers phone, it probably won't be too bad.
One thing I note on the recent reviews is that everyone is discussing the missing features & oversights, but few are discussing the reason why all of this is irrelevant, and why the iPhone really does change the game: it's just software, folks. Apple will issue updates regularly -- that will auto-sync whenever you dock the phone with iTunes.
Sure, they can't fix the fact that EDGE is slow (it's not "ancient", and is pretty good, by the way, in Canada, even in rural Ontario areas, and it's a lot faster than GPRS was). But, cut/copy and paste? Instant messaging? MMS? MP3 ringtones? Surely these were triaged and didn't make the cutoff date. Apple will get there....
June 22, 2007
Afraid?
For months, industry analysts have warned about e-mail access, security and whether the voice quality of the iPhone will be up to corporate standards. Gartner analyst Ken Dulaney is finalizing a report describing iPhone concerns, but would not discuss it until its release next week."Lots of Gartner clients are asking" about iPhone for business uses, Dulaney said. "They are scared of this device."
I read this, and I'm afraid of these businesses. Have we lost all sense of reason and fun? I mean, I get that it takes work & thought to support new devices, but that's the job of an IT department.
The press seems to be drumming up drama here, and I'm not sure the point -- is it to see Apple fail in some way? Is it to point out the flaws in corporate IT's stodginess? Or both?
June 11, 2007
Web 2.0 on the iPhone
So, some are complaining about Apple's announcement that they'll be exposing iPhone's features to developers via a Web 2.0 interface (whatever that means). I assume it's going to be (ideally) understanding URIs (such as the tel: scheme), media formats like vCard (maybe microformats like hCard and hCal?), and perhaps some JavaScript functions.
I think that while ultimately there should be an ability to release certified OS X apps on the iPhone, this is going to be a very big deal. Seriously, does any other phone really integrate hypermedia into the phone experience? I've always felt this was one of the best features of the BlackBerry, that all of the apps had some level of hyperlinking to the phone. But, the web browser still was a walled garden. Not anymore.
I think the herd is seriously underestimating the flexibility of this approach. They're too busy waiting for their VLC or Skype port, but they're pretty marginal, have been done before, and still are unlikely to offer a mainstream experience (on a mobile device) for quite some time.
It remains to be seen if the iPhone device is as usable and productive as it looks, but if it is, I'm looking forward to seeing some interesting iPhone web apps fairly quickly. This could be the beginning of real convergence.
Business Architecture in a Web
It's often asked what the business implications of a web architecture are. "What impact does REST have on business?", "Isn't this just mechanism?", etc.
My claim: It's about moving from "push" to "pull" approaches for resource consumption and business process design. See John Hagel's viewpoint. Read about Lean.
June 10, 2007
Data-centric architecture
This is also based on a recent post on the Yahoo! SOA mailing list, modified somewhat.
One complaint about RESTful approaches to software architecture is that it's a difficult investment to start looking at a legacy in terms of "Resources". Many transactional interfaces already look like services or components, so a shift to WS-* style SOA tends to be easier to adopt.
I see an large amounts of work undertaken to "SOA enable" one's transactional systems into more business-relevant services, using every manner of infrastructure (BPM, ESB, Data Services, etc.). Usually this is part of a larger initiative (as "SOA for its own sake" tends to be a very hard sell).
The problem is that, in my experience, shifting an IT department's mindset towards SOA tends to require a lot of architectural change. Many transactional interfaces are at the wrong granularity. Or have disjoint, overlapping semantics with other systems that evolved independently, but now require integration. It's mixed as to how an organization may accomplish this:
- Some are throwing out their old applications and buying packages like SAP (which want to SOA-your-world). This is often $100m+ of work.
- Others are rebuiliding their systems on Java or .NET , perhaps with some best-of-breed packages to fill in some areas. Again, this can may many $m.
- Many are just layering service infrastructure on top of the old stuff but doing a big rethink as to how re-route access through the new layer. Fewer $m, but still significant.
I don't think the issue is a lack of desire for investment in new infrastructure and in re-thinking. That's happening with SOA, to some degree. I think the reason for this disconnect is probably more fundamental, and seems to lie with the education and values of IT architects, similar to the eternal pendulum debates of behaviour-centric vs. data-centric design.
Here is my take on the disconnect:
1. REST approaches are data-centric. It isolates the importance of data -- identifiers, provenance, temporal relevance -- and singles them out as some of the most important aspects of a shared information system architecture.
Anyone that has dealt with data quality, data warehousing, etc. knows that this is a huge problem, but is often ignored outside of small circles in the enterprise. Perhaps this is why so much integration is still accomplished through ETL and batch transfer -- they're the ones that pay attention to the semantics of data & integrity of the identifiers ;-)
Roy, in his thesis, even underlines this in Chapter 1, noting that the vast majority of software architecture -- even in the academic community! -- ignores studying the nature of data elements. His conclusion -- "It is impossible to evaluate [a network-based application] architecture without considering data elements at the architectural level."
COM, CORBA, WS-*, MOM, etc. look at the data elements as messages. They are envelopes, like IP. They don't consider data elements beyond this: send whatever you data want, deal with data issues your way.
REST, on the other hand, looks at this explicitly, even covering data stewardship -- ("Cool URI's don't change", and "The naming authority that assigned the resource identifier, making it possible to reference the resource, is responsible for maintaining the semantic validity of the mapping over time.")
The bright side is that these differences don't preclude COM, CORBA, WS-* from adopting constraints that explicitly deal with data services.
2. SOAP Web Services were originally created to be an XML-oriented replacement for COM, CORBA, and RMI/EJB. This is documented history.
They were intended to:
a. simplify integration, and solve the problems of these old approaches -- make them more MOM-like and asynchronous, and less RPC-focused.
b. also allow richer data structures through XML (vs. the old approaches that required custom marshalling or proprietary serialization).
c. give a chance for Microsoft to get "back in the game" of enterprise systems, as J2EE had pretty muched eclipsed DNA. They would do this by eliminating the competition over programming models & core protocols - changing their old Microsoft-centric stance.
d. traverse firewalls by piggybacking on HTTP
The focus was clearly on XML as a marshaling format. The hidden assumption seems to be that if we fix the above, the "distributed object nirvana" that we longed for from the COM / CORBA days would take hold. SOA added "governance" to this mix. While SOA governance may deal with data problems in isolated cases, there is little consistent *architectural* treatment of data in these aproaches. It's still a mishmash of CBD, object-orientation, and message architecture.
Some articles to read....
September 1999: Lessons from the Component Wars, an XML Manifesto
April 2001: A Brief History of SOAP
Interesting quotes:
- "SOAP's original intent was fairly modest: to codify how to send transient XML documents to trigger operations or responses on remote hosts"
- "Component technology has been the cause of many arguments, disagreements, and debates. This component-induced friction can be traced to two primary factors:
1. Different organizations and corporations want to be the de facto provider of component infrastructure.
2. Component technology provides more opportunities for different programming cultures to interact.There are many lessons to be learned from examining these two factors closely. In this article, we will examine how component technology has evolved to XML."
(As an interesting aside: Both of these articles are by Microsoft's Don Box, though I think he was at DevelopMentor at the time. I think Pat Helland is one of the premier minds behind SOA. Microsoft is responsible for many, if not most, of the protocols we base WS-* style SOA implementations on. Yet, I find it fascinating that many of the SOA industry analysts, vendors, and some customers seem to treat Microsoft as an almost non-player, since they don't ship an ESB, rarely talk about SOA in the abstract, and don't cater to business consultants. )
Today -- SOAP 1.2 and WS-* have evolved this purpose into a general purpose asynchronous protocol, it really is still a way to create a vendor-independent, interoperable replacement for MOM.
This is not to say there is no value in a better MOM -- just that there might also be a lot of value in a better way to integrate data in a distributed system. Which is why I find RESTful archtiectures exciting.
What are the benefits of WS-* or proprietary services?
This was originally part of a post on the Yahoo! SOA mailing list.
I'm firmly a proponent of RESTful architectures (independent of whether they're over HTTP, or SOAP, or whatever underlying transfer protocol), as I believe they objectively lead to more scalable, interoperable and evolvable information systems.
Of course, nothing's perfect, and the implementations & tooling out there doesn't live up to the theory.
So when are alternatives appropriate? Stefan Tilkov suggests three simple factors:
- WS-* is "protocol independent", while REST (in all practical relevance) is tied to HTTP.
- The WS-* specs address "enterprise" concerns that REST/HTTP can't handle
- It's much easier to expose an existing system that has a "transactional" interface (in the TP monitor sense) via WS-* than via REST, since the latter requires a real architectural change and the former doesn't
I think #1 tends to be somewhat theoretical. I've seen lots of MQ out there, but not a lot of SOAP over MQ, for example. Such an approach is not overly interoperable, though I can see benefits of reusing WS-* infrastructure with proprietary infrastructure when within the bounds of a single vendor's stack, like IBM.
#2 true, but the implicit problem is that the term "enterprise" is sort of like "scalability"... it's often a way to shut down debate without studying the specific concerns. Debates on "Reliability", "Security", and "Transactions" for example, tend to require specialist knowledge and, lacking that, seem to hold a mystical status that cloudens debate when RESTful approaches may have very different views on these topics (even if they are well-founded).
I have a longer discussion & historical perspective on #3, which will be in a subsequent entry.
In the meantime, here's my (incomplete) list of scenarios of when you'd want an alternative to a RESTful protocol....
- When you just need to remotely access or manipulate an object and want to make it feel like developer's local API as much as possible, without need for data sharing, or evolution. CORBA interfaces on network switches are an example of this. They're fine. SOAP and XML are being applied here too. RESTful services may even use these things.
- When you're tightly coupled, control all the endpoints, and want distributed transactions. SOAP and XML are being applied here (but WS-AtomicTransaction isn't known to be widely implemented or interoperable yet). Arguably this might be easier than IIOP or TIP, the protocols used by CORBA or COM+. Maybe it'll be more interoperable than XA resource drivers, which tend to be the most common way to integrate these transactions. There's some benefit here.
- When you want a vendor independent MOM for stateful in-order, reliable, non-idempotent messages, and don't have time or inclination to make your data easily reused, study whether your interactions are safe/idempotent (which obviates the need for dupe detection), or your application doesn't lend itself well to statelessness (which obviates the need for an infrastructure to handle retries & dupes). See WS-ReliableMessaging.
I think this is the approach that many vendors & enterprise architects are thinking will be the ultimately desirable scenario for WS-*. I'm curious how this will pan out, as I don't see a lot of discussion about the tradeoffs of this approach. It likely will succeed to a reasonable degree, though I don't think it actually helps a lot of the SOA desires for agility. Perhaps this is the area where the WS/REST bridges need to be built.
- When you need stateful, real-time communication. This is clearly for two-way streamed communication, like voice/video. You probably wouldn't use SOAP for this, either. BitTorrent is an interesting hybrid case, where they use HTTP for signalling and discovery, and the BitTorrent protocol for the actual exchange.
- High speed pub/sub event notification. While there are plenty of attempts to extend and/or emulate this in HTTP, not many have caught on. Of course, that this generally is the case with SOAP today too, since WS-Eventing isn't really implemented or ratified. So there's still a lot of room for MQ, JMS, TIBCO/RV, etc.
I don't really include security as a benefit of other approaches. RESTful web services can already reuse XML Signatures, XML Encryption, S/MIME, SSL, and allows for username/password, OpenID, Kerberos/SPNEGO, and SAML assertions already. WS-Security is just a wrapper for most of these approaches. Authorization rule engines tend to also be independent of whether something is RESTful (whether they're XACML, or proprietary, etc.) Though, a RESTful multi-party secure conversation protocol might be an interesting development in the future.
update: Just a quick clarification, as Stefan notes, that the three points he made were somewhat taken out of context from the SOA mailing list. He doesn't necessarily believe them to be true, just that they are common viewpoints.
May 22, 2007
Understanding hypermedia as the engine of application state
REST has four architectural constraints:
- separation of resource from representation,
- manipulation of resources by representations,
- self-descriptive messages, and
- hypermedia as the engine of application state.
The constraint with the most mystical reverence is the fourth one. But, really, it's not that hard to understand. It's just an extra level of abstraction above traditional message passing architecture. Here's an attempt to explain based on my current understanding.
In a tightly coupled message passing system, consumers normally depend on providers.

When we introduce an interface, we want to separate the concerns of the Consumer from the Provider. This is good software engineering, in that it enables interfaces to be oriented towards broad classes of consumers, and enables substitution in the provider's location, implementation, or even the organization that provides the service.

But what is the content of the interface? How should it be constrained, and what is the granularity?
Perhaps the best way to understand this is to look at the framing questions one asks when organizing requirements into an architecture. I like Zachman's approach, which is paraphrased here:

Technology-focused architecture tends to focus on the "what" and "how":

This is not to say that architects don't focus on other areas, but there tends to be fewer intrinsic constraints in most runtime architectures to explicitly support these areas.
Hypermedia as the engine of application state is about making sure that your interfaces constrain the "when": logical timing & ordering expectations. Since interfaces are hypermedia types, they flexibly describe the "what", "how", who", and "where" through the uniformity of resource identifiers & data transfer semantics. The "when" is driven by the context of the link within the media.

For example, web browsers have at least two well-understood and related state machines for different hypermedia types: one for HTML, and another for CSS. In HTML, tags like IMG, OBJECT, and SCRIPT tags represent resources for enriching the current context, Anchors (A HREF) are side-effect-free state transitions, and FORM tags & children describe side-effect-inducing state transitions. Whereas in CSS, links are only enriching - providing URIs to background images, for example.
The typical web services composition looks like this:

Governed service composition usually adds canonicalization of the "what" and "how" through standard orchestrations and schemas, but the burden is still on the consumer to address timing considerations. This is the case where several services share schema, but still define their own operations & service definitions.
If the servers evolve some of their capabilities that affect timing and order of operations across the composition, the client breaks. There's no way for an agent to predict which operations are "side-effect-inducing" or free of side effects to understand the impact. Furthermore, this approach doesn't loosely couple authority and location of information from the service providing it, since data identifiers are still hidden behind the facade of the service interface. Once again, the burden is on the consumer to maintain context associated with the identifier so that it can be used at a later time.

Most well thought out SOA approaches, or even "naive" REST approaches, begin to use many of RESTs constraints: they adopt URIs for most interesting things in the system, and take advantage of a uniform transfer protocol to underlie the representations. But, they sometimes choose to ignore the hypermedia constraint.
With this approach there is still big benefit in the separation between the semantics, representation, and location or authority of information that is made explicit. But there still is a somewhat tightly coupled end-result: the temporal assumptions are defined & controlled completely by the provider interfaces, and the consumer is subject to their whim.

With hypermedia, the ordering of interactions, discovery of capabilities , independence of location and authority boundaries, becomes an intrinsic function of the media type and embedded URI. All a consumer requires is a single URI to bootstrap the interaction process. The composability of information is defined by the logic behind the media type itself, instead of tightly-coupling it into a client's consumption of today's available & discoverable capabilities. The consumer agent, whether human or automated, only has to specify a high level plan, or goal, and have set of general state machines which are dynamically selected based on message metadata.
This doesn't seem like BPM-land, where analysts merrily draw their processes and change them when the capabilities change in a deploy-time/run-time separation. It is, rather, an online agent-oriented approach. It suggests that composition of unrelated services should occur through introducing a media type that fits the motivation for the composition. It is not a typical way to think about interface design.

So far, the imperfect way I think about it, given my OO background, is the passing of an object-graph to an agent, where pointers are either information/value objects that describe the media type, or are identifiers of information resources. The agent can choose to dereference the identifier, and receives a new graph, of a new type: a state change in a set of composable state machines.
When we think about WS-* style services, there's little notion of graphs of information resources. One exchanges documents with embedded, "managed" data identifiers, like primary keys. The client has to maintain the context of what the identifier signifies and know the provider's assumptions in how, when, and where the identifier should be accessed. All of these assumptions are tacit, and hence, tightly coupled.
April 26, 2007
Service component architecture
I've been puzzling for some time what the point of the Service Component Architecture and Service Data Objects, standards from the Open SOA alliance are "really" for.
SDO I sort of understand: it's a cross-language data binding API for services, competing with Microsoft's ADO.NET.
SCA on the other hand, has been quiet for a long time, though 1.0 was released on March 22. For a while, I thought it was a way to wrest control of the deployment model for component software systems away from Java, to enable a truly cross-language containment and configuration of distributed systems. It still is this, to some degree: component implementations so far can be in (simple) Java, Spring, BPEL, C++, though Java remains a kind of unifier.
But it's clearer what else it is, from my first read of the 1.0 specifications. This is my first impression, not necessarily canon:
- It's a specification for how services & dependencies, with different kinds of transport or transfer bindings, can be assembled, wired together, and deployed when within the control of a single agency.
- It specifies how implementation technologies (not just Java) can implement service capabilities.
- Thus, SCA a framework that treats services logically - not just as web services. WSDL can serve as the cross-process interface definition, but a Java interface can serve as a service interface for "in-process" SOA.
This enables multiple implementations, whether C++, Java, or eventually PHP, Ruby, etc. to have bindings and in-process exposure to any other SCA component registered within a Java virtual machine itself, or out-of-process exposure via WSDL/SOAP or a custom interface type & binding.
In practice, this means no more futzing with JNI or JAX-WS when integrating disparate components, the SCA plumbing will take care of this wiring and type marshalling. Though you'll either have to wrap your implementation with the SCA API or conform to a particular interface binding.
- It's an attempt to show that Spring dependency injection and OSGI bundles can serve as the plumbing needed to make the JVM itself a bus between in-process services, so long as the interfaces are published and evolved independently from the implementations.
- It's another run at the Beehive fence, in an attempt to create a productive development and deployment model for services that competes with Microsoft.
Five years ago, BEA came up with a crazy idea to make Java web service & web development as productive as .NET 1.0 -- the result was WebLogic Workshop (WLW) and its notion of "Controls". While WLW was a modest success, Beehive spent ~2 years in proprietary incubation at BEA as the "Weblogic Workshop framework" before being spun out to Apache, which tainted its adoption, as it was largely tied to an IDE and had a set of newish code annotations (which Java didn't have support for back then).
This time, SCA seems to be much further ahead: with a broader mindset that includes multiple implementation technologies, lifecycle and deployment going beyond EJB, a richer competitor to compare with (Indigo / Windows Communication Foundation), and long list of partners at the table besides BEA, including some of its biggest competitors.
This is definitely the kind of innovation that the SOA community needs. It is open minded enough to enable many representations of service interfaces, implementations, and bindings. SCA unfortunately doesn't focus on network-scale service interoperability with RESTful interfaces, but I don't think it will necessarily prevent the adoption of it once the industry gains more understanding of how a programmatic RESTful interface, implementation & binding should look (beyond a Servlet ;).
April 25, 2007
The Political Implications of a Web Architecture
A quote, by a CIO, on Web Architecture vs. Client/Server Architecture. This passage (from an out-of-print book) highlights, for me, why there are philosophical divides in this architectural debate to this day. I will also note that this reflects common sense today in certain crowds -- the rise of the stupid network, the end to end argument, Emphases are mine.
"Webs are spun out of fine threads, but they get their strength from clever design and a capacity to overcome local failures. Much of the promotion of client-server methods implies that by distributing existing computer power you gain in economy and reliability. If you leave the existing hub network in place without alternative database management practices, and locate the new servers at the ends of the existing hubs, your support costs as well as risks will increase. Your costs will increase because you will have many more data centers to attend to. Your risks will also increase because your points of vulnerability will be greater.
When it comes to computing, I believe that all networked computers are created equal. Some may be richer, some may be poorer in terms of power, functions, or resources. However, I consider it a matter of good prudence that all computing resources should be able to connect to each other by multiple routes. Each computer should be able to reach others by at least two and preferably three physically independent paths. The routing should not be done at hubs, but at points of origin by inserting into each message destination-seeking instructions. The traditional way to connect people, such as in the telephone system, linked dumb and low cost handsets with very expensive and enormously smart central switches. In web networking, the network is passive and the switches are cheap while the messages and the stations are very intelligent.
Network stations should be treated as equals and not as separate classes of supiror "clients" attended by inferior "servers" because the stations are now supercomputers. These distinctions are not just a linguistic quibble. They are a matter of distinction that are reflected in how network privileges and network organizations are put together.
Web networking supports cooperation among groups that organize and dissolve rapidly. It could be design engineers on separate continents reaching agreement on the layout of a circuit board. It could be an infantry commander coordinating close air and artillery actions. It could be working out details of a purchase with a stock broker. It could be an act as simple as placing an order for merchandise. Who will talk to whom, with what device, over what telecommunications link, is unpredictable and therefore cannot be specified in advance in the same way as you would design structural members of a building.
The fundamental premise behind web networking is that regardless of the amount of automation involved in a transaction, there is always a human being who will be accountable for what happens. Web networking is not only a matter of software design, but also a refection of managerial practices how to handle exceptions, errors, security, and responsibility for data integrity. The politics of web networking is a reflection of how an organization views relationships among employees, customers, and suppliers. The master-slave, hub-spoke configuration enforces subordination and centralization of knowledge and control. This form is medieval, authoritarian, and totalitarian. Peer-to-peer computing over web networks does not in itself guarantee cooperation, but surely makes it possible. It is egalitarian, with all of its faults and freedom to engage in wasteful foolishness."
-- Paul Strassmann, 1995, "The Politics of Information Management". Paul was the former CIO of Xerox, General Foods, the U.S. Department of Defence, and NASA.
April 15, 2007
Identity federation rumblings
Lots of grousing about the new OASIS WSFED technical committee & submission. See Tim Bray, also some scathing board-level rebuttals that he links to.
In simple terms, it's about getting WS-Federation ratified as an OASIS standard. Which is basically a wrapper & message exchange protocol for federated identity asssertions -- though based on the token exchange model defined in WS-Trust.
Incidentally, this is what SAML 2.0 does - it's a wrapper and message exchange protocol for security assertions whose integrity is ensured based on some kind of trusted token, whether an SSL shared secret, or X.509 public key signature, or Kerberos ticket, etc. SAML 2.0 also includes specs for basic token exchange that are disjoint from WS-Trust.
WS-Federation, of course supports SAML 2.0, where in that case, it's a wrapper-over-a-wrapper-over-a-token (WS-Fed -> SAML 2.0 -> trusted token) . I'll note that SAML 2.0 is an OASIS standard and WS-Trust so far is not ratified as such.
This is standards warfare at its finest. Vendors jockey for position, some play both sides to maintain neutrality, but in the end, interoperability suffers, as efforts are spread thin. The WS-TrainWreck is entertaining, it feels like the days when people just started realizing that many CORBAservices were unimplementable and the only ones worth using & testing against were based on the most popular ORB at the time (usually IONA's).
I hope we can get back to the business of enabling interoperabilty some day soon. My only solace in this debacle is that it makes every enterprise software vendor look near-equally silly.
March 12, 2007
A CIO on open source, information, collaboration, and architecture
Floyd finally (!) posted the video of JP Rangaswami's talk at the London UK Architect's Summit. I was lucky to be in attendance at this inspiring and insightful talk.
JP talks about intellectual property law, business benefits of openness, quality benefits, social benefits, and what he looks for in architecture (at 40:54).
