February 02, 2008
Big data is old news
July 2016 Update: Restoring from backup, but for some reason the only backup I have is from 2008. Egad. Will try to find a newer one. In the meantime, you can read how misguided I was about Big Data eight years ago...
I continue to think the trend towards treating the RDBMS as a dumb indexed filesystem is rather ridiculous. So, here's a rant, coming from an old Data Warehousing guy with an Oracle Certified Professional past, who also happens to be a web developer, distributed systems guy, etc.
Witness the blogosphere reaction to DeWitt and Stonebraker's recent critique of MapReduce. I thought Stonebraker's critique was spot on. Apparently I'm the only person in my Bloglines list that thought so.
A major complaint is that people seem to think Stonebraker missed the point that MapReduce is not a DBMS, so why critique like it were one? But this seemed obvious: there is a clear trend that certain developers, architects, and influential techies are advocating that the DBMS should be seen as a dumb bit bucket, and that the state-of-the-art is moving back to programmatic APIs to manipulate data, in an effort to gain scalability and partition-tolerance. Map Reduce is seen as a sign of the times to come. These are the "true believers" in shared nothing architecture. This is Stonebraker's (perhaps overstated) "step backwards".
My cynical side thinks this is the echo chamber effect -- it grows in developer circles, through blogs, conferences, mailing-lists, etc., self-reinforcing a misconception about the quality of what an RDBMS gives you. From what I've seen on the blogosphere, most web developers, even the really smart ones, have a complete lack of experience in understanding a) the relational model, and b) working with a modern RDBMS like Oracle 10g, MS SQL 2005, or DB2 UDB. And even practitioners in enterprises have a disconnect here (though I find it's not as pronounced). There clearly are _huge_ cultural and knowledge divides between developers, operating DBAs, and true database experts in my experience. It doesn't have to be this way, but it's a sign of our knowledge society leading to ever-more-specialized professions.
Now, to qualify my point, I completely understand that one has to make do with what one has, and come up with workable solutions. So, yes, de-normalize your data if your database doesn't have materialized views. Disable your integrity constraints if you're just reading a bunch of data for a web page. But, please let's remember:
- massively parallel data processing over hundreds or sometimes 1000+ nodes really _has_ been done since the 1980's, and has not required programmatic access (like MapReduce) for a long, long time -- it can be done with a SQL query.
- denormalization is appropriate for read-mostly web applications or decisions support systems. many OLTP applications have a mixed read/write profile. and data integration in a warehouse benefits from normalization (even if the queries do not)
- modern databases allow you to denormalize for performance while retaining a normalized structure for updates: it's called a materialized view.
- many analysts require very complicated, unpredictable, exploratory queries that are generated at runtime by OLAP tools, not developers.
- consistency is extremely important in many data sets. It may not require it for all cases. There definitely is a clear case to relax this in some cases to eventual consistency, expiry-based leasing & caching, and compensations. But, generating the aggregate numbers for my quarterly SEC filings, even if it involves scanning *billions* of rows, requires at least snapshot consistency across all of those rows, lest you want your CFO to go to jail.
- data quality is extremely important in many domains. Poor data quality is a huge source of customer dissatisfaction. Disabling integrity constraints, relaxing normalization for update-prone data, disallowing triggers & stored procs, etc. will contribute to the degrading of quality.
- Teradata has been doing massively parallel querying for almost 25 years (1024 nodes in 1983, the first terabyte DBMS in 1992 with Walmart, many hundreds of terabytes with others now!).
- Oracle's Parallel Server (OPS) has been out for almost 17 years. Real Application Clusters is OPS with networked cache coherency, and is going to be 7 years old this year.
- Take a look at this 2005 report of the top Data Warehouses. This is a voluntary survey; there are much larger systems out there. You'll notice that Yahoo! was running a single node 100 terabyte SMP warehouse. Amazon.com is running a couple of Linux-based Oracle RAC warehouses in the 15-25 terabyte range since 2004.
The point is that there is no magic here. Web developers at Amazon, eBay, Youtube, Google, SixApart, Del.icio.us, etc. are doing what works for them *today*, in their domain. There is no evidence that their solutions will be a general purpose hammer for the world's future scalable data management challenges. There's a lot more work and research to be done to get there, and I don't think it's going to primarily come out of the open source community the way it did for the Web. Sorry.