On Architecture: He suggests taking a Christopher Alexander-like approach, in focusing on the constraints in the 'software living space' (habitability). Don't actually write an enterprise architecture, it's too controlling and stifling ("I'm proudly accused of not having one"), don't write hard policies & guidelines ("you must [instead] have principles that are flexible"), engage with the teams ("The architect is the de facto project manager. It is not an ivory tower job."). "An architect is not a person unique & different from everyone else, except in the commitment in that person makes in learning about what technology is doing, and how to apply it... [providing guidance] through influence, advice, and support. Having the vision to embed those values in the team and keep it going." Another favorite moment: Cameron asks, What are the biggest factors that contribute to project failure? Without hesitation, JP says, "an unwillingness to say 'no' to the customer."
Read his blog...
February 27, 2007
Http Multiparts and the case of the missing CRLF
A cautionary tale for those who believe they have the grand interoperability mojo.
There once was a big customer, an XML appliance and a web services stack. The XML appliance implemented HTTP 1.1, aka RFC 2616 and MIME, aka RFC 2046 as most expect one to. They also implemented SOAP with Attachments and the WS-I Attachments Profile, as all good enterprisey people should.But there was something odd about how many carriage return + line feeds (CRLF) to include between the last HTTP header and the start of a multipart/* entity body. The appliance sent three CRLFs, and required three, and rejected that which did not have three. The web services stack sent two and expected two, but tolerated more. Sending multipart messages to the appliance broke.
Big customer complained. XML appliance didn't budge. Web services stack, like all good software groups, believed they were in error, and fixed the issue. All was well for over a year...
...Until application server A came onto the scene. It, strangely, exhibited the same problem as the web services stack did many months prior. Big customer complained: You are out of compliance! We require compliance! You are trying to lock us in! The big customer & application server vendor both beat their heads together, thinking that perhaps the RFCs were inconsistent, or ambiguous. Eventually big customer figured that compliance is irrelevant (though, naturally, after the non-compliance tongue-lashing), interoperability is more important, whatever the fix.
In the end, of course, the RFCs, one of which dates back to 1996, are not inconsistent. It's that implementers sometimes don't read carefully.
The misleading part is in RFC 2046, Section 5.1.1:
"NOTE: The CRLF preceding the boundary delimiter line is conceptually attached to the boundary so that it is possible to have a part that does not end with a CRLF (line break). "But when one reads the BNF, we notice this isn't always true:
dash-boundary := "--" boundary
; boundary taken from the value of
; boundary parameter of the
; Content-Type field.
multipart-body := [preamble CRLF]
dash-boundary transport-padding CRLF
body-part *encapsulation
close-delimiter transport-padding
[CRLF epilogue]
encapsulation := delimiter transport-padding
CRLF body-part
delimiter := CRLF dash-boundary
Wherein we see that the first MIME multipart dash-boundary doesn't include a CRLF. That CRLF is rolled into the preamble as optional. Unfortunately, it doesn't help matters when the WS-I Attachments Profile, Section 3.12, R2936 says:
"Certain implementations have been shown to produce messages in which the MIME encapsulation boundary string is not preceded with a CRLF (carriage-return line-feed). This creates problems for implementations which correctly expect that the encapsulation boundary string is preceded by a CRLF.... RFC2046 section 5.5.1 clearly requires that all encapsulation boundaries must be preceded with a CRLF (carriage-return line-feed)."Yikes. I've sent an email feedback to the WS-I organization indicating that this seems to be a misstatement.
Informal testing (ymmv) indicates spotty compliance of how many CRLFs are between the last HTTP header and the first MIME boundary:
- Application Server A inserts 2 CR/LF, expects at least 2
- Application Server B inserts 3 CR/LFs, expects at least 2
- Application Server C inserts 2 CR/LFs, expects at least 2
- Web Services Library A inserts 3 CR/LFs, expects at least 2
- Web Services Library B inserts 2 CR/LFs, expects at least 2
- XML Appliance inserts 3 CR/LFs, requires at least 3
- do not just trust specification text -- read the formal grammar
- "compliance" doesn't necessarily mean interoperability
- software seems more forgiving than hardware
February 20, 2007
JetBlue
Guess what infrastructure JetBlue runs? I recall reading about their Microsoft-only environment back in 2001, and thinking "this could eventually bite them hard". Not that it's the reason for the operations meltdown -- that's not public info. I also believe that Microsoft's infrastructure can scale quite well.
The trouble is, in my experience, there's a false belief in some IT managers that Microsoft's software infrastructure is somehow a magical elixir to keep infrastructure costs low. That's tripe. There is no panacea in picking one vendor over another in terms of keeping infrastructure costs down in the face of increasing demand.
Maybe when JetBlue built its infrastructure out, Microsoft's approach really was the best way to keep costs low from a combination of developer productivity, hardware + software costs, maintenance & support costs, training costs, etc. But apparently they didn't track their scalability assumptions to deal with problem scenarios, like the recent Valentine's Day storms.
Broad, sweeping generalization time: there are two types of managers - those that want to sign a check and not think about their problem, and those that want to think their way through a problem. The latter is politically riskier, but the former is much riskier in reality. It's not that Microsoft's stuff can't scale, it's that management doesn't invest in it relative to increasing demand, because they signed a check and "it's supposed to work" like all elixirs should! The same could be said for large IT outsourcing or offshoring deals, with questionable results. (I could have an entire post about management-by-spreadsheet now, but I'll stop...)
The question is about where the "straight and narrow path" of your chosen infrastructure hits the scalability wall. At some point, building an infrastructure on a shoestring (and without systems architects that have a performance specialist background) is going to break your (and your vendor's) default scalability assumptions.
You need to actually know *what* scalability your hardware and software combination is capable of and not just blindly follow the trodden path of PHP docs, MSDN, IBM developerWorks, or BEA's eDocs. As Neil Gunther would say, your team needs to know and agree on what part of the scalability elephant they're feeling.
January 30, 2007
Jim Gray missing
Jim Gray, the father of transaction processing, is missing at sea... Slashdot is discussing. I owe a big chunk of my career to his work. He's in my prayers...
January 11, 2007
Life beyond distributed transactions
Pat Helland is one of my technology heroes. One of the leads of Tandem's TP monitor, and eventually Microsoft COM+, he knows transactions.
In the Microsoft PDC 2003's architecture symposium, I felt that Pat's talks were worth the price of admission on their own. He single handedly summarized why SOA was a good thing in practical, technical detail. He understood services, he understood their implications on data consistency, and it still is a testament to the dysfunction of our industry when we remain confused about SOA while Pat had it nailed back then and was communicating it in simple terms. I was so jazzed I even wrote an article back in early 2004 that was largely influenced by Pat Helland, fused with a bit of my own perspective and long-windedness.
Pat's overall theory was on the nature of data and interoperability at scale. One couldn't use distributed transactions at scale as it implied a level of trust one couldn't give in a multi-agent system (you don't hand your lock manager to a 3rd party in Taipei when you're in Brussels). He's had a number of metaphors for the same idea over the years: fortresses v. emissaries, service-agents vs. service-masters. Retrospectively, when viewed in context of Roy Fielding's work, this is clearly user-agent vs. origin-server.
In terms of "data elements", Pat suggested a distinction between resources v. activity data (and reference data transferred between them), and now, in this recent paper, entities vs. activity data. (link via Mark Baker, via Mark McKeown)
So, while the two Marks are suggesting Pat's reached REST the hard way, I would suggest this is something he's been saying for years, which is why I've never seen SOA at odds with REST. In 2003 , here was Microsoft's lead architecture guru suggesting all of this WS activity would culminate with this new architectural view of scalable interoperability. Then he left MS in late 2004, and people seemed to ignore him.
Anyway, in REST terms, reference data is representations, entity data is a resource (keyed by a resource identifier), and the set of representations as seen by a user agent is activity data. This latest paper seems to have added the importance of keys/identifiers for the entities (the resource identifier in REST or URI in HTTP).
Rather than being "REST the hard way", this is exactly the kind of paper that people in this debate need to see, understand, and debate. It talks about a topic that's often said to be a reason why HTTP is not enough, and why WS-* protocols are needed -- data consistency and reliable messaging. It also closes an implicit loop in REST when dealing with machine-to-machine interoperability -- origin servers can also be user agents, managing a set of known representations (activity data). That's the point of "hypermedia as the engine of application state". Which may be obvious if you've understood Roy's thesis for years, but it's less obvious to those that come from a distributed objects or transaction processing background.
December 18, 2006
What's a disruptive innovation?
On the Yahoo! SOA mailing list, I read the following quote...
REST is _not_ a silver bullet, remote invocation is _not_ a challenge and REST is only disruptive in that it stops people looking for the true disruption which will come when we consider remote invocation a true commodity.
And couldn't help myself but feeling that, in 1972, this might read as:
"Relations are _not_ a silver bullet, data management is _not_ a challenge, and relational databases are only disruptive in that they stop people looking for the true disruption which will come when we consider data management a true commodity."
I liken REST to relational databases as a disruptive innovation, with Fielding's thesis akin to Codd's paper in 1970. And yet relations still generate debate, confusion, and doubt to this day, with the weary, battle-scarred evangelists, tired after 30 years of debate, still trying to promote logic & clarity in the IT industry.
Ultimately, these debates won't change whether REST is or isn't a disruptive innovation -- the market determines that. I think in one sense, it's already proven to be so via the success of web. In the systems integration realm, it's mostly a matter of the market shaking out the right complements that are required to take REST effective, where established approaches rule. (WS-* is an established approach, btw, old message exchange wine in new XML bottles.)
December 06, 2006
RESTful security
Following the latest REST security discussions from Gunnar Peterson, Pete Lacey, Tim Bray.
Gunnar is set on convincing us that message-layer security is superior to transport-layer security in his Stephenson analogy:
Transport level security assumes good security on both endpoints in a point to point scenario and everything beyond those endpoints within the transaction span. Message level security lets the message traverse numerous business, organizational, and technical boundaries, with a modicum of security intact.
I think transport vs. message level security is a false dichotomy.
SSL/TLS traverses numerous business (network provider), organizational, and technical (multiple network technology) boundaries, and keeps security relatively intact. It's all next-hop routing -- when I send the message out, all I know is my default gateway, otherwise it's up to the infrastructure to figure out the path. Do I trust all of those network providers with my private information? Nay!
We also often tunnel over application-layer protocols when it suits our needs, such as how SOAP tunnels over HTTP. Both TLS and HTTP 1.1 are transport independent, they just expect a reliable lower layer. I don't believe there is anything preventing someone from building the TLS record & handshake protocols on top of an application layer internetwork, such as a chain of HTTP proxies / intermediaries. Both HTTP and TLS are independent of the underlying transport, which might be a tunnel. HTTP arguably already does this, to some degree, with HTTP CONNECT. Yes, I'm aware there are risks with HTTP CONNECT, but preventative measures are known.
I do, however, agree that HTTP is missing at least two key security features:
The question is -- why did we need to build these in a SOAP/XML stack that broke the semantics of HTTP and treats all other forms of data as second-class citizens?
I don't think XML is the centre of the web universe -- JSON is catching on like fire, and binary media types continue to grow in variety, etc. For some reason, people thought that all that businesses want is text data -- the binary stuff can be shoved into Base64 or MIME attachments. What happens when we need to apply our XML security specs on top of them? Oops! -- enter MTOM. Today, if I want to secure non-XML data within an XML-based security network, I have many layers of inert redundancy and complexity.
The XML protocols have learned, slowly, that they need to play nicely with others, lest they remain a complex island to themselves. These specs have proven to be useful behind firewalls. They have had some, but limited, success outside of the firewall.
The challenge I see is that because the XML protocols such as WS-* don't treat resource URIs, non-XML media types, or HTTP's semantics with great respect, they risk becoming yet another legacy technology before their prime. One that hinders businesses from consuming the new, cool, cost-reducing and revenue-opportunity webby things on the horizon.
Does WS-* help the new systems built with AJAX/Comet, Mashups, Wikis, Blogs, Microformats, tags, etc? Not really. Yet that's where all the excitement in the consumer space is, and where new leaps of productivity in development are emerging. It would be great if we could salvage things from the XML camp for this realm -- SAML, for example, seems to be one that could thrive given the Browser profiles. But new specs will be created to work in and extend the webby world, and they'll overlap with WS-*. It looks more & more that we are going to have two incompatible world-views and protocol pillars.
October 24, 2006
Enhancing communication
Benjamin Carlyle has been a very insightful blogger on topics such as REST, SOA, the semantic web, etc. His recent post on comparing SOA vs. REST best practices is an enlightening one, but I do find myself in slight disagreement.
Firstly, I don't think Ashwin Rao's list of SOA best practices, which is Ben's starting point, is at all what people tend to think of as core SOA best practices.
- Coarse-grained services - This one is a common SOA practice, but it's pretty vague. Thinking in terms of resources absolutely helps here. It implies that services cannot be identified solely as activities in a process model (they may be shared, they decompose into further activities that have greater uniformity than the process model requires)
- Mostly asychronous interactions - I don't believe this is mainstream opinion. I believe that the starting assumption is that that there are many kinds of message exchange patterns (MEPs), with synchronous being the most prevalent. Asynchronous interactions being necessary at times, but should be constrained to well-understood and constrained asynchronous MEPs, like publish/subscribe, or parallel fan-out + join.
One of the legitimate complaints against HTTP-uber-alles is that there are real business challenges that HTTP cannot meet today without extension, but also don't really require HTTP's global scalability. Internet-scale pub/sub, for example, has had some interesting experiments, but nothing HTTP-based has really caught on. Perhaps waka will some day solve this globally, but for now, many need local solutions -- either HTTP protocol extensions or non-HTTP protocols (like IM protocols, or WS-* protocols, etc.)
- Conversational services - This one floored me. I've never, ever seen conversational as a best practice for SOA. SOA infrastructure is stateless, state is managed when necessary at the edge (the application).
- Reliable messaging - While it should be possible to have a variety of QoS, they are subject to huge performance and scalability trade-offs. It's a very dangerous "best practice" to mandate a default as expensive as this.
- Orchestrated - Agree with Benjamin on this. And why not choreographed services? In the case of orchestration, all one really needs is a programming language. Choreography may prove, long-term, to be more important, as it describes dynamic expectations.
- Registered & descovered - Yes, interfaces need to be registered and discovered, but, this is kind of Services 101. A best practice would be that interfaces should be "governed" - that is, constrained to ensure enhanced communication among more than one agencies.
Ben proceeds to make further observations on how SOA and REST are at odds. I do not believe this growing rift between services-orientation and resource-orientation does anyone justice. It belittles the work of SOA practicioners to date, and IMHO further isolates REST arguments from the mainstream, which is already problematic given the "hacker" vs. "enterprisey" thread that's common to many of these debates.
First I'll note that SOA != web services. It's an architectural style, and I believe it is a less constrained version of REST: it loosens the uniform interface constraint into what I call "governed interfaces". It does not mandate universal identifiers for relevent data resources, or universal operations on those resources. REST requires these idealized constraints for a global scalable SOA. But one cannot always follow these constraints for a variety of reasons, sometimes political, social, or even technical.
Ignoring REST does not mean one will fail in generating a scalable, profitable, successful networked application (witness instant messaging applications, World of Warcraft, etc). It means there are certain tradeoffs one must recognize when picking architectural styles, which will inhbit your ability to communicate at scale (where scale implies something beyond mere throughput, it is social scale and tolerance for diversity, heterogeneity).
Now, onto the comments:
- "SOA seems to be fundamentally about a message bus" - only if you're talking to a vendor that sells one. ;-) The difference between and ESB and an EAI broker, to me, is that an ESB is a decentralized tool for mediation. It's not at the centre. It's not required. I think it's needed as a way to mediate between non-uniform and uniform interfaces, and to transform between well-understood representations, and private ones. Maybe it should perform some monitoring & version management too. But you could do without one if you're so inclined.
- "Tim Bray is wrong when he talks about HTTP Verbs being a red herring." - I think Tim's half right, but perhaps there's a different interpretation of context. I think his comment is that the problem with REST, as implemented in HTTP today, is that it distinguishes between the semantics of verbs in very subtle and technical ways - idempotence update vs. non-idempotent update, side-effect-free vs. state changing, etc. It can get rather silly to argue about these differences beyond GET and POST because PUT and DELETE are used so rarely in practice. On the other hand, the HTTP POST operation is way too overloaded - in the past, Roy Fielding has even commented on the REST mailing list on the downsides of POST.
- SOA has no equvalent concept [to REST verbs] - I disagree, and think this is a crucial point. SOA is all about governing your network operations into as-uniform-as-possible interfaces, but recognizes that uniformity is often impossible when specifying operations with social, political or business value.
Now, this implies a looser constraint than total uniformity of identifiers and operations, but it's still a constraint. I think some may not like it because governed interfaces are subject to a situation, business, politics, etc., and doesn't have the binary nature of Roy's architectural style constraints (either you ARE client/server or you aren't, you HAVE uniform interfaces, or you don't).
The reality is that there really is no such thing as total uniformity. You may be able to get uniformity in HTTP, but that's because the semantics of the operations have no business or political value. They have economic value only in terms of the network effects their promote -- there's no reason not to make them uniform, as one can't glean any competitive advantage from playing a competing standards game.
Standardization, governed interfaces, and uniformity of interface are all cases of Adam Smith's increasing returns through specialization: you constrain the inputs & outputs of a task to enable innovation & freedom in how the work gets done. This can be done in the small (within a firm) or in the large (a marketplace). One can have a universal uniform standard, or sets of competing standards.
Uniformity is a constraining ideal. The goal (and paradox) of protocol-driven control is this: to enable greater freedom of action in what can participate in a decentralized system, you must have universal agreements of interaction. One should realize that without universal acceptance of an operation and its semantics, you're compromising your ability to communicate and scale. In economic terms, the more universally accepted your interface, the bigger the potential for a market to form around it. Which sounds rather obvious, and to some, even undesirable. - "It seems to accept that there will be a linear growth in the set of WSDL files in line with the size of the network, cancelling the value of participation down to at best a linear curve." - That seems to be the naive approach to integration that many web services adherents are taking. But it isn't SOA.
The two litmus tests I apply as to whether something is services-oriented are: are the operations aligned to something relevant in the domain?, and are the operations constrained & governed to maintain relevance across more than one agency?
Even old crusty component software had this concept - Microsoft COM specified a slew of well-known interfaces in a variety of technical domains that you had to implement to be useful to others. SOA requires governed, constrained, relevant operations. But making things constrained, goverened and determinig relevance requires political work, even if it's technical in nature. It's often in the eye of the beholder. It's painful, it's costly, and it doesn't always work as intended. HTTP managed to pull it off because no one was looking. And it specifies a very technical domain (hypermedia document transfer).
On the other hand, the astounding results of the web shows shows the power of uniformity, even with technical semantics for the operations. I think the big design lesson that WS-* folks need to learn from REST is something like this: One generally shouldn't bother to constrain operations with social or business value unless you have lots of capital to throw at the problem. There is plenty of low-hanging fruit in technical domains where one can strive for common ground, even if the operations are not relevant to the higher level domains of the actual business problem. And HTTP has already done this for many use cases! Sure, SOA requires services to expose operations with business relevance, but likely these should remain as logical operations that can be decomposed into something more primitive and uniform, like a choregraphy of uniform operations on resources. Or else you're just going to re-invent, with questionable results, what others have already done.
Having said this, even today people disagree on the utility of the distinctions between HTTP operations such as PUT and DELETE, and they're not all proven in practice. But it worked pretty well for GET & POST.
I'll end this point with a rather obvious note, but one that needs emphasis: technologically speaking, REST has not solved the bigger challenge -- which is not in uniform operations, it's in resource description & interpreting content types. This is an area where neither the REST community nor the SOA community has any good answers to -- though the semantic web community is trying hard to solve this one. And, though I digress, while the current fashion here is for search terms, probabalistic results, folksonomy, and truth driven by reputation, there are many old lessons to remember in this area that I fear are being tossed aside in a manner similar to the WS-* vs. REST debate.
- Object-Orientation is known to work within a single version of a design controlled by a single agency, but across versions and across agencies it quickly breaks down. - This is contrary to my understanding of the design principles of the web. The web is absolutely object-oriented, with resources being the new term for objects. REST is merely calling for the old recognition that one requires uniform protocols to enable your objects to work well with others. In some languages, like Smalltalk, this was by convention. In others it was an abstract base class or an interface. New programmers rarely understood the value of this, and it's similar to what we're seeing with naive web services implementations with WSDL - a blooming of interfaces, without any real focus on enhancing broad, interoperable, networked communication. Experienced programmers knew how to use protocols & interfaces to make their system constrained and useful across many contexts and agencies. They're called class libraries! But I'll observe again the same thing as I do with HTTP verbs: the disctinction between operations and their semantics were technical in nature. If I create a common set of operations for a List, it has no political or business value, so there is no competition to make it uniform.
From another perspective, I highly suggest a look at Part IV of Eric Evans' book Domain Driven Design. He introduces a number of patterns that effectively conclude that at sufficiently large scale, any object-oriented system must become services-oriented. Domain models must be bounded within a particular context, communicate through a published language (representation or content-type), and maintain some uniformity through a ubiquitious language (uniform interface). Sounds a lot like REST to me.
In summary, SOA is not new, and many of the architectural constraints of REST are not particularly new -- Roy's genius was in the synthesis of them. SOA is evolving from two sources: a loose community of practitioners of networked business applications and a set of vendors pushing a new wave of infrastructure and applications. There's bound to be conflict and vagueness there, given the variety of backgrounds and vested interests. This was a similar case with OO back in the early 90's, but it seemed to survive.
My point is that uniformity, as REST's most important constraint, can be seen, in glimpses, throughout the history of networking software. But as an industry, the users of these technologies often don't grasp all of the implications and insights in their tools. Sometimes these technologies made poor archtiectural choices for expedience, which makes them unscalable or unwieldy. We often forget the lessons of our ancestors and have to fail several times before remembering them.
REST vs. WS-* seems to be another stab at this, and I hope the WS-* community eventually learns the lessons that REST embodies.
Beyond this, I hope the REST community learns the lesson that the many in SOA community take for granted: uniformity, as a technological constraint, is only possible in the context of social, poltiical, and economic circumstances. It's an ideal that so far is only is achievable in technological domains. HTTP, while applicable to a broad set of use cases, does not cover a significant number of other use cases that are critical to businesses. And HTTP over-relies on POST, which really pushes operational semantics into the content type, a requirement that is not in anybody's interest. In practice, we must identify business-relevant operations, constrain and govern interfaces to the extent that's possible in the current business, industry, and social circumstances, and attempt to map them to governed operations & identifiers -- whatever identifiers & operations are "standard enough" for your intended audience and scale.
September 19, 2006
BEA's microService architecture
Lots of announcements have come out of BEA World today. I'd like to draw attention to the microService architecture. This is my own analysis, I work at BEA in Canada but do not speak for them in my personal blog.
MSA is the most exciting thing I've seen at BEA since I've joined in 2004, which was partially driven by seeing an early demo of Quicksilver, which became the AquaLogic Service Bus. I've been following MSA since early in the year, and want to say that it's real, it's not vapour, it's being adopted widely internally, and for architecture nuts like me it's a fabulous development.
To understand the implications, take a look at Eclipse's plug-in framework and the innovation happening there. Eclipse effectively has transcended the IDE and has become a general-purpose client application environment. The basis of this is the OSGI framework and Equinox implementation.
In comparison, BEA's microService Architecture starts with a backplane that enables a variety of frameworks and services through standard interfaces & contracts. These can be infrastructure (messaging, monitoring, management, security, etc.), or application activities in a container (SCA, Java EE, or even other langauges that bind to a JVM, such as PHP). MCA is also based on OSGI. These interfaces can be in-process, out-of-process, networked, etc., and are independent of protocol. And I mean protocol in the big picture sense of the term - language bindings, network protocols, etc. The MSA effectively is a general-purpose networked infrastructure environment.
There will be some pre-requisites, of course (a JVM likely will always run the backplane, for example), but besides this, one gains a lot of freedom to evolve parts of their infrastructure with some autonomy. Now one can mix, match & blend components, services or frameworks from a variety of sources. Instead of a monolithic "application server", or "integration broker", BEA can deploy a small number of capabilities in a small footprint catered to a particular situation.
This is, in a way, a culmination of the "blended" open source strategy. For example, one can take some of BEA's proprietary features, such as the BEA Security Framework (which IMHO is the industry's leader in terms of capability), and blend it with the open source Jetty container, for example. Or take some of the AquaLogic services and blend them with the Tuxedo ORB container.
Arguments about WebLogic or AquaLogic being "heavyweight" melt away under this approach. I have no idea what implications this will have on BEA's product structure or business model, but the possibilities are huge, not to mention the potential agility benefits.
BEA is doing three things that strike me as significant (so far): First, they're decoupling their products into a modular, services-oriented approach, thus reinforcing the company's commitment and expertise in the "A" of SOA -- architecture, while retaining three independent product lines with different target audiences. One might claim that BEA is just making up for its acquisition spree & disparity between technology stacks, which is partially true, and at least they're doing something about it, instead of performing integration by brand-name-only. The other side of this is that BEA purposely doesn't want to force customers down a specific infrastructure lock-in route -- it's trying to be Switzerland.
Secondly, BEA is creating an architecture that could beat the "open source stack" companies at their game, by enabling a blending of open source and proprietary components, centralized & decentralized services in a flexible solution that retains the scale & reliability that BEA is known for. I think Peter Yared may have to wait a bit longer before grabbing BEA's 5 billion dollar market cap.
Thirdly, it's a recognition that SOA is independent of web services or any specific technology. Listen to Jon Udell's podcast with Paul Patrick from July 2006 to underscore this vision, which I think is a fairly unique one among vendors.
August 22, 2006
In support of complex tools
I think the calls for Java EE's demise way, way premature, and seem to be more about laziness (avoiding a learning curve), hubris ("I could do better!"), and generating notoriety on behalf of up-and-coming analysts & authors than being arguments of real substance.
I really like simple tools, and expect people to use them to the extent possible. But many problems require sophisticated tools. Yes, there is a tendency for people to over-complicate things, or "puff up" the problem to make it sound harder than it really is. But there are many hard problems, and there aren't always easy or "reasonable" solutions to these problems in many environments.
In my experience, the way to economically solve hard problems in an IT shop (whether an outsourcer, internal, whatever) is to use tools with multiple robust layers of abstraction, which can be peeled back to solve harder problems. This similar to what many Java EE, Microsoft .NET, CICS, IMS, Tuxedo, Oracle, or many OS-specific C++ environments have.
The way NOT to solve hard problems is to re-invent your own language and framework from the ground up, or rely on a new language with incomplete frameworks or niche target environments -- unless you're willing to invest in building or contributing to an open source community around the language or framework for the long haul, have the appropriate expertise & flexibility on tap, and are willing to deal with schedule risk.
The big problem with this latter approach is the following: when you want to peel back a layer of abstraction in such environments, you're left with either an small feature set or unstable abstraction, or a big gaping hole in the layers, requiring you to drop down to very low levels to solve the problem (with C libraries, for example). This is approach not clearly condusive to business value (it might be, but it's rare).
So, when looking for an alternative to Java EE, when dealing with hard problems, I think it's wrong to suggest, as some analysts do, that one can turn to a community-supported language & framework environment. The companies that do this must have tremendous expertise and flexibility in working at low levels to work with unstable abstractions or write their own versions of incomplete features (which likely would be re-contributed into OSS). For unpopular, difficult, or frustrating features, it's difficult to incent communities to build robust versions of such functionaltiy, and one likely has to pay for it themselves.
More plausible alternatives include Microsoft .NET, though I don't believe Microsoft .NET is really simpler to Java EE. It's clearly getting more complex at the language level, with C# 2.0's support for generics, partial classes, and C# 3.0's support for LINQ, extension methods, and lambda expressions. This isn't necessarily a bad thing, as one person's complexity is another person's "richness".
In any framework, as more people use it, they will require more variety and breadth, they will follow a similar path as the Java libraries have, with one exception: Java's API's have always been built with swappability in mind, most other library language bindings are one-offs. Building a language binding for a C library is one thing, building a canonical language binding for ANY library is quite another.
My point is this: while sometimes you can hit the "reset button" on a language to clean up unnecessary complexity (Java has a lot, to be sure), you can't magically whisk away natural complexity that is extrinsic to the language and framework. Database access, transactions, concurrency, fault tolerance, reliable distributed communication, cryptography and PKI, data transformation & binding, search & indexing, web frameworks, O/R frameworks etc. are all hard, complex problems to create a robust API standard for. Sun and the JCP, the Apache Jakarta project, and the Eclipse community have done tremendous work here and it would be a shame push it aside just because it has a learning curve & may have some design flaws.
July 07, 2006
I've been RESTified
After a lengthy debate on the Yahoo! SOA mailing list, I think I'll come out of the closet as an admitted RESTafarian / Web Stylista. Probably 4 years too late, but better late then never.

This really has been an intellectual journey for me, which is the main reason I'm noting it here. I've always believed REST was relevant, and that you could do a lot with just HTTP, XML, and other mime types as the foundation of your distributed system. I've usually recommended to my clients, even back since the early SOAP days in 2000-2001, to support uniform interfaces where ever possible. I also remember the extreme frustration with most WSDL/SOAP toolkits making this nearly impossible: they required a unique SOAP body global element declaration (GED) to dispatch messages to code. URIs are also near-useless in the WSDL world - they described an "endpoint", not the variety of resources inside of it that one might want to link to. Building-in a universal "GET" was near-impossible within this model, until the introduction of WS-Addressing & WS-Transfer.
But it took me long a while to understand the economic and organizational implications of uniform operations + and self-described data types, and how the web already embodied them. The importance of URIs for network effects, for example. The distinction between transport and transfer protocols, and how uniform data transfer enables interop in the face of decentralized anarchy. Or that hypermedia really is a globally decentralized state machine, with hyperlinks as transitions.
The real benefit of "SOA" (with the web as a prime example of a constrained SOA) is not about classic reuse economics (saving labour), it's about federated decentralization and increasing returns through network effects. I'm sure there are many people out there that are still struggling or even disagreeing with these notions.
I hope people don't see this as a useless religious war; there really is some extremely important work to note in both Roy Fielding's thesis and Rohit Khare's followup. It's unfortunate that some topics become emotionally charged and associated with the feeling of frustration that the advocates may generate. Perhaps there will be enough of a groundswell to generate a new understanding of how to tackle integration challenges. Given the recent WS-* skepticism all over the web (some of which is warranted, some of which isn't), it might be possible.
I still think there is a role for "governed" interfaces if uniform interfaces are too general and abstract to work with in one's environment. But I've rarely found an environment that couldn't at least take advantage of a universal HTTP GET and use of URIs and links. I think ESBs like AquaLogic will become increasingly important gateways to provide URIspaces on top of SOAP/WSDL or other protocols in a SOA.
June 15, 2006
What I hate about my Mac
I love my MacBook Pro. But there are some things that are driving me crazy.
- Microsoft Powerpoint for the Mac was always a bit annoying, with dozens of "Converting Metafile" popups for any Windows-drawn presentation, as it converts the pictures into a more useable format. If you don't resave the presentation, it will do this every time you load it.
Running PPT on Rosetta makes it intolerable -- any presentation I open requires 2 to 3 minutes of waiting while it figures out how to render it. Saving a file takes 15 to 20 seconds. Once it gets going, it's somewhat useable. But frankly it's faster to boot up the Parallels VM and use MS Office there.
- I migrated my iMac G5 onto the MacBook Pro. This normally works well, when I went between my Powerbook and iMac, and for all observable effects also worked well for me on the MacBook, but may be the source of some of my woes below.
- I have many, many Microsoft Word, Excel, and Powerpoint documents. Perhaps as a side effect of this Rosetta-only support, Spotlight absolutely crawls on my system. A typical query takes around 25 to 40 seconds to run.
- The design of Spotlight is completely unusable for a system with a large number of files if the queries take this long. As you type, the incremental search kicks in, and usually pauses while in mid-word. If I have a spelling mistake, it takes a good 5 to 8 seconds for my delete and rekey to take effect, wasting a significant amount of time.
- Furthermore, I can't select an item on the Spotlight list until the entire query has finished, as the list is continually shifting around -- one minute the file I want is there, the next minute it disappears. I try to click "Show All" to get a more stable view, but every time I scroll down the window, it insists on resetting the scrollbar to the top of the window as it adds more files to my search set.
This is utterly maddening -- it means I have to sit and wait the better half of a minute for any search. The whole point of Spotlight was to make it quick to find anything within 10 seconds. It's almost faster to poke around with the Finder now unless I'm completely clueless as to where the file is.
I've heard that Quicksilver is a better interface to Spotlight, but I haven't acclimated to it yet.
- One final note on spotlight: Sometimes, for inexplicable reasons, "mds" and "coreservicesd" (which I believe are Spotlight services) will take up 50% to 80% of my CPU for 2 to 5 minutes, which means I'm basically using almost a single core in my Core Duo for indexing.
If I'm running Parallels VM at the same time, this translates to around 120% CPU usage at idle. Now, this normally goes away down to acceptable levels (Parallels tends to consume 15% CPU at idle).
- There is currently no great way to play WMV media files on the Intel Mac platform. The options are, in order of performance: use the legacy and deprecated Windows Media Player 9 from Microsoft under Rosetta (around 15-18 fps), install Flip4Mac WMV Components 2.0.2 under Rosetta (which is not supported and requires flag setting contortions to get to work, and is maybe 10-12 fps). VLC is not an option, as it doesn't play WMV3 files.
- Sometimes I get the "spinning wheel of death" upon awakening the Macbook Pro and have to perform a hard reset. This last happened when I was trying to select a WiFi network shortly after awakening.
- While I know its not supported (and there's a cabal of Mac users at BEA that keep clamouring for it), WebLogic Server 9 (based on the AIX install) seems to be really, really slow on my Mac. WLS 8.1 was much better. I haven't had time to investigate whether there's a new "fast=true" flag I'm missing.
- Boot Camp Beta's repartitioning feature is not foolproof -- it's best to run this on a fresh boot. I ran Boot Camp a few months ago and undo it. Decided to re-install XP recently. Boot Camp locked up at the end of its repartitioning (spinning wheel of death). After a hard reset, XP proceeded to install, but my OS X Install would kernel panic every time I selected it.
After picking myself off the floor, I discovered through Apple's support forums that the repartitioning apparently didn't properly handle swapfiles, corrupting my filesystem a bit. Performing an "fsck -fy" resulted in an "invalid extent entry". So, I boot to single user mode (Cmd-S), move the old swap files (with bad blocks) to a new location, so the next time OS X boots it recreates them on "good extents". It's good there was a way to recover with command prompts, I guess, but most sane people would have just re-installed....
Minor quibbles:
- When looking at album booklets in iTunes, they show up in the little postage stamp of a window, but when I click on it, it doesn't expand into a larger window, no matter what I do. I have to drag the file from the Finder onto Quicktime to actually play it. iTunes Videos work fine, just album booklets seem to have this problem (I am referring specifically to Zero 7's The Garden, which I bought off iTunes).
The list of things I love about my Mac would be much longer than this list, which is why I stay on the platform. But I really needed to vent, because my likely interim solution is a reinstall -- something I left Windows for in the first place.
June 07, 2006
http can scale!
A co-worker drew my attention to an article from last summer, entitled When SOAP Fails HTTP. It discusses scenarios where HTTP is not scalable, and proceeds to suggest that the OMG's IIOP (Internet Inter ORB Protocol) should be a useful alternative to HTTP.
Given the authors' pedigree, I wanted to write a detailed rebuttal, respectful of the technical arguments. I agree with the premise, that HTTP isn't suitable for all use cases, but I think the examples are extremely flawed, and the conclusion doesn't follow.
Firstly, there is an assumption that HTTP's request/response orientation requires servers to "wait" for responses, thus making it unscalable. The same observation applies to database connection pooling, for example. Every database has its own network protocol, and most do not support interleaving requests. Yet, there are many examples of servers pooling database connection requests to handle thousands of concurrent users, despite the general lack of support for interleaving in many native database network protocols. If scalability challenges creep into an HTTP-oriented world, there is no technical roadblock to pooling HTTP connections in a similar manner.
Secondly, there is an assumption that servers are limited by the number of inbound and outbound network connections, and that it is more scalable to do things on a single connection. While there are niche cases where this is true (I'll discuss later), HTTP handles the vast majority of uses quite well.
Some context: HTTP has become so widespread that operating systems, TCP stacks and application servers have been tuned over the past 10 years to enable large numbers of concurrent connections. A scalable TCP stack, for example, will only require constant-time access to the TCP table. Most operating systems have the ability to set huge file descriptor limits to allow hundreds of thousands of concurrent connections. All that's required is enough memory -- 100,000 connections requires around 1 GB kernel-level RAM, for example. Beyond the TCP stack, a scalable server uses non-blocking I/O to handle the processing of these connections to ensure efficient use of CPU resources (such as threads).
Here is the major mistake the article makes, in my opinion: they describe a scenario that is an example of poor I/O architecture in a server, and really has nothing to do with the actual protocol being used.
An unscalable application server will dedicate CPU resources to connections, such as a 1:1 thread to connection mapping. This works well for some use cases (such as large file transfer), but less well with large numbers of small requests. Thus, a more scalable application server will dissociate CPU resources (threads) from connections.
For example, HTTP requests in the BEA AquaLogic Service Bus are processed in a different thread from HTTP responses, to enable the server to "do other things" while it's waiting for something. This is referred to as a non-blocking I/O architecture, and is essential to any scalable client or server. It's how Azeurus can support huge P2P BitTorrent transfers over TCP, or how any web server supports thousands of concurrent connections.
Certainly there are cases where HTTP isn't optimal: if you have an application with extremely high volumes of event streams with very low millisecond latency, you will not require the reliability levels that TCP gives you, for one, nor the verbosity of the HTTP header for each event. Cases such as real time stock ticks have used IP Multicast & hybrid usage of UDP and TCP to handle such cases, with products like TIB/Rendezvous and WebLogic JMS. UDP is also the basis that real time media streaming protocols take, such as RTSP.
Now, perhaps you do want TCP's reliability features (TCP window retry intervals can become problematic when you get into low latencies, but let's assume you're OK with it for now) , you could (as the article implies) gain significant performance benefits from an interleaved protocol on top of TCP. But the interleaving isn't the interesting thing -- it's the use case of communication style -- event notification, unsolicited responses, etc. HTTP is also not particularly well suited to generate unsolicited responses from servers, for publish/subscribe communication (though one could retrofit such behaviour onto TCP with SOAP and WS-*). Whenever Roy Fielding decides to publish a reference implementation of waka, we may have a shot at a globally interoperable protocol to tackle these challenges. Until that day, it's my belief that we will have to make do with proprietary transfer protocols in spots, with or without SOAP.
Both IIOP (as the authors propose) and JMS products are a suitable alternative behind the firewall for the cases where HTTP is not appropriate for the use case (as JMS can even wrap IIOP!) , but, one must recognize the limits of these approaches. These are not broadly interoperable protocols. Firstly, IIOP, while a standard, is not as widely deployed for this use case (event notification) as are proprietary messaging protocols such as WebSphere MQ, WebLogic JMS, or TIBCO EM4JMS. Second, IIOP likely will never be widely deployed for this use case, or even on the public internet for even request/response cases. It is a niche protocol, at this point -- CORBA works well behind the firewall, but the major case for CORBA today is an interoperable wire protocol for distributed transactions. And in my experience, most distributed transaction interoperability occurs at the language level, with the XA resource manager (and MSDTC or JTA) interfaces. Further, SOAP over IIOP is extremely rare, and not supported by anybody except perhaps IONA's ESB. The biggest problem is that IIOP is not native to Windows, and Microsoft will likely never support it. The other big problem is that it's a complex specification and is unlikely a high performance implementation and bindings will be available for different programming environments, even for a modest fee.
I don't mean to trash CORBA here, I was a proponent in the 1990's and it continues to do great work. But, in my experience, IIOP was rarely used in the use case they're describing -- it was used for request/response RPC style mostly. CORBA messaging, eventing and other message exchange patterns weren't widely used, even in niche enterprise systems -- those systems tended towards proporietary message-oriented middleware if they were based on events. I have seen market data feeds based on IIOP more than once, but they tended to be the exception, and the latencies / volumes were not at the level where HTTP would be inappropriate. I've also seen (and built) market data feeds that used a mod_pubsub type approach where the data content of the HTTP connection was an event stream (simulating a large, slow data transfer) when pushing events to applet or ActiveX based order blotters. I'm open minded, though, if someone could point me to some public benchmark or scalability test results of IIOP used in a P2P event notification scenario, send it my way!
JMS, on the other hand, is a binding to Java, that can wrap proprietary protocols, which may have performance characteristics beyond IIOP. Unfortunately, these proprietary protocols have all of the interoperability limitations of IIOP, with the exception that a JMS binding is standardized and generally deployable on any OS. Support for non-Java languages will vary, but I will note that most scripting languages do have JVM implementations (PHP, JRuby, Jython, Groovy, etc.), and .NET has J#.
To summarize, there will not likely be an Internet-scale interoperable event notification protocol with extreme performance characteristics requried of some applications unless you're going with the multimedia protocols like RTP and RTSP. Thus, intermediaries such as ESBs will be needed if you need to bridge between varying QoS levels, as one must adapt between a standard protocol (HTTP), a less widely supported standard (IIOP), and a proprietary protocol (with a JMS binding, for example). When choosing a transfer protocol (and its underlying transport, UDP or TCP), it should be obvious that HTTP should be considered the default choice, and one should have solid numbers to back any alternative choice up. Test, test, test the use case under load and extrapolate where the bottlenecks are. In most cases, they are not likely to be in the network transfer protocol, they will be in the application itself, or in the I/O architecture of the server infrastructure it utilizes.
May 10, 2006
briefly, on uniformity
One thing I don't think I made clear in the last entry was that I actually completely agree with the idea of uniform operations where-ever possible, particularly the universal GET and POST. And one can do a tremendous amount of good with just those primitives.
But I think it's too abstract for most. You can tell even on the web by the amount of abuse that's happening to the HTTP GET method (where people enact side-effects, contrary to the HTTP spec). Most people need to be able to have various levels of abstraction - and that means specific operations. Which is what I mean by a "governed interface" -- a contract among a group of service consumers and producers. It's a way of managing an enterprise's set of microformats and coordination languages, and perhaps mapping them to more general ones.
This is a mental journey for me, certainly... I get the point behind REST, but I also see the reality of multiple protocols behind the firewall, and thus the appeal of WS-*. Perhaps it's as Tim Bray noted, we should shoot the term "web services", as WS-* doesn't have a lot to do with the web -- it certainly is "Internet" friendly, but otherwise, it would be like calling the BitTorrent transfer protocol "part of the web". Trackers are, sure, but the protocol itself is more message-oriented, as is WS-*.
May 02, 2006
SOA's end?
Lots of interesting debates floating around the blogs lately. Tim Bray's The End of SOA is particularly apt. Yes, there's lots of vendor bullshit out there. But his story about why people prefer "SOA" over "Web Services" is cynical tripe, and very representative of the disappointing level of conversation out there.
Web 2.0 folks and REST (or "Web Style") folks are starting to sound like late 90's dot-commers, where if you associate the "Web" with something, there's a magical sauce (sometimes referred to as "lightweight" or "easy" or "open source") that gives you super-strength and solves most distributed system challenges.
There are two problems with this vision:
- Distributed systems are not "easy". The web rests on a lot of engineering, and has limits.
- Lightweight often means that means you have to solve all of the hard problems yourself, and most people don't have the knowledge to do this.
There's significant hypocrisy and hubris associated with the web 2.0 dev community's values. Web 2.0 is claimed to be a social phenomenon, whereas SOA is just vendor bullshit. Excuse me? Web 2.0 was introduced by vendors too -- it's just as much bullshit as the other terms. There's revenue streams, investment money, and vested interests behind all of these buzzwords, it just seems to be that Web 2.0 has a a more fertile ground for startups whereas SOA has too many entrenched multi-billion players in it, to the point that a startup can't compete. Thus the entrepreneurs and pundits with blogs are going to hype the area where there's money to be made for the little guy.
Web 2.0 is much less of a social phenomenon than people think it is. Blogs & podcasts, sure, that's a big deal (in the long run). Mashups and AJAX, on the other hand, aren't social phenomenas at all - they seem to be mainly just buzzwords that represent programmer hubris, and the triumph of adhocracy. But let's not kid ourselves -- these things are still very hard to put together -- it's not easy at all to create a consistent and quality experience for the user with these technologies.
The Web, HttpXMLRequest, Mashups, REST v. WS-*, are not the "answer" to enabling businesses to become more agile through distributed systems, any more than COM, or CORBA, or DCE RPC were the "answer". SOA was introduced as a concept by industry analysts and architects because they wanted to distill the principles that probably would enable business agility, if people recognized and adopted them. The reason these prior distributed systems standards did not bring about the advantages that SOA proponents claim has a lot less to do with technological limitations (which played a part), and alot more to do with business limitations.
The litmus test I use with CIOs and EA's when helping plan their SOA strategy, is when they claim they're "already doing SOA" , because they have web services, I ask to see how those interfaces are governed. And if they know what contract is in place. If all of this stuff is in people's heads, and there are no known ways to evolve the thing, then it's not likely an SOA. The web doesn't magically overcome the fundamental limits to human comprehension and communication when integrating systems without some kind of governance.
Thus, mashups are not an example of SOA. Blogs, podcasts probably are -- the governance was by the strong personalities behind the original specifications and extensions. Blogs are a good example of SOA solving a hard problem: taking a very simple technical problem in the small across an extremely large & diverse community in the large. They also serve as an interesting experiment on the challenges of extensibility. Most businesses have a smaller community to serve, but have much harder problems to solve.
Now, I don't agree with IBM's approach of providing 10,000 WebSphere products and 21 service offerings. If anything, the misguided positions & actions of larger vendors will kill SOA due to rampant cyncism and confusion. That doesn't mean it wasn't a good idea, it just means that some vendors desparately want SOA to fit with their business model -- IBM's happens to be consulting, BEA's is in selling more software and making sure people use it effectively, Microsoft's is in keeping Windows important.
April 03, 2006
An open source manifesto worth listening to
I think I've finally found a well-rounded, non-dogmatic, rational, and pragmatic view about why commercial open-source software has significant benefits over proprietary enterprise software. The paper is entitled "Open Source Software: It Isn't Just for Developers Anymore" from Zimbra, an email/collaboration software company whose president/CTO is Scott Dietzen, formerly BEA's CTO.
I liked this article, and agree with most of it, though I have three comments.