Look, I think products such as MySQL + InnoDB, are fantastic and even somewhat innovative. They give IBM, MS, and Oracle a big run for their money for many applications.
On the other hand, *no* open source RDBMS that I'm aware of has a general purpose built-in parallel query engine. Or a high-speed parallel data loader. But, if it isn't open source, it doesn't seem to exist to some people. I can understand why ($$ + freedom), though I think usage-based data grids will greatly reduce the first part of that challenge.
It's been 3 years since I discussed (here too) Adam Bosworth's "there are no good databases" blog entry. I felt that many of the problems he expressed have to do with the industry's vociferous ignorance, but I did agree there was room for innovation. The trends towards Column-Oriented DBMS seems to be playing as expected, encouraging innovation at the physical layer. I still haven't seen a good unification of querying vs. searching in general databases yet -- they still feel like independent islands. But, if anything, the vociferous ignorance has gotten worse, and that's a shame.
So, what's the trend?
- Much of the limitations of RDBMS' have nothing to do with the relational model, but have to do with an antiquated physical storage format. There are alternatives that are fast emerging. Take a look at the latest TPC-H benchmarks. Between ParAccel and EXASOL, not to mention Stonebraker's Vertica, there's a revolution underway.
- I do think parallel data processing will graduate out of its proprietary roots and become open source commoditized. But this is going to take a lot longer than people think, and will be dominated by commercial implementations for several more years, unless someone decides to donate their work (hint).
- I think the trend will be towards homegrown, programmatic data access and integrity solutions over the coming years, as a new generation re-learns data management and makes the same mistakes our parents made in the 1960's and 70's, and our OODBMS colleagues made in the 1990's. Whether this is maintainable or sustainable depends on who implemented it.
- I think the Semantic Web may actually turn out to be the renaissance of the RDBMS, and a partial way out of this mess. RDF is relational, very flexible, very partitionable across a column-oriented DBMS on grid, solves many of the agility problems with traditional schema and constraints, and simplifies some aspects of data integration. The obstacles will be: making it simpler for everyday use (eliminating the need for a degree in formal logic), and finding organizations who will make the leap.
January 30, 2008
Relations in the cloud
I've been hearing a lot about how the RDBMS are no longer appropriate for data management on the Web. I'm curious about this.
Future users of megadata should be protected from having to know how the data is organized in the computing cloud. A prompting service which supplies such information is not a satisfactory solution.Activities of users through web browsers and most application programs
should remain unaffected when the internal representation of data is changed and even when some aspects of the external representation are changed. Changes in data representation will often be needed as a result of changes in query, update, and report traffic and natural growth in the types of stored information.
I didn't write the above, it was (mostly) said 38 years ago. I think the arguments still hold up. Sure, Google and Yahoo! make do with their custom database. But, are these general-purpose? Do they suffer from the same problems of prior data stores in the 60's?
Certainly there's a balance of transparency vs. abstraction here that we need to consider: does a network-based data grid make a logical view of data impossible due to inherent limitations of distribution?
I'm not so sure. To me this is just a matter of adjusting one's data design to incorporate estimates, defaults, or dynamically assessed values when portions of the data are unavailable or inconsistent. If we don't preserve logical relationships in as simple a way as possible, aren't we just making our lives more complicated and our systems more brittle?
I do agree that there's a lot to be said about throwing out the classic RDBMS implementation assumptions of N=1 data sets, ACID constraints at all times, etc.
I do not agree that it's time to throw out the Relational model. It would be like saying "we need to throw out this so-called 'logic' to get any real work done around here".
There is a fad afoot that "everything that Amazon, Google, eBay, Yahoo!, SixApart, etc. does is goodness". I think there is a lot of merit in studying their approaches to scaling questions, but I'm not sure their solutions are always general purpose.
For example, eBay doesn't enable referential integrity in the database, or use transactions - they handle it all in the application layer. But, that doesn't always seem right to me. I've seen cases where serious mistakes were made in the object model because the integrity constraints weren't well thought out. Yes, it may be what was necessary at eBay's scale due to the limits of the Oracle's implementation of these things, but is this what everyone should do? Would it not be better long-term if we improved the underlying data management platform? I'm concerned to see a lot of people talking about custom-integrity, denormalization, and custom-consistency code as a pillar of the new reality of life in the cloud instead of a temporary aberration while we shift our data management systems to this new grid/cloud-focused physical architecture. Or perhaps this is all they've known, and the database never actually enforced anything for them. I recall back in 1997, a room full of AS/400 developers were being introduced to this new, crazy "automated referential integrity" idea, so it's not obvious to everyone.
The big problem is that inconsistency speeds data decay. Increasingly poor quality data leads to lost opportunities and poor customer satisfaction. I hope people remember that the key word in eventual consistency is eventual. Not some kind of caricatured "you can't be consistent if you hope to scale" argument.
Perhaps this is just due to historical misunderstanding. The performance of de-normalization and avoiding joins has nothing to do with the model itself, it has to do with the way the physical databases have been traditionally constrained. On the bright side, column-oriented stores are becoming more popular, so perhaps we're on the cusp of a wave of innovation in how flexible the underlying physical structure is.
I also fear there's a just widespread disdain for mathematical logic among programmers. Without a math background, it takes a long time for one to understand set theory + FOL and relate it to how SQL works, so most just use it as a dumb bit store. The Semantic Web provides hope that the Relational Model will live on in some form, though many still find it scary.
In any case, I think there are many years of debate ahead as to the complexities and architecture of data management in the cloud. It's not as easy as some currently seem to think.
January 14, 2008
Shared, err, something
From (the otherwise great book) Advanced Rails, under Ch. 10, "Rails Deployment"...
"The canonical Rails answer to the scalability question is shared-nothing (which really means shared-database): design the system so that nearly any bottleneck can be removed by adding hardware."
Nonsensical, but cute.
This seems like a classic case of Semantic Diffusion. It's funny how people find a buzzword, and latch onto it, while continuing to do what they always did. "We're agile because we budget no time for design" -- "We're REST because we use HTTP GET for all of our operations" -- "We're shared nothing because we can scale one dimension of our app, pay no attention to the shared database behind the curtain, that's a necessary evil".
A shared nothing architecture would imply:
- each Mongrel has its own Rails deployment with its own database
- that database had a subset of the total application's data
- some prior node made the decision on how to route the request.
...And we don't always do this because some domains are not easily partitionable, and even so, you get into CAP tradeoffs wherein our predominant model of a highly available and consistent world is ruined.
Now, I know that some would ask "what about caches?". The "popular" shared-something architecture of most large scale apps seem to imply:
- each app server has its own cache fragment
- replicas might be spread across the cache for fault tolerance
- the distributed cache handles 99% of requests
- what few writes we have trickle to a shared database ( maybe asynchronously)
Which does help tremendously if you have a "read mostly" application, though it doesn't help reduce the scaling costs of shared writes. Good for web apps, but from what I've seen (outside of brokerages) this has not caught on in the enterprise as broadly as one would hope, except as an "oh shit!" afterthought. Hopefully that will change, where appropriate, but recognize that these caches, whether memcached, or Tangosol, or Gigaspaces, or Real Application Clusters are about making "shared write" scalability possible beyond where it was in the past; it doesn't mean you're going to scale the way Google does.
Here's one of Neil Gunther's graphics that shows software scalability tradeoffs based on your data's potential of contention, or your architecture's coherency overhead:
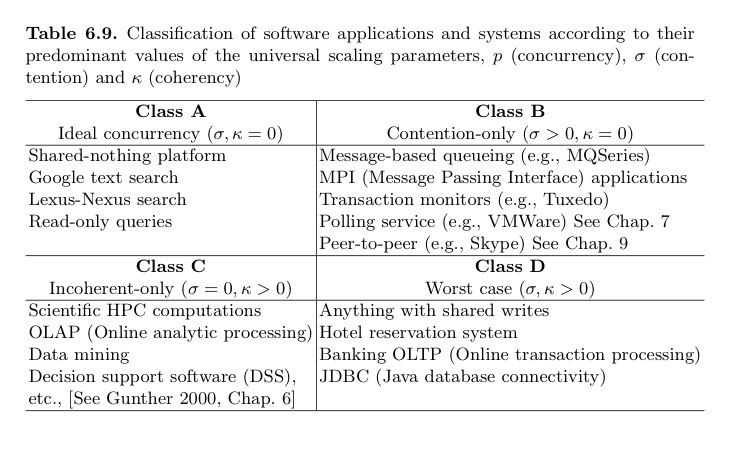
The universal scalability equation is:
C(N) = | N 1 + σN + κN (N − 1) |
Where, for software scale, N is the number of active threads/processes in your app server, σ is the data contention parameter, and κ is the cache coherency-delay parameter. Read the Guerilla Capacity Planning Manual for more details, or pick up his book.