Firstly, backloading software costs makes sense, in that commercial OSS does not require you to pay license or support fees until you require the value-added service of easy upgrades and support. With leading-edge technology, however, I'm not sure if it's much of a benefit. Most companies either require a vendor-guided proof-of-concept or consulting engagement to mitigate risk and increase the chances of success. In the former case, this requires substantial sales budget. In the latter case, it can cost a client tens to hundreds of thousands of dollars in consulting fees and expenses. OSS doesn't change this reality.
Secondly, I do not think that it is verifiably true that the share of sales/marketing vs. R&D is lower in commercial OSS. The Goldman Sachs quote, that 76% of revenues go to sales & marketing, seems like complete bullshit, unless they're lumping all non-R&D activities as "sales and marketing".
Looking at the latest SEC 10-Q filings, RedHat Inc., for example, spends only 13.2% of revenue on R&D and 28% on sales & marketing. The mighty Google spends barely 7% on R&D, but 8% on sales & marketing. To contrast, Oracle spends 13% on R&D and 22% on sales & marketing. BEA spends 15% on R&D and 37% on sales & marketing. Microsoft's ratios are comparable.
Most OSS advocates aren't generally into business, finance or accounting, and thus exagerrate in their minds the R&D:Sales ratio. Perhaps it is true in the short run, mainly because the companies are in startup mode and private, so we can't scrutinize their numbers. Smaller companies do pour a lot into R&D, but it's usually less than people think. Another view is that OSS often hasn't been "end user targeted", it has been technical-audience-targeted, which requries less investment in sales and marketing, as most engineers or technicians have a very different purchase criteria than a consumer or business-person.
Generally speaking, I think the more involved and broad a product offering, the more a company needs to be able to fund meetings, presentations, workshops, proofs-of-concept, executive forums, seminars, lunches, and all of the associated travel, lodging, and expenses incurred. This requries a sales budget, and requires a renewable revenue stream to fund it. Low-margin license fees combined with high-margin annual support/maintenance contracts fees have traditionally been the way to do this. While it's a clear win if the software industry finds a way of eliminating license fees, it's unclear if the economics of the enterprise software purchasing ecosystem will evolve to support this model, or if clients will demand it. I claim that, today, commercial OSS companies (such as RedHat) can't afford to do direct business with most large entities, and require a large "front company" like IBM or HP to provide the legal, support, and services firepower to make the sale, given the required technical hand-holding, procurement debates, and legal T&C's. Even medium-to-large proprietary software companies will refuse to do business with others because of these challenges.
Thirdly, the "OSS increases security and reliability" debate continues. The recent serious hole in GPG, for example, shows that open source, even for important security-focused software, does not automatically lead to "fewer bugs" -- though it does mean bugs will be arguably fixed faster than a proprietary codebase will. Security expert Bruce Schneier, for example, believes that security products should be open source to enable scrutiny, but does not believe that open souce automatically leads to "fewer bugs". Security software, and cryptography in particular, is a complex area that requires scrutiny to ensure that algorithms and pre-cautions are implemented correctly. I think it's clear that software benefits from scrutiny by experts or specialists, and that open source is a great way to make software available to them (assuming they have time to review or contribute). What's unclear is if generalist scrutiny is also beneficial.
An elegant software architecture is in the eye of the beholder, and the ability to evaluate one typically requires rare expertise. By architecture, I mean the design of the interactions, contracts, and dependencies between services/modules/chunks -- how well they perform, tolerate different modes of failure, respond to requirements changes, and in the case of multi-user concurrent software, scale with an increased user load and/or increased hardware capacity. What often passes for "elegent architecture" in the OSS Java community today, for example, would likely give an expert enterprise architect major indigestion. The BileBlog chronicles the hubris and unreality prevalent in major pockets of the OSS community, even though Hani has a financial stake and strong belief in the benefits and success of commercial OSS.
To be fair, Zimbra's paper does suggest that one goes with a "winning" OSS project, though it's sometimes hard to tell what's actually winning vs. what is an orchestrated astroturf campaign. While I am in full support of the power of increased expert scrutiny on quality, I do think there is a large tradeoff here -- the mob-mentality that is so good at fixing bugs is also very good at starting religious wars to hold certain ideas back. A recent article (I can't remember where) noted that since the late 1990's, the number of discussions on open source mailing lists has increased geometrically, but growth in the number of actual development contributors has been quite small. The vast majority strikes me as religious posturing, arm-chair quarterbacking, and flame wars (see Gnome v. KDE).
Part of the problem is that there is no single "OSS community" - there are many communities with a loose set of shared values, and they don't necessarily play well with others. Many marvel over the elegance of Squeak, Scheme, or FreeBSD, but plenty of OSS developers have a strong dislike of Lisp, Smalltalk and other high-level languages, and most (non-Macintosh) X11/GNU platform users run Linux, not a BSD variant.
To summarize point #3: every OSS sub-community has its own value system to evaluate quality & elegance. The quality and elegance they value is not necessarily (and sometimes in direct opposition to) the value system of a paying customer.
I will leave you with this... A wise business/economics professor and tech company advisor once told me, around 6 years ago (i'm paraphrasing): "The Internet is not reality. It contains a thousand cross-section samples of reality, with unknown, highly skewed distributions. Your business will fail if it is your primary source of market information."
February 15, 2006
The most important strategic decision a CIO can make
If you haven't seen it, Christopher Koch recently opined that "enterprise applications--big, integrated suites as a bulwark to assert dominance over customers software buying patterns--is increasingly at odds with the emerging thinking on enterprise architectural strategy: SOA."
His conclusion I found quite apt, as it resonates with what Alan Kay and numerous others have said in the past, about great and growable systems...
It seems that if SOA really takes over, the software that links applications together, rather than the applications themselves, will become the most important strategic decision that CIOs make.
January 28, 2006
SOA's technical landmarks
I think there's a lot of curiousity about what has led people towards SOA as a preferred architectural style for distributed computing. Besides market and business factors, especially SOA's focus on IT governance, which are likely the primary reasons, there are big, solid technical reasons for the shift, in my opinion.
I think the technical reasoning is three-fold: firstly, SOA recognizes and re-uses the most applicable facets of object-orientation to a systems-wide case. Services are definitely not distributed objects, but they retain a few basic facets of the general object oriented paradigm. These facets being the primacy of extensible message passing with all of its implications, and the importance of focusing on designing interactions between objects (instead of their internals) when trying to construct an evolvable, growable, and interoperable system. Alan Kay, Smalltalk's father, dropped this nugget of insight 8 years ago:
I'm sorry that I long ago coined the term "objects" for this topic because it gets many people to focus on the lesser idea.The big idea is "messaging" -- that is what the kernal of Smalltalk/Squeak is all about (and it's something that was never quite completed in our Xerox PARC phase). The Japanese have a small word -- ma -- for "that which is in between" -- perhaps the nearest English equivalent is "interstitial".
The key in making great and growable systems is much more to design how its modules communicate rather than what their internal properties and behaviors should be. Think of the internet -- to live, it (a) has to allow many different kinds of ideas and realizations that are beyond any single standard and (b) to allow varying degrees of safe interoperability between these ideas.
The second reason SOA is so important is that it recognizes the long fought, hard won (and still not decided) battle that distributed computing is fundamentally different from local computing. To me, the watershed paper in this debate, now a classic, is Sun Microsystems Labs's 1994 paper A Note on Distributed Computing. I recall in 1996 the debates on the (sadly defunct) dist-obj mailing list about the importance of this paper, and how it shattered a number of the (then prevalent) CORBA and DCOM assumptions. Its major point was that distributed system endpoints require explicit boundaries to deal with the fundamental differences in latency, relability, availability, concurrency, and memory access when moving from local computing to distributed computing.
SOA doesn't have any explicit approaches to dealing with the above, other than recognizing that you have to. A service is the combination of implementation, interface, and contract, which contains the "rules of engagement". A contract is a mapping of service implementations to standard, well-understood "policies" for interaction - the mesage exchange patterns, the availability, reliability, latency, and expected volume characteristics, and how these policies are realized through the service interface.
Explicit contracts and policies, even if they aren't automated, are useful because it guides people to the correct usage of both legacy technology and newer technology. Progress towards automated policy enforcement will be slow as we're still mired in the muck of yesterday: SOAP/WSDL's RPC heritage, MOM's proprietary transport and fixed-message-format heritage, and Java Remote Method Invocation (RMI), which in practice missed important aspects mentioned in the paper, such as dealing with concurrency and interoperability, not to mention the myriad security, reliability, and availability standards and facilities out there.
Finally, SOA acknowledges the importance of shared data semantics for interoperability. A lot of the work in data warehousing community is important here, for they were the first real world attempt to integrate disparate systems under a common umbrella. Building practical enterprise canonical data models is absolutely necessary to ensure interoperability in SOA. The point is not to create a universal model for all audiences, the point is to ensure that groups of services that hope to interoperate must have an explicit mapping between their interface's representation and semantics and some other canonical representation and semantics. This may involve deterministic mappings, as would be the case with most transformation technologies, but it also may involve probabalistic mappings, as would be the case with search technologies or data cleansing/matching engines.
January 14, 2006
The open source hype cycle
John Mark Walker wrote an interesting article on O'Reilly's OnLamp site, entitled There is No Open Source Community. His argument, in a nutshell, is that many people view "open source" as an ideologically-led community, but really, it's not. The economies of scale in the software industry, made possible by the internet, are what are pushing open source forward. I responded to him on Slashdot, and am adapting that response here.
The first thing I'll note, is that in a recent (mid-October 2005?) Gillmor Gang, I remember that Doc Searls made a very similar comment -- "there is no open source community". Sure, there are communities, but they're a loose federation at best. There's no driving agenda, no cabal guiding the efforts.
Second thing is that I generally agree with the article, though I think he takes the economic arguments a bit too far. Classical economics has a major bullshit quotient; it's a useful analytical tool but is usually over-applied. I do agree that OSS would not be where it is without the Internet, but that could be said of most things in the tech world, so it's somewhat of a banal point. Slightly more interesting, I think OSS wouldn't be where it is today without the captial influx from both public and private capital (VCs & public companies). Most full-time contributors on popular projects are on corporate payroll, which is being funded either through complementary products (hardware, consulting, support) or is just a capital sink until they figure out how to make money with it.
I have my own view on the role of ideology in promoting open source. It's a strawman, but it seems to be the pattern I'm seeing.
There is no core group of ideologues that really matters anymore. Perens and ESR did good things to hype OSS in the late 1990's, but I don't think they're doing much now to increase its hype. Today, the hype cycle is fed by a large group of in-the-trenches developers that are ideologues because their don't get much personal value out of their jobs and are trying to attach themselves to a larger cause. They're frustrated with the proprietary software they're forced to use that just doesn't work the way they want it to (regardless whether their way is actually better). This leads mostly to pro-OSS postings on blogs and websites, like Slashdot, TheServerSide.com, O'Reilly Network, or whatnot.
These posts, along with their voice on projects, eventually leads to influence thought leaders inside and outside their company, looking for the next trend to exploit. Joe Developer will promote the OSS-solution-du-jour for their project, and explain its wonders to his team leads and the public, mostly based on cool-factor and some anecdotal statements about its productivity. Examples abound, such Ruby on Rails, or MySQL + PHP, or the plethora of Java frameworks.
Comment: I'm not challenging that these tools actually make life better at times, but I am concerned with two things: the influence is usually based purely from a narrow "professional lens" -- I'm a developer, I only care about developer values, and I choose tools that make me feel more productive or cool, regardless of consequences outside my area of expertise. Business factors (which often are also architectural factors) are rarely considered. In this, I agree with Mr. Walker. Secondly, that there is such chaos and splintering in the market going on due to OSS development that quality is suffering. People are going "meta" and developing more and more tools for themselves instead of using old, proven tools that have lost the cool-factor, or might be proprietary.
To continue the story, these in-the-trenches IT or ISV developers influence their team leads, who, in smaller companies with less bureaucratic oversight on licensing / legal concerns, influence their directors, and open soruce gets used on a project. Successes are bound to occur, especially if the requirements are modest, and performance demands are light, and availability requirements loose. Pundits and bloggers pick up on these modest successes and run with it, claiming that all infrastructure software -- operating systems, databases, application servers, will be inevitably open source.
Comment: My point is not that OSS can't do complex, highly available, performing software, it's that such high profile successes certainly require more research, planning and investment. As an example, look at ZDNet's blogs some time -- or the Gillmor gang podcast. They get paid to be provocative, no question, but they've been on a path for over a year now suggesting that all software will become a service, and behind the scenes it will be all open source. They're looking at Google as an example of this , brushing over the tremendous braintrust required to design, build, and maintain that infrastructure. To paraphrase Jamie Zawinsiki, open source is free only if your time has no value.
Anyhow, executives and investors read these articles and blogs, and start questioning what's going to happen to Oracle, SAP, Microsoft. And they may invest in open source startups as a hedge. And some of those in the trenches developers may actually quit and go work for an OSS startup, increasing the hype cycle.
That's my strawman of how ideology affects the software market: it creates a perception of strength that isn't actually there, yet such dissonance is a needed starting seed of all new business models and markets, so I can't really fault it. But there will be a backlash. Open source that makes business sense will thrive, that which doesn't will remain a niche. I don't forsee a complete overthrow of the proprietary software market... I tend to agree with BEA's (my employer) approach of blended open source. But beyond us, Oracle in particular is so damn huge now, they've made a huge bet that companies will turn to large single-source software infrastructure and applications providers. I can't think they're completely wrong, even if I don't entirely agree with that model.
December 23, 2005
SuperHyperFanBoys
Bruce Eckel, one of my favoured authors for introductory language books, has posted an essay entitled The departure of the hyper-enthusiasts. Java used to be an over-hyped language, now it seems that Ruby (and Rails) has become the next one, though without the corporate sponsorship thus far.
Bruce points out that Java is now being used to get work done instead of being a religious rallying cry, and EJB has done tremendous damage to its productivity. Was Java ever really suited to being a web application development language? Building web applications used to be done in Perl, but for some reason that became "bad", and Java, ASP and now .NET are used instead. In this sense, Ruby really is the "new perl", with objects that work. And perhaps the migration we're seeing from Java is from people that should have been using perl or PHP in the first place for their websites.
It seems passe' to approve of the "C++ way of doing things", but a lot of that mindset was definitely a driving force behind Java's evolution through the late 1990's, arguably for the better. Perhaps Java's staying power is due to the C++ guys more or less getting the language they wanted with Java 5; they never really were into the scripting style languages in the first place, anyway. Whereas the Smalltalk guys never really got much play at Sun, now they have Ruby as a way of resurrecting their beloved language features.
My own curiousity is whether Ruby will take more mindshare away from Java/.NET or if it will come from PHP, Python, and Perl. I tend to think the latter, most of the leading edge work I see corporations doing are NOT "connect the database to the web", which seems to be where most programmer's heads are still at en masse. What's even more interesting is that .NET seems to be taking the "innovative road" with C# 3.0 and LINQ...
On a final note, it is unfortunate to see respected authors/figureheads cashing in on a hype wave so quickly with sloppy books and poorly formed or researched ideas.... these are the former Java-gurus turned Ruby hucksters. Some honestly just prefer Ruby as a language, and have been saying it for years prior to it being popular (I know I've been a Ruby fan since 2000-2001 for my personal use, but I've rarely used it professionally), but others are coming out and stating their love for the language along with a new book professing their love...
December 19, 2005
SOA Certification
Now that it's announced, I feel I can reveal one of several things I've been working on at BEA for the past several weeks: BEA's SOA Enterprise Architecture certification, particularly phase 2, which should be available at the end of December.
A number of people, including David Linthicum have suggested there should be some kind of SOA architecture certification, and have been publicly debating the kinds of questions it would ask. Well, here are the exam objectives. I welcome comments.
My perspective behind the exam: BEA's interest is in promoting SOA as an IT strategy; certainly software-as-a-service has a broader implication on the consumer and social realms, but we sell "bet your business" infrastructure to would-be service providers and existing IT shops, and have a large installed base both on Tuxedo and WebLogic. So, while we believe in Web 2.0 and SaaS and all the changes to the industry it's bringing, we're biased towards a practical, results-oriented method to adopt SOA in existing organizations, not green-field startups. We want to certify architects that have a broad and deep view of the terrain.
The certification is not about understanding BEA's products, and we never mention any. We use industry neutral terminology, though of course BEA has its own dialect of this terminology, such as referring to SOA-enabling stacks as "service infrastructure", for example. The certification is about understanding both the business, process, and technology ramifications of services, and especially being able to understand the practical ways in which to move a legacy IT base towards SOA. The kind of candidate we're looking for is someone who will help guide an SOA transformation program at an enterprise (for phase 2) and someone who intends to lead an SOA transformation program (for phase 3). And yes, there hopefully will be more collateral (study guides, papers, etc.) in support of this certification in the coming weeks.
Anyway, take a look, I think it's a unique take on the challenge of SOA.
November 28, 2005
architect's summit
A recurring theme here is the general malaise of the enterprise software development space being beseiged by warring factions, religious arguments, and petty bickering -- leading to lots of reinvention, duplication of effort, and piles of hubris. It seems like a significant part of the industry has gone "meta" and just wants to build tooling, and doesn't seem to want to get any real work done with the exiting tooling. Whereas a lot of people are very happy with .NET 2.0 and J2EE 1.4 w/ Spring, Hibernate, and Struts. And lots are also happy with the proprietary "up-stack" products from IBM, BEA, and Oracle such as their integration and portal severs. WebLogic Portal, for example, is BEA's hottest selling product, though if you read the pundits in the blogosphere you'd think portals were passe'.
Anyway, I think there is a general need to agree on some core principles and guidance of how to build robust and performing enterprise software, regardless of your chosen religion. Thankfully, it looks like I'm not the only one.... later this week I'm heading to London UK to attend an architect's summit, organized by a few technology thought leaders -- Rod Johnson, from Interface21, Steve Ross-Talbot from the W3C, Alexis Richardson from Monadic & MetaLogic, Floyd Marinescu from TheServerSide.com and John Davies from C24. Around 30 tech architects are expected to attend from across the globe, to discuss practical guidance on building distributed enterprise systems.
Hopefully we'll come to some kind of agreement on a roadmap or manifesto. Stay tuned....
November 01, 2005
BPEL backlash
The BPEL backlash has begun in earnest. I alluded to the problems of applying BPEL as the solution to all routing & rule definition problems in yesterday's blog entry. Now David Linthicum opines that BPEL ain't there yet.
I quite liked David Chappell's take. BPEL is important as a business protocol specification language. It can be an effective way to model distributed interactions, though it is an "orchestrated" approach vs. a "choreographed" one. But BPEL is not "really" going to be a portable execution language, except perhaps within some communities (i.e. Java), and even then there are missing extensions that are just now being considered (i.e. BPEL4People).
Though you'll notice the omnipresent VP of Oracle's BPEL PM, Edwin Khodabakchian, posting comments defending his solution. I like Oracle's BPEL PM, I think it's comparable to MS Biztalk or BEA WLI (which is saying a lot), but it's just as "locked in" as those solutions are. Perhaps porting between IBM WBI and Oracle BPEL is a bit easier than the others, because they both use WSIF. But JBI is going to replace WSIF some day, arguably. And WSIF/JBI don't work with .NET or other environments. There are big problems lurking here.
October 31, 2005
Let confusion reign
The Enterprise Service Bus (ESB) debacle is a prevailing sign of the integration industry's utter disorganization and confusion. Customers & vendors do not seem to know or agree upon what they wants in the integration space -- only that it involves some magical mixture of reliable messaging middleware, business process orchestration, and XML-aware routing and data transformation. So, no one really can agree on what an ESB is, other than it's some sort of bundle of features that might be implemented by one or more products and tied together in an "architecture" (whatever that is).
Despite this frustration, I tend to think it might be a good thing (in the long run). Indecision and acrimony is usually is an indication that something is important. How many things that are important in life are nearly impossible to define in an agreed upon manner? What I would like to address today are the arguments against the ESB, and also the caveats to consider when adopting one. Buzzword bingo follows; please try not to cry (much). Also, I come from a biased background (BEA consulting), but that doesn't mean what I'm saying has anything to do with BEA's agenda, it's just my interpretation of the market.
The ESB opponents seem to have three arguments, not always held simultaneously:
a. ESB is not a product, it's a pattern (aka. I can do that stuff today with [insert favorite tool here] )
b. ESB is proprietary, web standards only should be used (aka. the "fabric" approach).
c. ESB is unnecessary, as is all of SOAP and WS-*, we all should be using REST-style XML+HTTP+SSL.
IN short, my answers are:
a. FUD.
b. Standards are absolutely necessary but can sometimes be overrated, or solidified too quickly, before the industry knows what it's doing.
c. B.S.
Argument (a) is a game of FUD to me: vendors and interest groups are trying to protect their turf. For example, Microsoft claims they have everything an ESB has with Biztalk, which is true, but it's disingenuous. Respected developers are falling in love with Biztalk 2004, but its not like this is particularly new -- BEA has had everything Biztalk has (and thus an ESB has) with WebLogic Integration (WLI) 8.1, since mid-2003. Yet BEA doesn't claim WLI is an ESB (though you could build an ESB with it). BEA claims the AquaLogic Service Bus is an ESB. It supports stateless multi-transport / multi-format stateless transformation & routing in an appliance-like manner -- no custom code other than XPath, XQuery and a graphical pipeline language. IBM recently announced 2 ESB's -- one based on WebSphere Application Server (for standards-based interop) and one based on MQ (for proprietary + standards interop). Then there are the plethora of smaller ESB's from Cape Clear, Sonic, Polarlake, IONA, Fiorano, etc. They're all ESB-like and yet none of them fit the broadest definiton. Some are more optimized to certain use cases than others. Some ESB vendors still require code for the "last mile", others need it for cases such as long running processes. And one has to wonder whether BPEL support is required or not to be an ESB, even though it's not even standardized yet!
So the story isn't over yet as to what an ESB should / should not be. The takeaway is that many ESB products make life simpler than using traditional brokers, but no ESB products (yet) cover all popular integration use cases. YMMV.
Argument (b) has some merit to it, which is why I will address it at length.
Many ESB's push their proprietary messaging heritage and have features that virtually ensure lock-in. Cape Clear distinguishes between "service-centric vs. message-centric" ESBs, and have a paper on the subject. It is marketing focused (being a thinly-veiled attack on Sonic), and it pushes the purist "fabric" approach to ESB a bit too much, but there are good points. My view on this debate is to look at it in terms of feature lock-in.
There are two classes of features: fundamental and instrumental. Fundamental features are "required" features to do anything useful with a product. Instrumental features are "tooling", and not required for the core operation of the product.
Fundamental features tend to be the core policies or abstractions exposed by a product. In an ESB, the fundamental features are routing, transformation, security, auditing, SLA enforcement, and management. These features must have, at the very least, a clearly-delineated mode that is on track with a standards-based "least common denominator" approach, or else you will be locked-in to vendor's infrastructure.
For example, Sonic ESB likes to push "distributed SOA" or "itinerary-based routing" as a core feature of their ESB, one that no other vendor can touch. Itinerary-based routing is the idea that a message is like an "agent", it has a series of endpoints in its header and the ESB infrastructure will read this itinerary as it routes the message through the network. This approach to routing has some intuitive appeal, and was also pushed, briefly, by Microsoft with their WS-Routing specification.