I like this model, but there are some caveats: Firstly, I don't quite understand why Tuxedo is in Class B, yet OLTP is in Class D. Secondly, Class D's examples are so high-level that they may be misleading. The real problem here is "shared writes", which can be further broken down into a) "hotspots", i.e. a record that everyone wants to update concurrently, and b) limited write volumes due to transaction commits needing durability.
Having said this, this model shows the fundamental difference between "Shared-Nothing" and our multi-node, distributed-cache "Shared-Something". Shared-nothing architectures are those that have near-zero contention or coherency costs. Whereas shared-something is about providing systems that enhance the coherency & contention delays for Class D software, but doesn't eliminate them. They're helping the underlying hardware scalability, but not changing the nature of the software itself.
For example, write-through caching, whether in Tangosol or in a SAN array's cache, for example, can help raise commit volumes. Oracle RAC has one Tlog per cluster node, also potentially raising volumes. Networked cache coherency eliminates disk latency. But the important thing to recognize is that the nature of the software hasn't changed, we've just pushed out the scaling asymptote for certain workloads.
Anyway, let's please call a spade a spade, mm'kay? I just don't like muddied waters, this stuff is hard enough as it is....
January 03, 2008
The good in WS-*
Ganesh:Believe me, it would greatly clear the air if a REST advocate sat down and listed out things in SOAP/WS-* that were good and worth adopting by REST. It would not weaken the argument for REST one bit, and it would reassure non-partisans like myself that there are reasonable people on both sides of the debate.I'll bite. I'll look at what I think are "good", what the improvements could be in a RESTful world, and what's actually happening today. My opinions only, of course. I will refrain from discussing those specs I think are bad or ugly.
The good:
WS-Security, WS-Trust, and WS-SecureConversation
What's good about them?
- They raise security to the application layer. Security is an end-to-end consideration, it's necessarily incomplete at lower levels.
- Message-level security enhances visibility. Visibility is one of REST's key design goals. REST should adopt a technology to address this.
- It's tied to XML. All non-XML data must be wired through the XML InfoSet. XML Canonicalisation sucks.
- WS-Security itself does not use derived keys, and is thus not very secure. Hence, WS-SecureConversation. But that's not well supported.
- WS-Trust arguably overlaps with some other popular specs. Some OASIS ratified specs, like WS-SecureConversation, rely on WS-Trust, which is still a draft.
- For WS-Trust and WS-SC, compatibility with only one reference implementation is what vendors tend to test. Compatibility with others: "Here be dragons".
- SixApart has mapped the WSSE header into an HTTP header
- We could use S/MIME. There are problems with that, but there is still reason to explore this. See OpenID Data Transport Protocol Draft (key discovery, and messages) for examples of how this would work.
- One challenge that I have not seen addressed yet in the REST world is the use of derived keys in securing messages. WS-Security has this problem: reusing the same asymmetric key for encryption is both computationally expensive and a security risk. WS-SecureConversation was introduced to fix this and make WS-Security work more like SSL, just at the message level. SSL works by using derived keys: the asymmetric key is used during handshake to derive a symmetric cryptographic key, which is less expensive to use.