However, all of this is irrelevant now -- the standards process has jettisoned WS-Routing in favour of WS-Addressing. Itineraries are inherently insecure because every ESB intermediary must modify the message header as it is going through its itinerary. WS-Addressing adopts the "next hop" approach to routing, the same one that the TCP/IP adopted: the IP header is never modified, and routing decisions are made by intermediaries (such as a Cisco switch or router). Microsoft published a paper in mid-2004 explaining how to handle web services routing with this model.
The moral of this story is that routing is a fundamental feature, and "next hop" routing is the only standard way to approach it in a transport-neutral fashion. Arguments that claim other ESBs or BPM engines like BizTalk are "hub and spoke", and not "truly distributed" are disingenuous. The entire internet is based on "next hop" routing with registry-based lookup (DNS). The web services world will likely follow the same approach when ESB's start integrating with UDDI registries.
Sonic does make one good argument, though flawed, about the benefits of their approach. Itinerary-based routing facilitates a global process view instead of a splintered process view. That is, you can "orchestrate the orchestrations" across multiple intermediaries. The flaw in this is that the argument really isn't about routing, it's about global interaction management. All of these modern ESB/BPM hybrid engines, whether BizTalk, WLI, or BPEL-based are about "orchestration". They all require a central conductor to manage the process state. BPEL is just-another-way to implement an orchestration -- something you could also do with BizTalk's XLANG or WLI's JPD. But one doesn't need the drawbacks of itinerary-based routing to get a global view, one just needs a a contractual set of interactions -- something also known as choreography. Perhaps WS-CDL (Choreography Description Language) will eventually catch on to fill this void. Perhaps a future BPEL extension will -- I've noticed that IBM has released a WS-BPEL 2.0 sub-process extension just a few weeks ago. Until the industry figures out how it wants to handle choreography, which will probably require a number of years, itinerary-based routing is 100% proprietary, will only work on a single vendor's ESB (though you might be able to write a lot of custom code to bridge the gap) and will likely never be standardized. Use it if it makes sense to you, but understand the risks.
Instrumental features, as I mentioned, tend to be more pluggable -- they're tooling, they're "nice to have", but they're not absolutely necessary for the product to operate. That is, assuming one can separate the policy from the underlying implementation, supporting proprietary protocols, data formats or transports can effectively (but not completely) become instrumental. The key is to ensure that there is a very clear demarcation between what is core to the ESB and what is not, and any dependency on instrumental features has a clear abstraction. This is arguably where Java EE has always shined -- in creating a market for pluggable device drivers, whether database (JDBC), messaging (JMS), or general connectivity (JCA), allowing you to choose whatever core programmatic model you'd like for your application.
So, in an ESB built on Java EE, reliability and security could be made pluggable between SSL and WS-Security, or JMS or WS-ReliableMessaging -- assuming your ESB vendor chooses to do so in its core framework. One can use JMS in the short term, and move to a WS-ReliableMessaging endpoint once it is more widely adopted. An ESB should allow this without requiring any code changes. Routing can be generalized to rely on any metadata in any one of transport-specific headers (HTTP, JMS, etc.), SOAP standard headers, or on the content of the message itself. ESB intermediary should be able to expose both a REST-based XML+HTTPS endpoint and a SOAP-based WS-Security endpoint to the same service -- so long as the underlying service has some known way of handling security, and the ESB knows how to translate between approaches. Last-mile connectivity to legacy enterprise systems or packaged applications can be made effectively (but again, not completely) instrumental by using API-level standards such as the Java Connector Architecture (JCA), again assuming there is a general way of mapping non-XML data into XML data and vice-versa.
One key fundamental feature in the ESB market that is lacking good standards support is in the manageability and SLA enforcement space. The standards here (such as WSDM) are rather poorly adopted and lack a lot of what is needed. It will likely be years before standards evolve here, so every ESB vendor will have the opportunity to at least "try" to provide some level of interoperability with sub-optimal standards like JMX or SNMP.
A trend you'll notice here is that API-level standards are very flexible but potentially have a lot of labour associated with them. This to me is contrary whole point of an ESB -- to reduce the amount of labour required to integrate applications! If your ESB requires you to write a lot of custom code, it's not doing its job as well as it should.
Another other trend is that the ESB vendor has to expose its own set of abstractions to implement transformation, routing, and management. Consistent with my earlier point, these abstractions should NOT have their primary exposure through an API, they should be exposed themselves as standard services or through some form of management interface. But, having said that, there will probably be some level of lock-in on how well the ESB vendor manages the distinction between the fundamental features of management, transformation, routing, and endpoint bindings.
There have been early attempts at standardizing this, with mixed results. There's the BPEL 1.1 draft and Apache WSIF, both of which are useful, have some teething problems, and probably will never be adopted by a standards body in their current form. OASIS is working on WS-BPEL 2.0 which has some very significant changes over 1.1. And I believe Java Business Integration (JBI) is hoped to be a generalized alternative to WSIF. Nevertheless, in theory, you can port a BPEL 1.1 + WSIF process between Oracle and IBM's BPEL engines, though I'd be curious about how well that would work in practice. But both WSIF and JBI assume your ESB is implemented on Java EE! There will be no standard way to port a BPEL 1.1 or WS-BPEL 2.0 process that uses WSIF or JBI onto BizTalk, for example.
The moral of the standards story: this stuff is too new to expect a truly portable ESB execution language. WS-BPEL 2.0 will be close, but in practise it probably will only be portable among Java EE based containers. That might be OK -- SQL is a standard that isn't the same everywhere and certainly isn't portable, but it has been a success in terms of adoption. But WS-BPEL is arguably not appropriate for stateless ESB's like AquaLogic. Should an ESB vendor adopt BPEL for all message exchange patterns, or should it have seperate products that optimize stateful vs. stateless processing? We have a cart-before-the-horse standard, yet again! Hence proprietary extensions will abound.
My final point on argument (b) is that the "fabric" approach seems to only be pushed by small vendors that have nothing to lose, but also don't have a long track record. The WS-* standards aren't completely ready yet, so there needs to be the ability for an enterprise to choose de facto and/or proprietary standards that are suitable for them in the short run. This of course is only appropriate for intra-enterprise services, or tighly-coupled cross-enterprise integration -- which is why SaaS proponents often discount this usage of ESBs!
One claim is that only "pure" WS-ReliableMessaging implementations should be adopted. Bigger vendors are basing their WS-RM implementations on their older MOM technology, such as MQ Series or JMS, and this is somehow a bad thing. I don't understand this line of reasoning at all. The infrastructure underneath a high speed reliable messaging protocol is both sophisticated and requires a lot of investment to develop. Older MOM's are proven. Why throw them out? The lesson of recent years is that Interoperability is achieved at the protocol layer, not the API. Who really cares if my underlying MOM has a JMS binding? The point is that they must eventually expose WS-ReliableMessaging over TCP, UDP, or HTTP to be interoperable. Having said that, WS-ReliableMessaging alone has had 3 major revisions since 2003, and all the various ESB/Fabric players support it at varying levels. Until the big vendors such as IBM, Microsoft, BEA, and Oracle have their WS-RM implementations shipping, this standard is too new to be your "sole" approach to reliable messaging.
Cape Clear actually turns API-based pluggability into a feature: it is pluggable with any JMS-based middleware engine. For some, this might be compelling, especially if their MOM vendor has uses proprietary approaches to fundamental features. It has the downside of (potentially) being less performing than a fully-integrated stack. For example, I'd actually be interested to see how Cape Clear performs on WebLogic Server 9 vs. the AquaLogic Service Bus 2.x. It would indicate how much of the performance increase ALSB is showing is due to WLS9 vs. path-length and memory allocation improvements over WLI 8.1's dynamic transformation and routing.
Argument (c) to me is irrelevant if an ESB supports REST-style XML+HTTP+SSL. I believe this is the case with some vendors (though not all), so I that's all I will say there.
The Web 2.0 programmer hype
I've noticed a trend lately as part of the Web 2.0 hype. Programmers are latching on to this movement and trying to project it into their world, suggesting that the "programmer experience" should also change drastically. I thought Web 2.0 was supposedly more about user experience and collaborative agility than the substance behind how you build the stuff, but hey, people want their shot at glory I guess.
So there have been a lot of wild claims floating around lately: from claims that AJAX will kill application servers, all infrastructure will be open source infrastructure, all infrastructure will be outsourced, Ruby on Rails will kill J2EE, SOAP v. REST, RDBMS' are unnecessary to manage meaning, ESB's are bad, Portals are passe', and SOA is DOA. I can't possibly tackle these all, though I will tackle the first few. And I will post a separate entry on ESBs, a topic close to my current work.
Bottom line, these are generally ridiculous claims, on many levels -- unless (of course) you're pushing an agenda. AJAX only kills application servers if you believe that Software as a Service (SaaS) will destroy enterprise IT as we know it. This seems to be the message that both Phil Wainewright and Nick Carr like to push. Similarly, programmers sick of their existing languages and environments are also searching for new ways to do Enterprise IT, and seem to feed this line of reasoning -- they believe that SaaS will allow them to join a startup and use "language du jour" such as Lisp or Ruby on Rails to teach the Java vendors & Microsoft a lesson! This view seems to have started from Paul Graham in his various essays.
From a Service Consumer's perspective, the argument makes a fair amount of sense. From a provider's perspective, or even an "ecosystem" perspective, things start to get murky. The two-second version, from a service provider's perspective, follows -- enterprise IT still needs server side code , but a world of SaaS changes everything to a simple distinction between 'service consumers' and 'service providers', where the consumers (apparently) only need the thinest layer of HTML and JavaScript to tie together their applications. And even if you do need server side code, all you need is a bit of Lisp, PHP, or Ruby. No application server. No .NET runtime. No transaction processing or reliable messaging. Maybe an RDBMS (if you insist). Obviously I'm exaggerating the extent of this strawman somewhat, but from a high enough vantage point, this really seems to be what the pundits are arguing for.
I enjoy punditry, within reason, because it makes us think. Pundits have the odd good point, but this latest wave of SaaS and Web 2.0 stuff seem to be generating a lot more strawmen than usual. There are counter arguments that are being ignored because they don't fit into the broader agenda.
"All infrastructure will be open source infrastructure" seems to be a variant of "service contracts make implementations irrelevant", and is pushed as a way of destroying the last bit of enterprise IT that SaaS doesn't kill -- software infrastructure companies like IBM, BEA, or Oracle. But it makes no sense considering how much custom development is going on behind the scenes to make these Web 2.0 companies scale and perform. Strawmen arguments like to point to Web 2.0 companies who rely mostly on open source, but this seems like bullshit to me. Last I checked, Amazon.com used Oracle, eBay used WebSphere, and Google uses Java (in spots) -- and all rely on tonnes of custom (closed!) code. And let's not forget that Microsoft is making a huge push into this world with .NET 2.0 and Indigo. Perhaps the "long tail" of Web 2.0 services will only need the small bits of infrastructure, and only the big boys will need the "beefy" application servers. It might mean you'll need to do a rewrite if you grow beyond your expectations, it might not. The upstart SaaS infrastructure players will find some successes, certainly. But let's not get carried away. "Commercial quality OSS" is still the exception, not the rule.
Now, a service consumer certainly doesn't care if you use J2EE or PHP or .NET or Ruby under the covers, so long as you meet your service contract and/or SLA. But to claim that one cannot compete based on differentiated service features is quite disingenuous. Unless the world adopts vertical-industry vocabularies on mass, service contracts will vary , with many different kinds of features and many ways to differentiate among providers. The underlying infrastructure will have an impact on the ability to deliver these features in an agile, scalable, and performing manner. Thus there will continue to be a highly competitive market in infrastructure, probably with a mix of open source and proprietary technologies.
Ruby on Rails killing J2EE seems enthrone the "web site backed by a database" as the ultimate use case. And it was - in 2002. Enterprise IT has always been about eliminating silos and creating shared frameworks and environments. The RoR camp wants a beach head, but this will create yet another set of silos! Frankly I think IT shops are getting sick of this. Yes, the productivity is useful, but the lack of interoperability with a broader aggregation / syndication strategy is going to hold adoption. Architectural governance is getting better, and I think it will be hard to push RoR unless it fits into a broader interoperability (WSRP) and manageability framework (perhaps JRuby?)
Lots of people enjoy saying that complex technologies like SOAP and WSDL will never catch on (all evidence I've seen says they have, at least inside companies), I can point to a number of counter-arguments. "Complex" is in the eye of the beholder. Is UNIX/Linux complex? To some people yes, to others no. In the server world it is popular, but to the desktop world it is pretty complex. Does this mean it's doomed?
How about Microsoft COM / ActiveX? Tonnes of software was built on this layer. Let's just enumerate the surface of complexity here: automation vs. early binding, IDL vs. type libraries, custom marshalling, apartment threading, etc. Sure, it didn't take over the world, but it certainly took over the Microsoft world (which isn't small)!
A more universal example might be SQL and the RDBMS. Despite all the trends and hype in the Java community about ORMs and people hiding their SQL, the majority of database-using applications in the Java, PHP, .NET, Perl, Python, or even good old COBOL or C++ are still programmed with heavy reliance on SQL and stored procedures. Yet lots of people still aren't able to think in terms of sets, and DBA's are still paid a lot of money to make this stuff perform because programmers can't be bothered to understand the database. This situation isn't changing any time soon.
SOAP and WS-* are not that complex by any historical measure of comparable specifications, in my view. They're composable -- you use what you need, and don't use what you don't need. WSDL is a bit of a disappointment but is being fixed. XML Schema is probably the biggest disappointment in terms of unnecessary complexity, but it looks like we're stuck with it due to the lack of interest in alternatives like Relax NG.
I see an increase in complexity all right -- not in the individual technologies, but in the splintering of the marketplace and communities. No one wants to sit down and learn what exists, everyone wants to re-invent the world in their image, their one shot at greater glory. Not that I blame them! I'm just skeptical that the collaborative spirit of Web 2.0 will bring the talent to bear to meet what the industry needs.
September 26, 2005
distributed caches
It seems there are lots of little companies popping up everywhere touting the next great solution to scalability woes -- the transparent distributed object cache! An interesting debate has ensured on various blogs about whether it's appropriate to provide such technology with an API that explicitly distinguishes between what's cached from what's not, or if it should be done in a transparent "API-less" fashion.
This debate is an old one, and reminds me a lot of Jim Waldo et al's old Note on Distributed Computing that was very influential in distributed computing circles around the time.
Simply put, it is highly unlikely to provide a general transparent distributed object mechanism that preserves identity, takes into account latency and partial failure, and highly scalable concurrency. It strikes me that proponents of these distributed caches get way too caught up in the coolness of implementation details and don't really look at the broader implications, which really is Billy's point here.
The best case I've seen of a general mainstream distributed object cache with parallel operations is the Oracle Database's Real Application Clusters. And the whole reason they can pull this off is because the relational model and SQL completely takes algorithmic control out of the hands of the developer and keeps it in the hands of the SQL optimizer. And secondly, they rely on multi-version concurrency controlled transactions as their management model, which prevents readers & writers from blocking each other.
Yes, as a developer, you can provide hints, or re-write SQL in ways that the optimizer can better work with, and as an administrator you can declare certain preferred storage & caching settings, but in the end, it is the runtime framework that figures out the most optimal and scalable way to access the data.
As soon as you lift the layer of abstraction and give algorithmic control to a developer at the Java language level, you give up the transactional illusion (Java isn't naturally a transactional language), you give up the consistency illusion (object identity is NOT preserved across local/remote and it's requires a lot of runtime dancing to make it happen), and you're exposed to concurrency, latency, and partial failure issues that no runtime can paper over. So you'd better be an expert developer to handle this.
Perhaps the solution is to take an approach similar to where Microsoft is going with their recently-announced LINQ -- provide declarative query semantics and transactions as a native part of the Java language, and allow vendors to compete on the plumbing to make it work in a distributed and concurrent environment.
August 19, 2005
Modern disruptive technologies in enterprise software
Jason Hunter seems to believe that Ruby on Rails is a disruptive technology that will displace Java on the web tier.
RoR is certainly a very productive approach to building web sites, but it's confusing to me why people so often confuse "productive web framework" with "platform to run and operate an enterprise application". I suppose RoR may be disruptive to other web frameworks and/or technologies, but let's first recognize that Java is *not* the only one, and probably isn't the primary one. PHP and ASP.NET are pervasive.
It is completely unclear if the RoR disruption (assuming it is a disruption, which has nothing to do with someone's blog entry, and has everything to do with how the market reacts) will affect the web frameworks and maybe JSP/servlet container market or the entire J2EE application server market. I would believe the former, but have a hard time believing the latter. Jason seems to think RoR is targetted at replacing application servers and distributed transaction processors: "Like all disruptive technologies, it'll only get better. It will scale better. It will add two-phase commits and fancy message queues."
It is unbelievably frustrating to me to suggest that these features are in any way related to a web framework, in terms of engineering effort. Or that they are somehow sideshow features. Perhaps to an average web site, but this again assumes that web sites will be the primary application for the forseeable future. It takes hundreds of man years of effort to build these kinds of things.
The disruptive technology argument that Jason is using is similar to the one Microsoft makes about Windows over Unix or Linux -- Windows has everything Unix/Linux has, only more performance, productivity, and manageability. Yet Solaris, HP-UX, AIX, etc. are all still around in spades, and Linux seems like it may trump all of them with its own disruption.
Besides web frameworks, there are many disruptions on the horizon. The intense interest I see in integration technologies and web services, for example, are re-emphasizing the importance of high-speed, reliable messaging and data transformation and routing -- without having to write Java code. Another disruption is what I would call the "process & operations revolution", or "grid computing". Grids indicate a re-focus (which we lost in the PC era) on how to reliably handle the process of software development, provisioning hardware in a utility-based fashion, promotion /rollback of all changes, troubleshooting, monitoring, and diagnostics. This is arguably a major reason why Oracle rules the database world, and I think it may serve to hold off startup frameworks, languages, and platforms from capturing application server market share from the incumbents. It also at intersects and is a necessary condition to support SOA as another potential disruption, which is much less to do with web services than it is the drive to evolve from projects to product-lines and applications to more managable & re-usable services.
There are also many opportunities for incumbent vendors to start their own disruptions, or to adopt scripting languages and incorporate them into their platforms. There's already a trend to use Jython as an administrative scripting langauge in the BEA WebLogic community, for example.
Perhaps another way to look at the current environment is this: the past 15 years have seen developers as the driving force in what has pushed IT forward: first, the Windows developer base, second the Java developer base. I would claim that the open source movement has fragmented developer opinions so much between .NET, Java, and "scripting language du jour" that the next major disruption in IT will not necessarily be developer-led. There's too much cacaphony. I think it might be (for lack of a better term) "architect-led" or "infrastructure-led".
The focus on declarative configuration in modern frameworks (whether AOP or IoC or attribute metadata) is an indicator of this drive -- the next step is to disentangle the amount of knowledge requried to understand the chorus of frameworks and allow specialist roles to emerge, while an "architect" (in the "broad+deep developer" sense of the term, not the UML-junkie sense) ensures all the appropriate pieces are chosen, and the appropriate roles are filled by the people that can best do the work.
Anyway, the computing industry has a hard time accepting, en masse, a new platform or language technology. Java was the fastest adopted development platform in the history of computing for one reason: the Internet took off at that exact time. Before that, Windows was the fastest adopted platform because it was the first mass-market accepted GUI for PCs. It would take a major user-centred shift to bring about another language & platform revolution. Until that time, the cacaphony will reign.
July 26, 2005
New BEA releases
It's such a nice summer that I haven't been blogging much!
Just a brief note that BEA has released to GA both WebLogic Server 9.0 (Diablo) and AquaLogic Service Bus 2.0 (QuickSilver). Anyone in the web services or integration realms should be interested in looking at ALSB / QuickSilver, it's very exciting to me.
June 19, 2005
when i'm feeling down
When I've just about had it with open source religious fervor (about how I'm not a "tr00 Java 31337 h4x0r" if my dependencies aren't injected using Spring and if I don't use AOP for my business objects)... when wall street analysts continue to bash upon my employer's head with zeal... when another dev team goes down the path of voodoo instead of engineering... I remember:
The BileBlog hates everyone equally. And I feel much better.
June 04, 2005
On Consultants and Agile Methods
I caught one of Cedric's entries on XP. Cedric doesn't think XP is used that much, I think it is, though mostly through individual practice adoption. At least he's always maintained a professional, reasonably open attitude when discussing it. On the other hand, a few of Mike Spille's comments struck a nerve with me as being quite reactionary, thus I've written this entry.
In my experience, Agile methods are used widely, and on significant, mission critical projects. I joined BEA consulting recently; every project we lead (in my region, anyway) uses agile approaches to project tracking and prioritization and use many of the XP practices daily. These are projects that run large core systems for multi-billion dollar companies.
There is a disturbing trend among cynics that deride the work of Beck, Fowler, etc. and pan them as the worst lot of opportunistic consultants that have only worked on small scale projects. I think this is an ignorant and generally wrong position, based on a grain of truth. Beck and Fowler have created lasting, large-scale systems running in large enterprises. I personally am aware of some of their past systems, and I know people that maintain them to this day. The grain of truth is that for every Beck or Fowler, there are 50 consultants hawking Agile methods without really getting what they are, how to fit them to a context, and generally causing destruction and chaos in their wake.
These guys have have promoted and articulated some of the most important, practical, and highest impact ideas in programming over the past 15 years:
- de-emphasizing the role of inheritance in OO and emphasizing the role of protocol / interfaces
- applying Alexander's work on design patterns to software
- CRC cards (and responsibility-driven design, which was expanded and promoted by Wirfs-Brock)
- test-first development, etc.
- Tom DeMarco's Peopleware has been a classic for 2 decades
- Waltzing With Bears is IMHO one of the best books on managing risk available, along with Jones' Assessment & Control of Software Risks
DeMarco may not reflect Cedric's experience with software because of his product development focus. It certainly reflects my experience. DeMarco is from the enterprise IT crowd - particualrly defence, finance, and telecom. His discussion of how bad IT managers behave is on the money.
Now, I don't think XP is a complete software development method. It's a collection of very effective practices and a process "in the small". I actually feel the best modern book on software project management is Walker Royce's book "Software Project Management: A Unified Framework", which promotes a reasonably agile approach to the UP.
I've consulted, trained, and mentored people that build financial trading systems, customer information or CRM systems, billing systems, risk management systems, e-commerce sites, multi-terabyte data warehouses. And all of these, when I carried a leadership role, used agile practices -- including frequent releases, continuous integration, pervasive testing, variable priorities & scope, etc. They work well, if fitted to the appropriate context. Were they textbook XP? Of course not. Yet XP has had tremendous positive influence on my practices.
My view is that experience alone in the day-to-day pressures of a dev job does not give one the ability to reflect and think about the bigger picture. Some can, and make wonderful developers or team leads. But compared to many full-time developers, consultants -- by that I don't mean contract employees, I mean people hired to impart knowledge -- tend to have more available downtime to reflect. Thus, they can provide an important contribution. Of course, there are 50 useless consultants for every great consultant. But that's the same with programmers in general, and arguably even managers. It has nothing to do with how much time they spend on a system, there's still that 10:1 productivity ratio. The process, XP , or not, will not save you from a lack of knowledge or skills, or bad management. But it can save you from building the wrong system, or prioritizing the wrong things, or debilitating quality problems at deployment.
May 03, 2005
Jim Gray on the new database
In my prior entry on this topic, I discussed some of the trends shaping the "new" database paradigm, and how some of today's databases are starting to meet those needs -- it's just that people haven't taken the time to learn them.