I recall Rich Salz, almost 3 years ago, claiming that an SSL-like protocol (like WS-SecureConversation) could not be RESTful because it has state. This isn't entirely true; authorization schemes like HTTP digest require server-side state maintenance (the nonce cache) and we don't seem to complain that this breaks HTTP. (Digest interoperability itself is often broken, but that's another story). REST stores state in two spots: (a) on the client, and (b) in resources. So, the answer seems to be, ensure the derived key (and metadata) is identified by a URI, and include a URI in the HTTP header to identify the security context. Trusted intermediaries that would like to understand the derived keys could HTTP GET that URI and cache the result. You'd probably have to use an alternate authentication mechanism (HTTP Basic over SSL, for example) to bootstrap this, but that seems reasonable. I'd like to see the OpenID Data Transport Protocol Service Key Discovery head in this direction.
WS-Coordination and WS-AtomicTransaction
What's good about them?
- Volatile or Durable two-phase commit. It works across a surprising number of App servers and TP monitors, including CICS, Microsoft-DTC (WCF), and J2EE app servers like Glassfish or JBoss. It will be very useful to smooth interoperability among them.
- It needs more widespread deployment. People are making do (painstakingly) with language-level XA drivers when they need 2PC across environments, so it may take a while for WS-AT to gain traction.
- Most of my problems with WS-AT are problems that apply equally to other 2PC protocols. I list them here because they will become "promoted" in importance now that the vendor interoperability issues have been solved with WS-AT.
- Isolation levels & boundaries. As I've mentioned in my brief exchange with Mark Little (and I'm sorry I didn't continue the thread), I think there will be lurking interoperability and performance problems. For example, isolation boundaries are basically up to the application, and thus will be different for every service interface. Like XA, the default isolation for good interop will likely be "fully serializable" isolation, though it's not clear that a client can assume that _all_ data in a SOAP body would have this property, as there might be some transient data.
- Latency. Like any 2PC protocol, WS-AT is only viable in a low-latency environment like an intranet, and specific data items cannot require a high volume of updates. A typical end-to-end transaction completion involving two services will require at minimum 3 to 4 round-trips among the services. For example, given Service A is the transaction initiator and also is colocated with the coordinator, we have the following round trips: 1 for tx register, 1 for a 'read' action, 1 for a 'write' action, and 1 for prepare. If your write action can take advantage of a field call, you could reduce this to 3 round trips by eliminating the read. The number of trips will grow very fast if you have transaction initiators and coordinators that are remote to one of the participating services, or if you start mixing in multiple types of coordinators, such as WS-BusinessActivity.
Here is a latency-focused "when distributed transactions are an option" rule of thumb: be sure any single piece of data does not require transactionally consistent access (read OR write!) any quicker than ( 1 / N*d + c ) per second, where N = number of network trips required for a global transaction completion, d is the average latency between services in seconds, and c is the constant overhead for CPU usage and log disk I/O (a log write is usually required for each written-to service + the coordinator). If you exceed this rate, distributed transactions will hurt your ability to keep up. This rule does not account for failures & recovery, so, adjust for MTTF and MTTR...
An example best case: In a private LAN environment with- 0.5ms network latency (i.e. unsaturated GigE)
- "write only" transaction (3 trips) from Service A to Service B
- a "c" of 3 disks (coordinator, service 1, service 2) with 1 ms log write latency (which assumes a very fast write-cached disk!)
- Availability. Again, this isn't really WS-AT's fault, as this problem existed in COM+ and EJB before it, but WS-AT's potential success would catapult this into the limelight. Here's the sitch: Normally, if you enroll a database or a queue into a 2PC, it knows something about the data you're accessing, so it can make some good decisions about balancing isolation, consistency, and availability. For example, it may use "row locks", which are far granular than "table locks". Some also have "range locks" to isolate larger subsets of data. The component framework usually delegates to the database to handle this, as the component itself knows nothing about data and is usually way too coarse grained to exclusively lock without a massive impact on data availability.
In WS-land, a similar situation is going to occur. WS stacks tend to know very little about data granularity & locking, while DBMS do. So, most will rely on the DBMS. Yet relying on the DBMS to handle locks will defeat a lot of service-layer performance optimizations (like caching intermediaries, etc.), relegating most services to the equivalent of stateless session beans with angle brackets. This doesn't seem to be about what SOA is about. So, what's the improvement I'm suggesting here? Service frameworks need to become smarter in terms of understanding & describing data set boundaries. RESTful HTTP doesn't provide all the answers here, but it does help the caching & locking problem with URIs and ETags w/ Conditional-PUT and Conditional-GET.
- Firstly, there's the question of whether it's possible to have ACID properties across a uniform interface. The answer to me is: sure, if you own all the resources, and you don't care there is no standard. With standard HTTP/HTML hypermedia, one just has to bake support into their application using PUT/POST actions for boundaries. Picture any website with an "edit mode" with undo or confirm, and you've pretty much enabled the ACID properties. Unfortunately, each site would have a non-standard set of conventions to enable this, which hurts visibility.
- Enabling a standard (visible) protocol for REST across different resources might be possible; Rohit has sketched this out in his thesis for 2-way agreements (i.e. the REST+D style), which is effectively a one-phase commit, and for N-way resource replicas (i.e. the ARREST+D style), and he also showed how the implementation would fit into the current Web architecture. We're already seeing his work popularized. Anyway, for a distributed commit, one possibly could extend the MutexLock gateway to support snapshot isolation, and also act as a coordinator (moving this to a two-phase protocol). But the caveats above apply -- this would only be useful for REST inside an intranet and for data that is not very hot. You still would require a Web of Trust across all participants -- downtime or heuristic errors would lock all participating resources from future updates.
WS-Choreography Description Language
What's good about it?
- It's an attempt to describe functional contracts among a set of participants. This allows for bi-simulation to verify variance from the contract at runtime. Think of it like a way to describe expected sequences, choices, assertions, pre & post-conditions for concurrent interactions.
- I think that the world of computing gradually will shift to interaction machines as a complement to Turing machines, but this is going to take time. WS-CDL is very forward thinking, dealing with a topic that is just leaving the halls of academia. It may have been premature to make a spec out of this, before (complete) products exist.
- See this article for some interesting drawbacks to the current state of WS-CDL 1.0.
- WS-CDL is tightly coupled to WSDL and XSDs. It almost completely ignores Webarch.
- Not much, that I'm aware of.
Security Assertions Markup Language (SAML)
What's good?
- Federated security assertions for both web SSO and service-to-service invocations.
- Trust models based on cryptographic trust systems such as Kerberos or PKI.
- Both open source implementations and vendor implementations.
- It doesn't have a profile to take advantage of HTTP's Authorization mechanism; this is because browsers don't allow extensibility there. It's not a deal-breaker, it's a smell that goes beyond SAML (browsers haven't changed much since Netscape's decisions in the 90's).
- It assumes authentication is done once, and then stored in a cookie or a session. To be RESTful, it should be either asserted on each request, or stored in a resource, and the URI should be noted in an HTTP header or in the body as the reference to the assertion (similar to OpenID).
- While the actual Browser profiles are generally RESTful, the API for querying attributes, etc. is based on SOAP.
- SAML over SSL is easy to understand. SAML over XML Signature and Encryption is a bitch to understand (especially holder-of-key).
- It is a bit heavyweight. Assertions contain metadata that's often duplicated elsewhere (such as your transport headers).
- There are several different identity & attribute formats that it supports (UUID, DCE PAC, X.500/LDAP, etc.). Mapping across identifiers may be useful inside an enterprise, but it won't scale as well as a uniform identifier.
- OpenID 2.0. It doesn't cover everything, there's questions about phishing abuse, but it's probably good enough. SAML is a clear influence here. The major difference is that it uses HTTP URIs for identity, whereas SAML uses any string format that an IdP picks (there are several available).
The questionable:
WS Business Process Execution Language (WS-BPEL)
What's good?
- Raising the abstraction bar for a domain language specifying sequential processes.
- It's more focused on programmers (and hence, vendors selling programmer tools) than on the problem space of BPM and Workflow.
- It relies on a central orchestrator, and thus seems rather like a programming language in XML.
- Very XML focused; binding to specific languages requires a container-specific extension like Apache WSIF or JCA or SCA or ....
- BPEL4People and WS-HumanTask are a work in progress. Considering the vast majority of business processes involve people, I'd say this is a glaring limitation.
- BPEL treats data as messages, not as data that has identity, provenance, quality, reputation, etc.