There's a good article in April's ACM Queue magazine about the trends shaping the database world, and I particularly noted this quote that resonates with me:
Clearly, theres plenty of work ahead for all of us. The research challenges are everywhereand none is trivial. Yet, the greatest of these will have to do with the unification of approximate and exact reasoning. Most of us come from the exact-reasoning worldbut most of our clients are now asking questions that require approximate or probabilistic answers.
This is an area of tremendous interest for me, hopefully I'll find time to talk about it more.
March 10, 2005
Interop with SOAP and REST
Carlos Perez has a series of articles about why REST is apparently better than SOAP. This whole thing is quite confusing to me, as I wasn't aware they were in conflict -- REST-like architecture is doable in SOAP, as it is in XML+HTTP. Chris Ferris has pointed out a lot of the problems with this series.
It really seems to be an argument that XML+HTTP is sufficient for web services , while SOAP and WS-* are unnecessary and complex. Secondly, it seems to be an emotional rant against an invisible body of "SOAP proponents" that are seeking to destroy interoperability in their wake.
He starts out with the following:
object.method( arg1, arg2, arg3 );A collection of these methods is the typical starting point of a SOAP implementation.
Whoa, whoa, WHOA!? Perhaps in 4 or 5 years ago, this was true. SOAP and WSDL unfortunately had a lot of wrong turns in its early days, but they've been largely fixed through SOAP 1.2 and WS-I. So, I haven't seen this approach in a long while. The starting point of a SOAP implementation is to figure out what your XML looks like. Your basic invocation is more like:
object.method(document)
Because WS-I Basic Profile lists document/literal as the preferred style of communication. RPC/literal is also supported but I don't really know of any vendors or users that use it.
Now, a modern SOAP framework will dispatch to a method based on the document's root element. And it will allow you to take an incoming XML document and divvy it up into arguments. WebLogic Workshop does this with XQuery maps. At their most simple, we just apply an XPath expression to point to the section of the document that maps to a method argument. But we could transform any inbound document into whatever method signature and data binding you want. This certainly helps interoperability.
How do SOAP and REST differ? Assuming HTTP as the transport, REST has the intent of the document transfer associated with the HTTP method, effectively layering a uniform interface on top of your document. Why is this a good thing? To quote Roy Fielding's thesis...
By applying the software engineering principle of generality to the component interface, the overall system architecture is simplified and the visibility of interactions is improved. Implementations are decoupled from the services they provide, which encourages independent evolvability.
Sounds like a good plan. Now, with WS-I SOAP+WSDL (irrespective of transport), the document itself indicates the intent. You figure out what to do with it based on the document type and/or contents. Thus, it's tailored to whatever the application's specific needs are. Let's continue that quote from Roy:
The trade-off, though, is that a uniform interface degrades efficiency, since information is transferred in a standardized form rather than one which is specific to an application's needs. The REST interface is designed to be efficient for large-grain hypermedia data transfer, optimizing for the common case of the Web, but resulting in an interface that is not optimal for other forms of architectural interaction.
And here we come to the problem. Many people are trying to use SOAP and WS-* as a general suite of protocols, one that's applicable to many different kinds of architectural interactions. XML+HTTP "REST" style approaches tend to come from large web-site companies, because that's their business - large grain hypermedia data transfer. Not all systems have that pattern. They can, and probably should, create their own uniform interface, but it should be in whatever approach makes sense for THAT application.
It's becoming extremely tiresome listening to SOAP proponents continually shift the argument. I need to emphasize again, the only 3 valid reasons are "Interoperability, Interoperability, Interoperability".
Accusations of "shifting the argument" usually indicate that the author has no respect or understanding for the other party's perspective. Other quotes: "SOAP proponents are full of disdain for REST" (really?), "We all know that its all broke, so stop with the farce and reboot.", and "Sure you guys listened, but it was with contempt. Just as you continue to write in a contemptuous manner."
I think Carlos is mistaking contempt and disdain for REST with contempt for his line of argument. The tone and intent of this series of blog entries is not of education, or insight, or information, it's pure hubris -- he's trying to prove that he holds THE ANSWER. Hammers and nails.
In all of these pseudo-REST arguments, where WS-* is apparently jettisoned, I haven't seen any indication of how to meet requirements about security (including identity), intermediaries, routing, callbacks, integrity, etc. other than "you don't really need those features". Tell that to our clients. They are saying something very differently -- "yes, we do need that". Misguided souls, or enlightened veterens?
Like CORBA and COM, I think SOAP and WS-* will have their successes. As will XML+HTTP. Perhaps the latter will be more prevalent -- I would even HOPE so. But it's silly to turn this into some sort of religious war about SOAP. There are numerous SOAP successes today that are invisible to the blogosphere, because they're inside corporations. Millions, if not billions of dollars of transactions run through SOAP at this very moment. I've helped to build some of these systems. And everything I see , talking with CIOs and enterprise architects, suggests that more will come. Live and let live....
March 06, 2005
Expert One on One 10g edition sample chapters
Tom Kyte's Expert One on One: Oracle book is one of the best practical tech books available, in any topic. It was a real career changer for me. He's updating it for 10g, and the beta versions of chapter 1 and chapter 2 are now available. The final book is due by the end of the year. I'm giddy.
March 01, 2005
building the new database, pt 2
In my last entry on this topic, I discussed Bosworth's blog entry back in December calling for the "new database". In my opinion, the "new database" is perhaps a combination of three trends:
a. Emphasizing probability over logical certainty. This means fewer "queries" and more "searches" with ranking-based approaches. This, by and large, seems to be the fundamental shift underway to deal with infoglut, and it's the hardest one. It completely changes the notion of what a database is. It no longer primarily is a fact-base or 'oracle' (ahem). It becomes (mostly) a predictor, or statistician.
b. Convergence of search operations, logical set-operations, tagged data, and common programming languages. It's very difficult" to truly create good abstractions, and even then they still leak. In terms of data, I think this requires a fundamental change of language, though certainly we've tried and failed in this task many times. The closest I've seen to a truly elegant data/language unification is was with Gemstone + Smalltalk -- and I think it can be done again, better.
c. A separation of logical from physical data structures. Schemas change a lot, they're much more dynamic than the late 1980's. This means database vendors actually need to implement the relational theory as intended - where one can compose a physical data structure that does not necessarily map 1:1 to its logical structure, as almost all databases continue to do today.
I reject claims that XML databases will be the ascendent to the "new database" for many reasons that one can find elsewhere.
The above three trends are ideals that may take years to solve. But It's my belief that the "new database", in some respects, is already here, but culturally I don't believe most developers are capable of understanding it. I'm going to explore why I think this is, along with how today's databases solve the three general problems of a) dynamic schemas, b) massive scalability & data volume, c) better physical/logical separation. Each of these will be in a seperate part... let me lead off with a couple of comments on why we're in this predicament.
"If the database vendors ARE solving these problems, then they aren't doing a good job of telling the rest of us."
I think the database vendors are trying quite hard to solve these problems and communicate this. Browse through Oracle's marketing material.
"The customers I talk to who are using the traditional databases are esentially using them as very dumb row stores and trying very hard to move all the logic and searching out into arrays of machines with in memory caches."
And this is completely due to what I would consider closed-minded cultural / historical reasons. It has a seed in reality, back around, say, 1997, when databases weren't as clusterable or built for web access. And it is exacerbated by legions of database developers that haven't unlearned their bad habits from 1995. But it's unnecessary.
My observation is that all of the three major programming camps - .NET, LAMPW (Linux,Apache,MySQL,PHP/Perl/Python,Whatever), or Java - especially the latter two, seem to have an allergic reaction to relational databases, in all aspects. Relational theory & design is loathed, physical design issues are glossed over, and generally the attitude consists of covering one's eyes and yelling "la la la la la la" loudly whenever someone suggests that it might actually be useful to really learn this stuff in-depth.
Each camp seems to have its own neurotic view of the world -- whether being wedded to the one "true" database (SQL Server, MySQL, PostgreSQL, Oracle, or DB2) , or being an (object|XML) bigot and turning one's nose up at 30 years of database theory, or believing that databases altogether are a stupid idea.
There's a mix of Not-Invented-Here, hubris, fear, confusion, embarrassment, and a general lack of memory about the debates that took place through the 1980's and 1990's on this stuff. Gurus of yesteryear - Kent, Codd, Date, Darwen, Pascal, etc. - are relics to today's generation of Java and .NET programmers. People complain constantly about how difficult it is to understand XYZ database because it's so different from ABC database, when it would be clear why this is if they read the FINE and FREELY AVAILABLE online documentation for all of the major databases - Oracle, DB2, SQL Server, MySQL.
Oracle has been a FREE download for over 6 years, and people still don't experiment with it, they just fear it.
Databases are perhaps the most complicated piece of software in use, after an operating system. People spend time to learn operating systems in-depth at college. They don't usually get the same in-depth exposure to databases. Perhaps that's one of the problems? Or is there just a religious fervour in the air?
All of the arguments paraded around Wikis and mailing lists and blogs on the "right" data format and "relations vs. objects vs. XML" was hashed over 20 years ago, and sadly it seems the intellectual results of that debate are widely scattered in journals, books, and out-of-print articles. All that's left is the observation that relational databases (or "SQL databases") triumphed in the marketplace, while objects triumphed in the minds of developers. Network/object databases are a small niche, and a tremendously entrenched number of hierarchical / flat databases on mainframes continue to demonstrate the incredible power of IT managers who just. don't. care.
But these worlds - programming, data management, and data interchange - don't need to be in opposition to one another. They can be complementary. And hopefully someone will figure out to find their appropriate strengths and unify them into the next great programming environment.
February 11, 2005
online gaming nostalgia
Looking at one of the newest online game craze, which happens to be somewhat of a fantasy sport, made me think of the first online war-game I played: Modem Wars, by Dan Bunten. It was a two-player game where one person called the other with a 1200 baud modem to play a hybrid warfare/football game called "Sport of War". It carried many of the elements of today's Real-Time Strategy games like Warcraft 3 and Command & Conquer. You can download the documentation to Modem Wars along with a copy of the game for DOS. It's only 116k :-)
What's more interesting is the story around the creator of the game. The greatest selling computer game of all time is Will Wright's "The Sims". He dedicated it to Dani Bunten. Dan was the creator of M.U.L.E., and Seven Cities of Gold, both forrunners of Sid Meier's Civilization (which Dani claims she was going to write, but Sid got to it first). In the early 1990's, after the failure of his second marriage, he had a sex change and bacame Dani Bunten. (See the gallery at Dani's memorial page). Dani is considered one of the greatest game designers of all time. She died in 1998 from lung cancer. I highly suggest you read those links on above (especially the Salon article) if you are interested in computer games , and game history.
February 03, 2005
IBM vs Oracle in the TPC
The latest TPC-C benchmarks are an interesting war between Oracle's RAC vs. IBM DB2 on an SMP machine. A recent Usenet skirmish broke out on this, one that I feel the urge to echo here.
Benchmarks are rather useless for real-world comparison purposes, as all the machines are apples/oranges, but it makes for good entertainment. I liken it to a combination of horse racing (who will be fastest this time?), car stereo contests (stereos with bass response and wattage that could kill small animals), and fantasy football (what would have happened if XYZ conjectural system were used instead)?
I'm going to take the fantasy football route, briefly, because I'm a believer in clustering and am very interested in Oracle RAC.
IBM's p5 595 benchmark results: 3,210,540 tpmC, $5.19/tpmC.
Total 3-year system cost: $16.7m
Oracle/HP's Integrity rx5670 benchmark results: 1,184,893 tpmC, $5.52/tpmC
Total 3-year system cost: $6.5m
Even though both solutions are 64 processors, this can be deceiving. The HP benchmark is underpowered vs. the IBM benchmark in terms of cores, GHz, memory, cache, and spindles.
Let's even things up a bit before I get into differences. IBM's hardware is wonderful, IMHO, and the POWER5 rocks the Itanium2. So, let's put Oracle on an IBM POWER5 solution, say the p5 570.
A 4-way pSeries p5 570 is $94k USD on IBM's website.
The only TPC benchmark for the p5 570 lists ram at $108k for 32gb.
So:
16 x 4-way p5 570's with 8gb RAM and 72mb L3 cache each = $1.5m
64 x 32gb memory boards = $6.9m (2 terabytes RAM)
Subtotal: $8.4m
Less 47% Discount: $3.95m
Total: $4.45m for the CPU + Memory + Chassis.
Add another ~$500k for extras (Fibre channel HBAs, Interconnect, etc.)
Grand Total: $5m
That's $1.5m less than the $6.5m (discounted) for the p595.
So, assuming the same storage & client configuration as IBM's p595 benchmark, and maintenance on the p570 and p595 is a wash, all that's left is software -- Oracle+Redhat is $1.6m discounted, vs. AIX+DB2's $800k. So add $800k to the total.
That's still $800k cheaper than the p595 solution, with 128 GB more ram (2176 gb total) and double the L3 cache. The only open question is if the cluster would bring in similar TPCC figures as the SMP box. Hopefully the following analysis will convince you about HOW superior IBM's hardware is to HP/Intel's.
Now, let's look at the differences between the two ORIGINAL setups:
- Both had 64 processors. 1.9GHz POWER5 vs. 1.5 Ghz Itanium2.
- The POWER5 is dual core and hyper-threaded, so can execute 4 threads simultaneously.
- The Itanium is 1 core and not hyperthreaded.
- The POWER5 has 96kb L1 cache and 1.92MB L2 cache. The Itanium2 has 32kb L1 cache and 256kb L2 cache. That's 3x L1, and 87% more L2.
- IBM had OVER THREE TIMES the number of disk spindles - 6,400 x 36 gig Ultra320 hard drives vs. 2,000 (mix of 18gb and 36gb) in the HP solution. That's 240 terabytes (well, 120, assuming half are RAID 1 spares), folks, for a 24 terabyte database.
- IBM had 83% more L3 cache (36 mb/proc vs. 6 mb/proc). That's 2.3 GB of L3 cache, if you were counting.
- IBM had 2 TB of RAM, which is 62.5% higher than HP's 768 GB.
Now, my p570 solution is close to even with the above (which is, remember, $800k less), but with the following improvements:
- 128 GB more ram (2176 GB)
- Double the L3 cache (76 MB / proc), which is around 4.8 GB of L3.
Given all of this, especially that the POWER5's are dual core HT, I think there's a reasonable chance Oracle RAC would sing. But this is all back-of-the-blog calculations, so, YMMV.
Of course these numbers all belong in "green giant" land. L3 cache in the GB and memory in the TB, and while we're at it, disk arrays with thousands of spindles, only 10% utilized, that can aggregately transfer (conservatively) around 10 GB/sec (more if you had more FC cards & switches)? Or how about a cluster with 8 GigE interconnects, giving an ability to transfer around 1 GB/sec across the cluster nodes? Monster truck madness!
iPods seen in Redmond
This article is too funny, suggesting that iPod use is frowned upon at Microsoft, in favour of PlaysForSure WMA players.
This is a no-brainer, IMHO, though I find it hard to believe some of the numbers in the story. And I doubt Ballmer & Gates are sending memos out about it. Certain pro-Microsoft bloggers are denying or flat out blasting the article as b.s.
Perhaps parts of it are. But are those quotes and emails exchanged falsified? I doubt it.
In particular, this email exchange rings true...
Dave Fester, general manager of the Windows Digital Media division, ...: "I sure hope Microsoft employees are not buying iPods. We have great alternatives. Check out http://experiencemore."Fifteen minutes later, the manager responded: "I don't know what I was thinking. I'm sure that Microsoft employees are not buying iPods, or Macs or PlayStations."
I have a friend that recently joined Microsoft after coming from the J2EE side of things, and he's amazed at the insular thinking. Even Google use is frowned upon!
I have a lot of respect for Microsoft and their people. I use their products, though mainly on the Mac, and I think .NET is the best developer platform they've ever had. But if you scratch the surface, it's been clear that Microsoft's cultural goal these past few years, since the anti-trust case, is to break out of their insular mode of thinking -- one that favours economic lock-in as their main competitive weapon. And they've had some successes here -- the Indigo / Web Services "Interoperability" mantra, the standardization of the CLI and C#, etc.
But they've also had significant failures. I think the WMA / PlaysForSure initiative is one example of that -- on one hand, it promotes hardware interop, on the other hand it ensures Microsoft's lock on digital media. It's a faustian bargain. Going with WMA players is like getting locked into only using GM cars with vinyl interiors and unusable dashboard layouts. With the iPod I'm locked into a BMW Z8. Pretty obvious choice.
February 01, 2005
Building the new database, pt 1
Sometimes I just don't have time to keep up with the pace of conversation in the blogosphere. Perhaps because most of the members are pro-am pundits or journalists they can pull it off :-)
Anyway, related to this, I have a few thoughts brewing on that database debate that Adam Bosworth kicked off a few weeks ago, about how database vendors are providing less of what customers want, and open source could fill the gap. I also caught the radio show where Bosworth & co suggest there should be an easier way to do it than how we do it today.
Here's the nutshell, speaking as an Oracle DBA and one-time object database nerd. It really is hard. It will be easier, but the baseline of knowledge on how databases actually work is so _low_ out there, it's going to take a while. And in terms of specific features - dynamic partitioning and modern indexing, vendors like Oracle *are* providing these things, and they're not tremendoulsy hard to use, it's just that people don't bloody spend the time to learn them.
There's a cultural problem in the database community at work here -- there is too much emphasis on "operations" and not enough on "development" and "play". AskTom.oracle.com is probably the best example of a "DBA playground" , in terms of the attitude of information sharing and trying out ideas -- and is quite inspiring as to what one can do, very productively, with modern databases.
There's also confusion in basic assumptions of how one achieves scalability and reliability. If one's interested in this space, read (or re-read) In Search of Clusters for a feel of how this idea has evolved. There are many biases and perceptual challenges here. For example, Adam's use of the word "partitioning" already hints of a bias towards a particular style of parallelism (shared nothing), something that may be more applicable to Google's case than Federal Express' case. Few cluster architectures are "general purpose" to fit all cases (though Oracle argues that shared-disk and RAC are general purpose 'enough').
As for things like "dynamic schema", I am curious. Object databases like Gemstone provided this 10 years ago, and some companies , particularly Utilities and Container shipping companies, use schema evolution to great effect in their billling, routing, or trouble ticketing systems. But it wasn't enough for OODB's to catch on. Today, it's not a completely solved problem, but it's something that , for example, Oracle is working hard on. Every release they add new maintenance features that allow schema evolution without downtime -- first index rebuilding, then partition swapping, and now complete online table re-organization -- only with a quick table lock at the beginning and end of the operation. There's a whole discussion here about where should abstraction begin & end that I could get into (particularly about people that insist on building an abstract layer on top of their relational databases, which are already, guess what, an abstract layer on top of a filesystem).
Adam suggests that if these features do exist , vendors aren't explaining them or pushing them well enough. That may be true, but there's a deeper cause, I think. Generally I *do not* see these kinds of requests from most customers. They're having a hard enough time with 'static' requirements and techniques. Dynamic ones are too scary. Only the sophisticated customers, driven by deeply technical people, ask for these kinds of features. (These are the people one dreams of working for :)
Does Oracle listen to these people? Absolutely. The engineers know this stuff matters. But can they sell it in a marketing deck? It's a different audience. Perhaps that's why we don't hear about this stuff.
I'll expand on this in future.
January 06, 2005
Always learn C?
Joel Spolsky wrote a brief essay giving advice to software developers entering or attending college. I usually find Joel has an odd mix of very right and very wrong ideas. But one section particularly caught my attention as very wrong, and I decided to post about it.
...if you can't explain why while (*s++ = *t++); copies a string, or if that isn't the most natural thing in the world to you, well, you're programming based on superstition, as far as I'm concerned...
Right. Because programming is all about understanding pointer arithmetic.
This statement has nothing to do with CS, nothing to do with software engineering, nothing to do with digital design or assembly. This strikes me purely as "my language is better than your language" elitism.
I firmly believe in his general thesis: a great software developer pays attention to soft and hard skills. Software development is a continuum of skills: at one extreme, it's all about people -- at the other extreme, it's all about computer science.
However, the argument that the best programmers must know C idioms can be reduced to the argument that the best programmers must know (in depth) electrical engineering, digital design, or physics. Because otherwise, it's just superstition that the machine works!
In today's world, knowledge is the essential resource. It's more important to know how to organize your ignorance than to try to learn everything.
Abstract languages like Simula, Lisp, and Smalltalk completely changed the way we look at computer science. It brought the "people" element back into it - the need to think and communicate primarily at the level of the problem, not at the level of the machine -- but retaining the ability to drop down to machine level when necessary. Abelson and Sussman explained this shift in the preface to SICP, which I think is a good way to end this rant (highlights mine):
First, we want to establish the idea that a computer language is not just a way of getting a computer to perform operations but rather that it is a novel formal medium for expressing ideas about methodology. Thus, programs must be written for people to read, and only incidentally for machines to execute.Second, we believe that the essential material to be addressed by a subject at this level is not the syntax of particular programming-language constructs, nor clever algorithms for computing particular functions efficiently, nor even the mathematical analysis of algorithms and the foundations of computing, but rather the techniques used to control the intellectual complexity of large software systems.
[...]
Underlying our approach to this subject is our conviction that ``computer science'' is not a science and that its significance has little to do with computers. The computer revolution is a revolution in the way we think and in the way we express what we think. The essence of this change is the emergence of what might best be called procedural epistemology -- the study of the structure of knowledge from an imperative point of view, as opposed to the more declarative point of view taken by classical mathematical subjects. Mathematics provides a framework for dealing precisely with notions of ``what is.'' Computation provides a framework for dealing precisely with notions of ``how to.''
December 01, 2004
That's some fast sorting
Ordinal Software's NSort algorithm set the world sorting record earlier this year -- 33 GB read, sorted, and re-written in 59 seconds, and 1 TB read, sorted, and re-written in 33 minutes. Hardware was an NEC 32-way Itanium2 server with 128 GB ram, 8 QLogic Fibre Channel HBAs @ 2 Gb/sec, and 8 Eurologic SAN blocks w/ 14 disks (36gb / 15k RPM) each, 112 total.
It's designed for SMP or NUMA machines and is multi-OS. I'm curious if modern cluster interconnects (10 GigE or 10 Gb Inifiniband) could work with this approach, assuming one had the appropriate systems software.
October 04, 2004
interop vs. portability
A couple entries from Tim Ewald and Michi Henning.
This old discussion between Don Box and Michi from 1999 is particularly telling, as well. In hindsight, I think they were both right. Protocol-oriented interoperability is the right way to go, but code portability is nice, as the success of J2EE has shown. But in a market-based software development world you really can only focus on interoperability or portability -- not both, or else you'll get the two confused. Plus, QoS & productivity is all that vendors have to compete on! One could forsee an open source solution that gets both right, perhaps...
My experience in complex environment has made me realize the ineffectiveness of portability in many circumstances. For exampe, JDBC, ODBC, etc. all claim "database SQL portability", but in practise the differences between concurrency models, performance, and features between DBMS vendors is so large that "SQL portability" is quite useless for most interesting applications. Packaged software applications like SAP or Siebel are crappy database users for this reason -- they wrote generic SQL instead of tuned, specific SQL.
Secondly, I would say the whole reason Microsoft has jumped behind XML is that they've bit the interop bug -- they'll be a good citizen of IT from now on, but they'll be damned if they'll reduce your switching costs -- once you go .NET, you're stuck with .NET.
Thirdly: J2EE seems to have hit an interesting sweet-spot here. It's almost like it's gone down the path of SQL. You get decent (not perfect) portability, proprietary features are reasonably isolatable, and it richly supports the interoperability of XML. Now of course, vendors are adding features to the software stack that are non-standard, such as BPM, Portals, etc. But even there are JSRs awaiting these features, promising code-portability.
So for those people that care primarily about portability (BTW -- Do such people really exist? Can people really claim they care more about switching costs than functionality and productivity?), 90% vanilla J2EE will have to suffice. For those that care primarily about productivity, either LAMP, modern Java frameworks (i.e. BEA Workshop, Struts, JSF, PicoContainer, AspectJ, etc.) or .NET will suffice.
on WS-* standards proliferation
About a week or two ago, a blog wave was started regarding the increasing difficulty of keeping up with the web services standards process. Most blogphiles have probably read all this stuff, but since I don't post all that often, I'll make note of the highlights here: The release of WS-Transfer and WS-Enumeration, the initial salvos: Tim Bray #1, Mike Gunderloy, Simon St. Laurent, the rebuttals: Sean McGrath, Phil Wainwright, and Tim Bray #2.
Oh, and if you want to understand how all the WS-* specs fit together, Cabrera, Kurt, and Box have put together a whitepaper on it (very useful).
I'm still letting this digest. I've been pretty happy with the WS-* process -- some of these specs solve real problems, while some of them replicate solutions that already exist but in a transport-independent manner.
I'm struck by three observations, and opinions:
1. The dissenters mainly think that XML+HTTP (aka. REST) is enough. Let's be fair: add SSL to that for encryption / signature. And we don't have really interoperable authorization, just HTTP authentication here. Nor do we have any messaging semantics other than synchronous request/response. Granted, a lot can be done with this, but does this really make for good interop when we get into tougher situations? Let a thousand XSLT pages bloom to translate between different security, message correlation, and other plumbing issues?
2. Related to the above is that these specs haven't been fully baked -- some get deprecated before implemented, and we're not likely to see widespread (aka. Microsoft + 2 other vendors) support for these specs for months. It's dangerous to add complexity en masse, piecemeal is better.
I agree in general with this statement, but I'm not sure we're in a dangerous situation yet. I actually see the WS space undergoing piecemeal growth. We have the SOAP/WSDL/HTTP/SSL/XSD kernel today. Some use Relax-NG instead of XSD. That's pretty doable. Now, we're starting to seriously add WS-Security. Tomorrow, WS-ReliableMessaging will come. And then the others. I'm not sure how this isn't piecemeal. Perhaps because the specs are so widely viewable that it's confusing people. I always thought the specs were for specific audiences: leading-edge implementors and vendors -- not mainstream developers. If you're developing with XML+HTTP or SOAP today, and you're happy, what's the fuss? If you're not happy... well, is it a tool or protocol problem?
3. When I look at the specification page count that Tim and others put together, I'm struck by how FEW pages there are. At first glance 569 pages for XML, XSD, and base security specs seems a lot -- though out of this 409 pages are XSD, so perhaps the problem continues to be XSD vs. RNG & other simpler contract definition languages. Then there's 230 pages for the WS-Security family, which doesn't strike me as overly large considering how wide ranging the specs are.
Now then:
Only 21 pages for Reliable Messaging! 39 pages for transactions! This seems rather consise. For core plumbing, there's 111 pages for SOAP messaging from the W3C (which includes the primer and adjuncts, some of which cover miscellaneous / legacy techniques), and another 100 pages for things like events, REST-like transfer verbs, addressing, binary support, and UDP support. Again, not too bad.
I don't know what the fuss is. How big are these vs. the CORBA specs? How hard was this to understand in DCOM? How about any EAI vendor's reference manuals?
Once again, there are different audiences here. Most dissenters have probably never touched CORBA or EAI (though certainly some have and have lost hair from the experience :) and suggest no one should have to ever do that -- the internet proved everything can be done with HTTP! They may have a point, though I haven't been convinced it's applicable to ALL scenarios. The other audience wants web services as a better (more traceable, debuggable, maintainable) enterprise distributed system standard. To these people, there ARE legitimate reasons for these specifcations: some applications really do need standard eventing, some really do need asynchronous support (and hence addressing), reliablity, and a more sophisticated form of transactions than 1-phase "yay or nay". In my experience, anyway.
Perhaps these specs aren't actually going to solve these problems, and we should implement a widely adopted ad-hoc solution first before we trumpet out the spec. This is a good point and a reason why WS-* should be adopted with caution. But -- what else can one do? Use the older frameworks and have HTTP+XML or SOAP gateways for client-based interop. Server-to-server orchestration needs a one-vendor solution, whether Biztalk, WLI, or MQ Workflow. This seems to be the answer, for now.
August 13, 2004
on new languages
This is an essay based on a Slashdot post in August.
Paul Graham, inventor of Yahoo! Stores and LISP dude, suggests that great hackers program in Python. Naturally, chaos has ensued in the fanbase of other languages.
I think he's just promoting that developers learn more than one programming language. I can dig that. I don't agree with equating intelligence with choice of programming language. Things are harder than that, particularly in a large company.
In a general sense, there has been a long debate about whether language influences thought, or if all languages are independent of thought. In oral human languages, Steven Pinker would argue that language is an instinct, and doesn't influence thought -- it evolves from thought.
In computer languages, however, you're not just communicating. You're representing. Also note that computer languages are written langauges, not oral languages. Harold Innis and Marshal McLuhan have both shown that written languages do influence thought, particularly the western phonetic alphabet leading to a paritcular societal pattern vs. eastern pictographic languages.
Turning to computer languages, one could argue that if you've only been exposed to one way of "representing" a thought, say with Visual Basic 6 - you are limited in the boundaries you set up in your own mind about what's possible. Ideas like dynamic dispatch, inheritance, etc. are all foreign, unless you've been exposed to them in another language.
Or, on the other hand, you may be using a language like C with very few boundaries, but this doesn't help either -- there's a lot of freedom there, and not a lot of guidance about how to use it properly. I always find it interesting when C programmers defend their choice and suggest "but, you can do object oriented programming in C!". Well, of course you can! But it required another language, Simula, followed by Smalltalk, to generate the discipline and ideas around what object oriented programming really was. Could that paradigm have evolved without another language to naturally support it? It's possible, but somewhat unlikely.
Any Turing complete language could implement a programming paradigm, it's just a matter if it's natural to the language's constructs or if it requires more elaborate structures. For example, if anyone has programmed Microsoft's COM realizes that the underlying concepts are relatively simple, but the elaborate syntax for achieving it in C++ (prior to ATL especially) is ridiculous. In this light, .NET really is about bringing the level of language up to and beyond the semantics that Microsoft technologists already had with COM.
Nevertheless, there's still a practical problem with modern dynamic languages. The world has a legacy, and that legacy is large, chaotic, crufty, and not very dynamic. Getting a handle on it requires simplification, constraints, and classifications for the kinds of languages, tools, techniques, and platforms for the future. This is the main reason why languages like COBOL, C++, or Java stick around: we have to stick to something for a few years to simplify the system dynamics in the large. Picking "one standard" or "one vendor" is a key way of ensuring quality - by constraining and simplifying the business environment.
Java is clearly not a "thought leading" language like Python or Ruby , or even older languages like Lisp or Smalltalk. But that's not what it was supposed to be. Java was an "action provoking" language that took a very large C and C++ legacy of systems, skills, and mindsets, and pushed them forward an inch.
A lot of independent technical people may not agree with "constrainting" the environment, because it limits innovation. Modern dynamic lanaguages make life so much simpler for the programmer. And I agree they do. But there are levels of simplicity -- and organizational simplicty in the large often trumps simplicity in the small. We'll get there eventually, but it will take a while. Most enlightened organizations will have an emerging technology lab to bring this stuff in and socialize it.
Once a new language becomes mainstream, there is a tremendous host of supporting technologies that have to be built. In a large IT organization, no program is an island. Integration and interoperability rule the day. One of the reasons Java has been so successful is that it fostered a marketplace to support the rest of the morass of IT: database drivers, performance monitors, legacy adapters, transaction processors, application servers, web servers, graphics and reporting libraries, workflow and business process managers, etc. The Java world did this in around 4 years - by 1999 to 2000, the platform was ready for truly mission critical work.
The .NET marketplace, on the other hand, has not been so successful at building such supporting technology because of Microsoft's culture being the centre of the universe and master of all things. They'll get there, but remember that .NET was only generally available in 2002. They have at least another two years to get to where Java was in 2000 -- unless you're suggesting that .NET is growing faster than the fastest growing language platform in computing history (hint: it's growing, but not that fast).
Python, Ruby, etc. can all be mainstream pillars of IT, if you really want them to. But you have to build the supporting technology. This requires true organizations, -- whether for-profit like RedHat or not-for-profit foundations like Apache, to nurture and foster the supporting infrastructure: IDEs, tools, drivers, integration, etc. This has been done before. Java arguably is where it is due to the efforts of the Apache and Eclipse foundations.
Beyond this, there's a challenge to universities to keep teaching these dynamic languages in earlier years. Students complain incessantly about learning Scheme, Lisp, or whatever in 1st year. And perhaps they're not ready for it. Or perhaps the professors are way too concerned with the mathematical aspects of those languages and less with actually "getting things done" in them. But we need to broaden the minds of our forthcoming software developers. Sadly, I don't see this trend going well. As with most professions, ours is increasingly technocratic and specialist, with little room for "learning several languages", especially those with very different semantics from the mainstream.
If there's a message from PG, it's this: Learning multiple languages helps improve your skills, but primary language choice does not necessarily indicate intelligence.
January 25, 2004
BEA foot-in-mouth
So, Ben Renaud, deputy CTO of BEA, says in a recent article that Microsoft needs to work better on API standards vs. protocol standards, because "The real level where integration happens is at the programming level".
One view is that if this is BEA official position, they've missed the cluetrain. Clemens and Don share this view. Note that Ben Renaud apparently now claims its a misinterpretation, but I'd still like to talk briefly about this point.
I think this deputy CTO really may just have a case of misinterpretation or foot-in-mouth by confusing "integration" with "portability". BEA and IBM are building a lot of stuff above the standard J2EE stack, so this kind of ideological struggle was bound to occur.
J2EE is interesting because it lowers the cost of portability between platform vendors. It also arguably lowers the costs of training and education for server-side developers. This is a similar approach to SQL and relational databases - you really need people that know the database, but it doesn't need to be everyone because of the SQL standard.
On the other hand, the Microsoft of the past, present, and future, is set on convincing developers that Windows is the best environment to write software, and then keeping you there. And they're good at it. The MAJOR change in Microsoft's approach since .NET was released was that they no longer are playing the integration / interoperability lock-in game, as far as one can reasonably tell.
What makes Microsoft's view so appealing is related to what Don said in his entry: APIs are the real lock-in. In the end, if you choose J2EE, you're locked into the Java language and Sun/JCP's vision of the world. With Microsoft's approach, you're locked into their car, but you have a really good view and can roll the windows down. With J2EE's approach, you can hop between cars, but you're still stuck in the same parking lot.
So perhaps this article really shows that BEA has some political ties it's struggling with. Indigo is a radical re-think of how to best implement a distributed system. J2EE 1.5 arguably needs a similar re-think, particularly at the EJB level. The JCP members, like BEA, have the opportunity to do something good, or to serve the entrenched interests.
On the other hand, browsing around dev2dev and talking to BEA techies, I really do think they get the benefits of protocol-based interoperability. It's just a matter for their public faces to be clearer about it.
January 14, 2004
autonomous services
I contributed a somewhat lengthy article, Autonomous Services and the New Information Architecture to the new blog/community site TheServerSide.NET. It's about web services, architecture, and how it differs from distributed objects. Let me know what you think. Apologies for it being somewhat abstract.
November 04, 2003
PDC: architecture
So it took a few days for me to get settled back in Toronto after my 3 month stint in Tokyo. I have a few things I'd like to say about the PDC Architecture Symposium that was on Friday.
The morning talks by Pat Helland and David Campbell were two of the best talks on architecture I've heard, period. It was an excellent analysis of the troubles facing enterprise architects today and tomorrow with the advent of "internet scale services". It was also a talk by seasoned veterens who aren't buying this "SOAs everywhere, death to objects" rhetoric we see floating out of various groups from time to time. I'll discuss this in a moment.
The final panel discussion on "What is Service Oriented Analysis and Design?" really didn't seem to have a coherent message. I noticed most of the applause went to Martin Fowler, who had the most pragmatic message: services are about distributed systems integration. Gartner seemed to see it as a way of creating some kind of new "composite application". One other panelist saw SOA's everywhere and even wanted their mouse driver to be a service. I think this might be a case of the classic cognitive problem "when you have a hammer, everything looks like a nail".
Pat Helland's talk was full and I barely had room to stand outside to watch the slides and listen. The general sense of the talk was his service master/agent (aka. fiefdoms/emissaries) model of services & data that he's been working on for some time).
Data is divided broadly into 4 categories: resource data (i.e. volatile "state of the business" data), activity data (i.e. private to a business process) , reference data (i.e. versioned/timestamped data), and request/response data (the stuff inside messages).
Services are divided into two groups: service-masters (resource-data and activity-data, high concurrency, pessimistic locking), and service-agents (activity-data only, optimistic locking, low concurrency).
What really impressed me was that they have created some very workable categories for types of data and a way to structure your system to start to reason about the "bounded uncertainty" necessary when dealing with widely distributed large-scale systems. Traditional distributed systems are "local" and "trusted" - they can use guaranteed techniques such as two-phase distributed transactions for agreement. Internet-scale systems unfortunately can't rely on these guarantees because transaction isolation typically implies locks, and locks imply denial of service. So, the idea is to use asynchronous communication, durable queues, and compensations to deal with this uncertainty. This is effectively how sites like eBay and Amazon.com scale.
David Campbell's talk also spoke about the role of the different forms of data out there: relations, XML, and objects. He spoke highly of object persistence (object/relational mapping) within service-agents for activity-oriented data, relations for resource-oriented data, and XML for data that requires multiple-combined schemas (i.e. extensibility), such as for request-response messages that need to evolve over time. I really want to review the powerpoint slides for this talk, because it went by quite quickly, but they're not online!!! Pat Helland's talk seems to be online, thankfully. I guess I can wait for the DVD...
October 28, 2003
First reflections on the PDC
So here's my interpretation of the information revealed at the PDC thus far. This round, I'm going to list my view of Microsoft's "goals" and what this could mean for alternative frameworks / vendors.
In my opinion, some of Microsoft's goals are:
a) In the enterprise, information-based applications rule: traditionally they have been VB applications, lately they have been web applications, some are even Java/Swing applications. One of Microsoft's biggest battles has been to hang on to that client-layer lock-in that is continually eroded by web applications, and is the #1 reason why Linux is even considered a palatable alternative in the enterprise: develop on the Web, deploy anywhere (in theory). Develop on Windows, you must deploy on Windows.
Longhorn's goal: Fuse together Windows development (XAML) and Web development (ASP.NET), so the two are fundamentally the same set of development tasks - the differences are relatively trivial, except that Windows applications will be richer.
By doing so, it won't be much effort to convince people to use the rich application features of Windows. It's an old story, but it makes sense: keep providing the path of least resistence to your system, and make it compelling. That will slow the tide.
I notice a lot of developers drooling over XAML, and it looks very pleasing, but the idea is fairly predictable, and has popped up in a number of locations: it's an evolution of the traditional notion of "GUI setup as resource file" vs. "GUI setup as big init() method". The evolution looks like a promising one.
b) Indigo's goal: Unify all the disparate Windows communications / enterprise technologies (Transactions/MSMQ/SOAP/Serialization/etc) into a common and SIMPLE framework that's competitive with J2EE. Allow extensibility at every point and make every feature dependent on an open specification (the WS-* specs).
Some would say .NET is ALREADY competitive with J2EE, and I would agree with that in terms of ASP.NET vs JSP/Servlets. But I think Indigo is necessary to make it competitive with JMS/MDB's. There already are large services-oriented archtiectures out there based on JMS, MQSeries, and J2EE, and this is in fairly mainstream financial institutions (and a certain telecom company seems to be moving in that direction). Microsoft needs to provide an alternative to this model unless they want to see J2EE retain its lock on the server.
Anyhow, this has been long a goal for Microsoft, and I'm glad it's finally here. I was suspecting this was what Indigo would be, and I'm pleasantly surprised that it's looking like a very simple model. I will be attending some of the Indigo sessions today to get a more in-depth glance.
Indigo continues Microsoft (and IBM's) approach of "changing the game" and "leading the charge" in writing the "new distributed computing standard". Microsoft and IBM still have the upper leg here because they control the key specs thus far (until WS-I takes them over).
A lot about Indigo and consequentially, WS-*, is about re-creating CORBA after 10 years of experience: the protocol must not make assumptions about the execution environment's structure or process model for any particular feature: (e.g. session-oriented security vs. message oriented security, object orientation and inheritance of interfaces, etc.) The specifications in CORBA made too many assumptions and made implementation too difficult for that reason.
In the autonomous computing / web services world, the protocol is all that exists, and all that you can rely upon.
Another interesting observation: If Indigo is released with Longhorn in 2006, it will be released around the time of J2EE 1.5 and EJB 3.0. That makes for an interesting competitive situation, considering Sun's goal for J2EE 1.5 is "ease of use". Hopefully this rivalry will benefit all developers in the long run: it certainly has improved Microsoft's offerings by an order of magnitude, in my opinion. I hope Sun will get over its current identity crises and step up to the plate.
I also would hope some in the OSS community will step up and start thinking about a similar model for non-Java oriented systems. I've heard lots of posturing from some folks about this, but nothing of substance yet.
c) Yukon's goal: (well one of them) -- bring business logic back into the database. And unify caches among tiers.
In allowing .NET languages inside the database, this fixes a long standing problem: logical 3-tier out of necessity has had to be physical 3-tier, because our databases have not supported the rich languages and frameworks we use to write our business logic. When running through reams of data across the tiers, this is can lead to slow, unscalable applications, only fixable by placing an (unacceptably high) amount of logic into stored procedures / T-SQL or PL/SQL.
Of course, for scalability reasons, not EVERYTHING should be in the database, but a lot of business logic is validation logic and needs to be as close as possible to the data.
Assuming C# flys through data as fast as T-SQL, this will hopefully give Oracle the kick in the pants to speed up its Java integration in the database, or at least provide some sort of integration solution between the application server and the database.
And hopefully Oracle will provide a cache dependency feature between the database and application server: it's frustrating that after years of EJB users asking for this, it took Microsoft to come up with it first (in beta at least)!
More to come...
October 24, 2003
eBay and the PDC
So I had a little scare earlier this week, my contract here in Tokyo was getting extended, and I figured I may have to give up my PDC pass... but I didn't really know anyone that wanted it personally (Floyd at TheServerSide.com briefly wanted it, but found somone else!).
So I tried to put it up on eBay. After over 2 days of no bids, I figured I would just work the weekend here and fly in to LAX on Monday (out of Tokyo at 4:30pm Monday, into LA at 8:45am. Figure that one out).
But then I received at least 3 emails from people that were going to bid on the item! AND two journalists wondering if I've sold it. Lesson to the wise.. in most eBay auctions it's good to wait -- except when the person has a bunch of hotels and flights to reschedule and is worried when there aren't any bids. Please, no requests to put it back on eBay, my mind is set now :)
But, I can't complain, I have really been looking forward to this conference, it is but only the next step in my Cunning Plan to straddle several technology worlds - J2EE, .NET, and Oracle, and open source...muhaha
October 05, 2003
more on ORM vs. stored procedures
Some comments on an interview with Gavin King from hibernate.
October 02, 2003
SOA in the context of EJB
I notice that Microsoft is largely trying to change the rules of the game for enterprise development by jumping onto the "services oriented architecture" bandwagon and making web services as the only way of doing SOA, and that SOA is something "new".
But most of these blog posts I see about SOA are all things I've seen written 4 to 5 years ago about EJB stateless session beans (and recently message driven beans).
Replace "data transfer object graph" with "XML document". I think I prefer the XML document for various reasons (interop + the new security services), but it's a fairly small change to the conceptual architecture because you typically bind the document to an object graph!
There are still many hard problems in distributed computing that aren't being solved by SOA and it's frustrating to see yet another community so excited about something that really isn't changing the world AS MUCH as they think it is, just like the EJB camp was in 1997... :-)
September 28, 2003
September 27, 2003
select count(*) is not slow
a recent post I saw on comp.databases.oracle.server ....
From: Billy Verreynne
> Can someone tell me what's fast way to get total of records in a table
> except using "select count(*)" statement? Can I get the information from a
> system table?
Fast? You mean something like this:
SQL> set timing on
SQL> select count(*) from tjs_batch.prod_sapcallusage200304;
COUNT(*)
----------
78277166
Elapsed: 00:00:06.49
SQL>
This is a straight cut-and-paste from a telnet session. The 6 seconds
will go down to 4 or even 2 seconds when run again as the applicable
bitmap index used will be cached.
So what's your reason for not wanting to use SELECT COUNT(*) or
thinking its slow?
One thing that really makes me reach for my lead pipe, is Oracle urban
legends Andy. Like thinking a SELECT COUNT(*) is slow, that standard
Oracle database's uptime is much less than that of the server it runs
on, that Oracle requires constant administration and a host more or
other silly tales.
--
Billy
monoculture
The Register has a good editorial on the cybersecurity paper that got Dan Geer fired from @Stake.
I thought this was the highlight of the piece, it seems to grasp the root of the argument:
"To summarise, monoculture itself is not of necessity bad for security, nor in theory is Microsoft monoculture, provided Microsoft is prepared and able to reform itself. If however it is not, then the Microsoft monoculture is a clear and present danger to global IT security, and it must be reformed via external means.
That is the document's argument, and it's a perfectly sustainable one, albeit not entirely susceptible to being boiled down into a headline soundbite."
You know, for all the controversy surrounding this paper, a couple of things come to my attention. Firstly, Bruce Schneier is a co-author - a rather respected security expert. Secondly, the idea of software diversity to increase the reliability of a distributed system is not a new one.
Security is in many ways a sub-section of general reliability. Gray and Reuter's bible on Transaction Processing has a section on N-Version programming as an approach to software fault tolerance: the idea is that "Heisenbugs" (non-deterministic, non-repeatable bugs vs. deterministic, repeatable "Bohr-bugs") can be thwarted by different pieces of software doing the same job at once.
On architecture
Someone recently asked me what architectural approach I liked... a few names were thrown out: Rechtin, Fowler/Cockburn, and Malvaeu/Mowbray (Software Architect Bootcamp).
I respect most of these authors. But there are a lot of problems with "architectural schools of thought". Many assume that "THEY" have the answer. Building big software systems is a lot more complex than that, and it's hard to have a cookbook approach. I find it's hard to come up with a step-by-step model, or "design by checklist".
Therefore I tend to like the "framework" approach to architecture -- one that doesn't dictate steps and realizes that situations differ.
I don't believe in "big architecture up front".
I think there's a fair amount of things that can be discussed up front, but I also believe architects must be involved with the team doing the building, at least for a significant part of the project.
I also don't believe in "UML is the key".
UML is useful in the right business context: you have a team that wants to use it and a culture that values "ceremony" for various reasons (geographically distributed teams, separate maintenance teams, etc). By "ceremony" I mean deliverables that aren't actually executing software, but bubbles and lines on a piece of paper -- it's Alistair Cockburn's term.
Financial companies tend not to value ceremony, I find. They're obsessed with time to market. Telecom companies, on the other hand, love ceremony.
Finally, I'm a believer that "architecture must have context".
Your software system is just a part of a larger organizational system (Alistair Cockburn would say it's a co-operative game within a larger political game). People, culture, management, and skills are first-order success factors - much more so than technology platform and software process.
Perhaps I have a broader view of systems architecture than most. But if you take systems thinking to its logical end, you have to be able to look totality of the system in its context. Its context is yet more systems! An architect can't just focus on technology, because then they're ignoring 2/3 of the system surrounding the technology!
To me, an architect is the bridge between business, people, and technology. Architecture cannot merely be about technology, because then it's just engineering analysis without context (building something right, but not building the right thing). But architecture can't just be about business, people and politics, because then you're not actually building anything.
Here are the most useful categories (with authors and thinkers) on architecture, in my opinion, from high level to low level.
a) Conceptual. I think Zachman framework captures this.
b) Context. I would look at Gerald Weinberg's work on systems thinking and congruent action. Systems architecture is inside a larger context of people, change management, and politics.
c) Process. The most balanced approach is Alistair Cockburn's work on productivity to determine the right process "fit" for your project. How much "ceremony" do you really need -- do you need to write a bunch of thick documents or can you just throw 10 people in a room with a whiteboard and code?.
What does process have to do with architecture? Lots. How you choose to build your software has a tremendous impact on how you specify it. Do you hand down UML models from upon high (not recommended!). Or is it an oversight role?
d) Requirements analysis This is about understanding how to break a problem apart and understand what should be solved in software systems, and what should be solved with changes to human systems. This is a form of "business architecture" (along eith (e)). Here, I like Michael Jackson's work on "problem frames", Gerry Weinberg's work on "ambiguity", Cockburn's work on "use cases", and Kent Beck's work on "user stories")
e) Information modeling. Many authors here: William Kent, David Hay, Terry Halpin, Chris Date, Bill Inmon, Ralph Kimball....
f) Evolutionary / agile development (Martin Fowler's Refactoring, Tom Gilb's work in the 1980s, and Kent Beck's XP writings) help keep the architecture in sync with the development.
g) A software performance engineering (SPE) process should be run concurrently with the main development process. I really liked the treatment in this book.
h) Finally, Computer Science.
At the highest levels, software systems architecture is all about people. At the lowest levels, software systems architecture is all about computer science. Since these are simultaneously the hardest areas in software development, most people tend ignore both (and focus on "design patterns", or a specialized platform).
I like to revisit the classics often: Gray & Reuter's book on Transaction Processing, for example. Another implication , to me, is that systems should take a scientific approach to their development in the small (XP'ers would call this a "spike solution"): don't make blind assumptions, test your hypotheses!
All of these means a very STRONG sense of healthy skepticism and pragmatism. Don't try to "fill every box" of the Zachman framework with a separate document , or to deliver a UML model for every piece of the system, but make sure you're addressing all of the various concerns in some (however informal) way.
Understand:
A) what you're building (end-state),
B) in what business context (funding, priorities & culture),
C) in what domain (people, concepts, information)
D) with what functional requirements,
E) with what environmental requirements (performance, scalability, availability, platforms)
Some might say this is too much, and way too complicated. Actually, I'm not advocating much other than to pay attention to the reality around you -- it's just that I'm breaking down reality into classifications. That tends to highlight problems that we traditionally put into a black box labelled "here there be monsters".
September 25, 2003
.NET mysticism and Java productivity
Saw Ole's blog entry on how many of the new .NET technologies are being presented as cool, or even mystical as part of the hype gearing up for the PDC.
Don Box alluded to this idea before as well - controlling surface area requires a significant shift in attitude for people who thrive on complexity.
This resonates with me. I've always viewed the Microsoft technology culture as one that thrives on complexity. (i.e. COM put the COM in COMPLEX). .NET seems to have changed attitude quite a bit, at least perceptually. I hope it sticks, its why I'm interested in .NET after generally avoiding Microsoft technologies. I taught several of those 2-day Microsoft seminars on .NET in 2002 while I worked for Infusion, and I quite enjoyed talking to the developers I met about their concerns and excitement surrounding the framework.
On the other hand, I think Java's initial enormous popularity had a lot to do with its fall-over simplicity. Parts of J2EE seemed to really lose that. I think it's because distributed / parallel / concurrent development actually is quite naturally complex, and no one yet (save for perhaps David Gelertner's Linda) has come up with an elegant general solution to it. To me, elegance is Einstein's paradoxical statement - be as simple as possible, but no simpler.
On another note, before people start rampantly quoting Greenspun's theory that Java/JSP costs 5x more than a project in Perl as fact, remember this wasn't based on any facts, studies, or experiments - it was a number pulled out of the air for rhetorical purposes. I've made comments on this before on Slashdot, but in a nutshell, I think Java certainly CAN be as productive as Perl, the question really becomes whether the horde of consultants and "experts" actually encourage this or not, and whether the myriad of framework choices help or hinder this.
The problem to me seems to be the J2EE community got run over by the "design patterns" idea, where many inexperienced developers-turned-consultants decided that every project needed design patterns to make their systems more maintainable. They lost sight that usually less code == more expressivess == more maintainable. This as opposed to "pretty UML bubbles and lines" == more code == $$.
This is why the .NET PetShop was such an embarassment, in my opinion. It was faster, smaller, and my observation: it wasn't that you COULDN'T write something that small & fast in J2EE (as much as some may like to imply) - it was that no one wanted to! "BUT BUT - stored procedures are hard to maintain and proprietary! Proprietary bad!" That's knee-jerk dogmatism, that's not objective thinking about software design!
If a beginner was pointed in the right directions with truly productive modes of working in Java, I think there's a good comparative story. It's what I try to do when I teach, I move away from the Sun-standard J2EE marketing stuff and look at what real people do to get productivity.
It's a sad and ironic tale: a community so prided on simplicity has so lost its way, and it's taken Microsoft to point this out.
Liebermann computers
What do people make of this? Despite the fluffy market babble, it does look like an impressive set of specs. The company seems very new and I can't find any information on them on Google, which is strange.
September 22, 2003
java = suv?
Phil Greenspun suggests that Java is the SUV of programming languages. The link is Slashdotted, here's the post at slashdot, and here are my comments.
Developer communities and the PDC
I'm getting pretty excited about my first Microsoft PDC this October. I'm not knee-deep into the Microsoft community so I find their developer culture rather fascinating because I used to be a member of the J2EE community.
Today I find myself not relating to any community (I jump among the OO, distributed systems , relational , J2EE , .NET , and Oracle worlds) ... they're all way too religious. I'm not one to suggest the trite cliche' that "platforms are just tools", because I think emotions and emotional motivations are very important in one's work. I just don't tend to attach the same emotional importance to what these communities hold valuable, at the moment.
That may change: The .NET community has a lot of vibrancy and is very appealing. As for the other communities: The J2EE community, while vibrant, is rancorous, fractured, and extremely political. The Ruby community is wonderful but I'm not sure I'll get a chance to really use it. I'm not sure there is a relational community anymore, and the distributed systems community seems to be either Web Services geeks or researchers that have been grudglingly silent since the web services trend took off. The Oracle community has some of the most experienced IT folks I've seen, but they all seem to have fallen down the path of cynicism (and it's very tempting given the amount of crap passing for "systems architecture" these days in the J2EE world). The open source community (well, the Slashdot community) is very fractured, very political, and doesn't actually get a whole lot accomplished. I still have a soft spot for this community, as I've been a Slashdot member since near the beginning - 1997 (I'm user #1311, and I was the lucky 10 millionth hit.). But these guys remain so politically ineffectual and naive that I feel a constant struggle between my frustration at their (sometimes) childishness and my continued desire to be involved.
Anyway, back to the PDC... things that interest me in this conference: SQL Server Yukon (I want to see where it's going vs. Oracle 10g), the mysterious Indigo, some of the architectural sessions on Service Oriented Architecture, and the latest .NET techniques for Web Services ... I'm not really there for the client stuff, though Longhorn probably has a lot of goodies inside it.
Going to a Microsoft developer conference with a Powerbook is going to raise some eyebrows. I may upgrade my Powerbook to the new 1.33Ghz model if the trade-in price is right... (I have a 1ghz 17-inch right now, with 1 gig ram). I think the new one might give me an extra boost to run VS.NET 2k3 on Virtual PC, though I'm not sure if the lack of L3 cache will cause problems. Its not my primary platform (yet) so I don't mind it too much, but I definitely would want a real PC laptop or desktop to do day-to-day .NET development.
September 14, 2003
windows media
I've been finding it rather frustrating that most streaming video resources on the web seem to be moving away from Real media to Windows media. Real sucks, but it's cross-platfrom. This media is usually MPEG-4 but Microsoft has managed to take the standard and wrap it in the proprietary ASF or WMV format if you use Microsoft's video tools.
So players like Quicktime can't get at the content. Now to be sure, a lot of downloadable content is Quicktime - but not a lot of streaming content outside of movie trailers. This is weird considering the streaming server is FREE, but I guess it's another one of those IT-dept stigmas against Apple, not to mention I know a lot of Windows users that don't like QT player.
Microsoft's been trying to take over digital media for years, and they may actually to be starting to make some headway, though at the expense of a lawsuit from Burst, the creator of some of WMP9's technology. The is of course some evidence of dirty tricks like email withholding. Microsoft... guys... you're big. I use your software when it's good. So then, why do you have to continue to be a cheat?
Anyway, back to the topic.... Macintosh Windows Media Player 7.1 has been out for some time, but most new content is being ripped with verison 9... And since version 9 was supposed to be about Microsoft's take-over of all digital content I figured it would only be for Windows. AT LAST, RELIEF: Windows Media Player 9 for OS X has been announced as "coming soon!". I'm not sure whether to laugh or cry. I don't want to use it as I'm quite happy with the quality of QuickTime or pure MPEG, but if the content is in it.. do I have a choice? (well yes, i could choose not to view the content. That's not a palatable choice, however.) sigh.
September 06, 2003
design for performance
I've been most influenced by Tom Kyte to think in this direction. Here's my wiki page.
August 31, 2003
why distributed computing?
why is distributed computing such a big deal? My focus here is for enterprise computing systems, not internet based systems. The dream of distributed objects and "n tier" architectures was to have all of these services floating around. I was a huge proponent, it's probably what made me want to be a programmer. Today I'm asking - why? WHY do they need to be distributed?
Why can't they be co-located? Can we not design things that distribute because there's an actual reason behind it other than politics?
The over-complexification of software is continuing its takeover of our enterprise systems. Why can't we take the simple solution to XYZ problem by writing 10 stored procedures, wrap it with a SOAP service, and call it a day?
I see way too many systems that require physical component seperation if they're going to get any logical seperation. (A client I'm dealing with now has this problem: dozens of CORBA services, an EJB cache, an MQSeries-based bus, a JMS-based bus somewhere else, and pieces of C++, Java, and .NET code everywhere. All on, literally, hundreds of physical servers costing millions of dollars. The amount of hardware resources being squandered is staggering for what piddly performance they get.
Greg Pfister, author of In Search of Clusters, had a "standard litany" of "why go distributed". Scalability was the big buzz word, though I rarely see any systematic analysis of scalability beyond a few load-test scripts on any particular island in the distributed system - rarely on the end-to-end distributed system itself. Pfister's main point is still correct: the reason we don't have scalable & reliable clusters is that the clustering software still sucks. And yet we think our enterprise developers can do a better job than the cluster vendors. In our enterprises, we only have clustering software on the "islands". We don't leverage it in a larger sense by recombining our logical components into cluster nodes and designing the distributed system in a truly co-ordinated manner. (What's fascinating about this is that Gartner actually predicted this trend -- that we'll cobble our own approaches vs. taking a vendor's clustering approach to a large scale).
So here's my theory: It seems that many developers and architects need that physical split to wrap their heads around logical separation of concerns.
We've seen this kind of mental block for years in other areas of software: the need for physical libraries vs. logical modules. The inability for people to see data as "set oriented" and requiring pointer-based access to data, or to use a cursor to access data one-record-at-a-time. There are other examples.
All of these islands based on "skill sets" pop up here and there. I've seen it happening with CORBA - you have a C++ island here, a Java island there, etc. Now we have a .NET island somewhere else, a MOM island that bridges to CORBA, and an EJB cache that talks CORBA and MOM, with a bridge on the MOM that talks XML. It's all of these little "skill set islands" being deployed out into the enterprise without any attention paid to the fundamental problems with such an approach: tremendous complexity in debugging, latencies between each component that limit scale, and reliability concerns because each island can fail independently, has their own recoverability mechanisms, and the most planning I've seen is the "hot standby" + a DR site per island. Usually it's just a cron job that restarts the failed process. This is staggering! Though perhaps this "distributed shanty town" actually is what enterprises really want. I guess time will tell, if the reliability problems bite them enough economically. Thus far, I'm skeptical. Look at the current virus problems endemic on the web, especially with certain e-mail systems. What are people doing about them?
My feeling is that we're going to see service outages and tremendous scale problems in many enterprise systems. I hope I'm wrong. I hope that the relability concerns I see are really just an overreaction to the changing economics of software development, and the "shanty town" approach is really just the emergence of a new "ecosystem".
Now Microsoft has adopted this model of the "interoperable island" as their way of touting Windows in the enterprise, which is a good thing in a way. In the past, you were locked in the Microsoft world and couldn't talk to anyone else. Today you're still locked in, but now they're happy to let you talk to others.
So .. as Gerry Weinberg once said, once you solve problem #1, you're the one responsible for promoting problem #2. Problem #1 was to eliminate platform & language religion from distributed interoperability. Problem #2 (in my mind today) was pushing distributed computing for systems that didn't need to be distributed. Thus non-technical reasons such as divergent skill sets and the inability for develoeprs to make a logical/physical mental split became the rationale behind such designs.
We deserve it, I guess.
Maybe this is a good thing: the evolution of a "city plan" based approach to IT architecture, in Gartner's terms. The manager in me thinks it's probably a good thing. The technologist in me is frightened, because the only way I've seen end-to-end systems problems solved is by someone that could see the whole picture - forest and trees - and fix the problems locally. That's a rare quality... and something I see lacking: true architectural guidance that doesn't wind up being the hated "design cops".
sometimes it's better to keep quiet
Instead of posting my thoughts, sometimes I think it's better for me to shut up and watch the fireworks. I find after I post any longish post or rant, I change my mind after I hit "send". Sigh.
Ok, so after my longish post to TSS about web services, I read Werner Vogel's excellent Web Services are NOT Distributed Objects. This is indeed the first time I've seen someone that's been a part of the dist-obj community in the past actually take this position, so I'm quite interested in what he has to say. I'm wondering if this will change my mind about what I said just a few hours ago...
At first I thought "great, just when I thought I had it figured out, my paradigm's going to have to shift". After reading the article though, I think it resonates with me that most of what he says is stuff I already believed. But it did change my mind about some things, in a sense. It reminded me about stuff that I've kind of forgotton that I knew a couple of years ago, but mired in the practicalities of day-to-day technology, I had forgotton.
I do believe web services are different from distributed objects. I've detailed in other places what I felt web services to be, and that page hasn't changed much in the 2+ years since I wrote it, so I think it's still relevant. My view of the differences are primarily a) intrinsic message structure vs. dependence on an extrinsic definition language, b) thus the web services "document" model is a lot more like a dynamically interpreted interface (DII / IDispatch / RMI+Reflection) than a traditional static dist-obj interface in the CORBA/COM world c) and it's not based on any object model at all, so we don't have to worry about platform religious wars.
Werner takes the perspective of the old "stateful vs. stateless" debate. Web services are stateless at their base level he says, whereas distributed objects (COM notwithstanding) are stateful. Granted. I have, however, been somewhat biased by practice here: stateless EJB session beans tend to be the norm as entry points into today's distributed object systems.
As for "document oriented computing", while I've believed this is important, I've seen a lot of mixed messages here from various parties, so I've been kind of confused about what it means. It seems to me that every vendor is hell-bent on retrofitting RPC on top of web services as if that was the end goal. I've seen a few fairly influential articles from old COM folks that were very eager to make Web Services as static as COM/CORBA. On the other hand, Microsoft .NET has almost totally embraced the doc+literal model, which is good. Perhaps I just stayed out of the web services front-line discussions for too long and there was a switch at some point among these types, but I don't think so -- I'd also like to note that the other major platform vendor out there dropped their messaging-oriented web services API (JAXM) to focus on JAX-RPC. That's a very sad thing, and I wonder if it will hurt Sun in the long run. But on the other hand, I do admit, programming for JAXM is more painful than JAX-RPC given current tools, but perhaps JMS will subsume what JAXM was.
One thing I hear a lot, and Werner's essay echos this, is that "document exchange" is very different from "object interfaces". At the core, I suppose this is true. But, as I go around training people in J2EE, EJB, .NET, and Web Services, I try to find a way to relate the approaches. How is "document exchange" really different from traditional message passing, specifically the self-describing messages of some products like TIBCO RV?
The way I've taught it is as such: take your object interface, and reduce it to one method: void execute(Object) or Object execute(Object). (Or, alternatively, look at it like you would a JMS MessageListener: void onMessage(Message). Or like any other MOM-based system where you get a callback). The object coming in and going out can be an object graph (bound to XML through some mapping), or a DOM tree, or a pipeline of SAX events - the idea is to take the "surface area" of your interface and place it into your data. With only one physical entrypoint, the data itself can map to further logical actions and/or events - multiple schema instances in the same message. All of this is fairly fuzzy, but it's the general direction I've been thinking. I've always seen WSDL as a "crutch" technology - it's a way of hacking up a document into procedures & arguments, but it doesn't necessarily imply "RPC". But perhaps I'm wrong on this, I know there are many that view WSDL as essential (perhaps they're just subscribing to the RPC uber alles school).
I do take Werner's points on lifecycle to heart. That's one area I haven't paid a lot of attention to. What use is a create() method on a stateless session bean? There is none!
And then there's the actual document's data representation, which is something nobody really talks about that much. Is XML's data model really appropriate for most uses? Where does it break down, or become too complicated? Isn't it just hierarchies all over again - aren't relations still "the thing"? I remember sitting in a BearingPoint/KPMG briefing on EAI a few months ago and listening to one of their chief architects wax poetic about the cognitive studies IBM did in the late 1960's about the "folding" of data being a natural way that humans perceive and deal with information, and it's "interesting" how XML relates to that, that we may be going full circle back into a more hierarchical or network view of data. I wonder. I've become a bit of a relational/Oracle nerd in the past year thanks in part on one hand to a well-known troublemaker and on the other hand, someone who is probably the most inspirational technologist I've come across (in terms of the ability for one man to master his speciality), Tom Kyte.
A lot of this distributed computing stuff ignores that you could do a lot of commercial processing pretty cheap and fast on a relational database by just slapping the XML API's on top. Oracle's done a nice job with this, I've seen examples where it takes only a few of lines of code to expose a fairly large Oracle system to RSS or SOAP. From the theoretical side, Pascal and Date have been having troubles with this XML hype wave because it further drives the need for a complete implementation of the relational model out of the mainstream.
Werner mentions versioning as a key problem. This is something I've really found a dearth of discussion on. Some refer to namespaces as a versioning mechanism, but I've heard others vehemently oppose such an idea. A session at JavaOne 2003 proposed a mechanism that leveraged UDDI, which struck me as similar to how we do it today with MOM, distributed objects and LDAP.
Versioning should be fertile ground for innovation, XML effectively eliminates the need for "positional" semantics in messages which was problem with static dist-obj RPCs - adding extra elements or tacking other schemas onto a document should be a lot easier in the XML world. A couple of problems (being naive here): the pervasive use of the xsl:sequence ensures there is ordering to elements (does there really need to be?) .. furthermore, do people really design their schemas to be flexible (i.e. allow any namespace attribute or element to be tacked on in spots?) I see some evidence of this, but I doubt the discipline will be there in the mainstream.
Anyway, this has gone on for too long, but getting back to my original reason for writing this: in the end, I don't really think I've changed my mind too much about what I said about Don's stuff on SOA. Though now that I read his blog I realize that he was quoted out of context (silly me, should have known). I think web services are different than distributed objects, but SOA really is just distributed component based development in new clothes with some more flexible underpinnings. Perhaps I'll change my mind tomorrow. :-)
August 30, 2003
SOA vs. OO
Don box says that Service-Oriented Architectures will defeat Object Oriented ones. This is a bit of a fluff piece, but I really respect Don, I learn a lot from him at times. Here are some of my comments on this article.
August 28, 2003
if you think harder, your code will be better
some comments on John Carmack's latest programming efforts.
August 24, 2003
Monoculture
Computing monoculture. Makes a lot of sense in light of the MSblaster worm et al recently.
Apple has class
Apple has class. It's probably one of the main reasons I use their software. I mean, they're a flawed company, but there's something about using a product that makes you feel better for using it.
Anyway, here's my latest example. They replaced their front page with a tribute to Gregory Hines for around 2 or 3 days a few weeks ago.
{kind=link}
Of course you could say this is crass commercialism taking advantage of emotions over someone's death. But in this case, Hines was an avid Mac user (he was an "AppleMaster", or registered celebrity mac user) so it makes sense.
Here's the link to the tribute.
July 21, 2003
proprietary is not always bad
I wrote this piece for TheServerSide.com last week, a result of a post that got a wee bit too long. I was reading some of TheServerSide Symposium reports and noticed a lot of the "all standards, all the time" attitude being passed on there, so I decided to provide a counterpoint.
Based on the positive comments I've seen on my piece, it looks like I wasn't as alone in this line of thinking as I may have thought. I'll try to be more divisive next time.
June 25, 2003
the G5 benchmarks
All right. The G5's look great, but the benchmark debacle is just beginning. First, Apple posts benchmarks. Then, they get debunked. Then an Apple VP responds, and the original critic responds to it (under "Reply to Apple's Reply").
It can make your head spin, but my take on it is:
a) Apple didn't really cheat. All benchmarks tend to be controversial because they try to bend the machine configuration to deal with the benchmark programs. Furthermore, the original SPL's soapbox critique was flawed. I think it's reasonable to observe this guy is a couple of tomatoes short of a thick paste: complaining that pricing a product at $2999 is "deceptive", mistaking the -sse compiler options, and causing a whole-lot-of-useless whinging over the use of Hyperthreading (which doesn't always work as advertised).
Here's what he had to say about mistaking the SSE2 compiler options: "The situation here is unclear. I originally said that Apple/Veritest had disabled SSE2 for FP, thereby crippling FP performance. After further investigation, it seems I was mistaken about this particular point. "
Akshally, the situation is quite clear - he spoke too soon.
b) The use of GCC is deservedly controversial. I'm not sure I agree with the argument of "may the most optimised compiler win". Part of me sees the merit in that, but part of me sees Apple's choice to "normalise" compilers as reasonable (if naive).
Most users shouldn't be looking at the SPEC benchmarks anyway, they're measurements of theoretical CPU capacity. The informal application benchmarks are probably more "real world", and they're impressive.
JavaOne coverage
I contributed to TheServerSide.com's coverage of JavaOne, if anyone's interested... I also have extensive notes from all of the sessions I attended, though I haven't quite figured out how to get some of my code & tag examples to show up properly here, so I think I'll refrain on posting the rest.