- I think there is a big opportunity for a standard human tasklist media type. I haven't scoured around the internet for this, if anyone knows of one, please let me know. This would be a win for several communities: the BPM community today has no real standard, and neither does the REST community. The problem is pretty similar whether you're doing human tasks for a call center or for a social network, whether social or enterprise. Look at Facebook notifications as a hint. Semantics might include "activity", "next steps", "assignment", etc. One could map the result into a microformat, and then we'd have Facebook-like mini-feeds and notifications without the garden wall.
- As for a "process execution language" in the REST world, I think, if any, it probably would be a form of choreography, since state transitions occur through networked hypermedia, not a centrally specified orchestrator.
Other questionables include SOAP mustUnderstand, WS-ReliableMessaging and WS-Policy. But I don't really have much to say about them that others haven't already.
Phew! Wall of text crits you for 3831. So much for being brief...December 31, 2007
Continuing the debate
Some comments on this and that, because JJ's comments truncate at 3000.
- "Talking with Subbu, I think I understand the disconnect. He works for Yahoo (same would be true for Amazon, Google, Microsoft Live...). For these people, who operate vast data centers, every CPU cycle counts. It speaks directly to their user base: if yahoo is sluggish people will switch to Google and vice versa. I, on the contrary, work as an IT architect. "
Subbu is ex-BEA. I think he understands IT architecture, thanks.
- "For IT, If I can reuse a piece of code 2-5 times, this is a tremendous savings: imagine the cost of duplicating assets in IT? re-implementing, re-testing, integrating? how about maintenance? now I need to apply my changes to several code bases in different technologies?"
I've discussed this in email with you, but besides the technical challenges, SOA reuse is a pipe dream for most organizations because they are not willing to change their investment evaluation windows or mindset about the economics of software. Most are just looking to improve their agility -- which is about the way we design interfaces & interactions, not about reused logic.
- "Guys, in the Ganesh's style, I have news for you. There has been a big composite system running for decades: EDI. "
It's not news. Mark Baker has been talking about EDI for years as an example of interchange with a type of uniform interface.
- "Stu, I may misunderstand your point but you seem to say that one thing (we need actions) and the opposite (a uniform interface gives more loose coupling, therefore don't use actions)."
What I agreed with you was that we need a *contract* to generate shared understanding. I did not claim that we needed specific actions to generate shared understanding. On the other hand, I do think it would be useful to define higher-level abstractions in terms of uniform operations, though I am not convinced this will enhance interoperability.
- Your definition of loose coupling seems to reflect a very producer-focused view of services.
For example:
"RESTful Web Services indeed offer a coupling worse than CORBA, much worse because at least with CORBA you have an explicit interface to re-write the implementation on the opposite side. So in REST, if Pi changes, someone has to communicate to the other side (pick your method: email, blog, telephone, SMS...) what has changed."
Last I checked, Yahoo!, Google, or Amazon do not email me whenever they change Pi.
" As a matter of fact, thinking that any uniform interface is going to do the job is the biggest fallacy of the decade."
You have not demonstrated this beyond a bunch of hand waving that somehow "action oriented interfaces" are going to enable evolvability. I don't see it happening very often in practice. We'll see when your article comes out, but again, I caution against writing an article that is based on a strawman of your own design.
- Guy, this is no heresy, this is a fact and you know, facts are stubborn: our world is made up of actions, it is not "uniform".
This is not a fact, it is your opinion. This is sort of like saying "the world is not made up of objects" or "functions" or any of the many abstractions & constraints we choose to model our information systems. One idea is to take a look at Alexander Galloway's book _Protocol_ (if you don't mind philosophy). It talks a lot about the control structure of internetworks and how it is this very uniform control that enables an explosion of diversity at higher levels.
- "Eliminating Pi and Ci is the worst architectural choice you can make. It means a) your implementation is directly wired at the Pe and Ce levels and b) you constantly rewrite application semantics protocols on top of this uniform interface"
:Shrug:. I think the best bang for the buck is to lower the barrier to change for consumers by completely decoupling Pi and Ci from their external representaitons. You want to lower the barrier to change for producers by tying Pe and Ce more to Pi and Ci.
Example: You want to enable people to buy books from you. Do you
a) expose your API with WSDL?
b) conform to what clients already understand and build a set of uniform resources (like a website)?
(b) arguably requires more thought than (a) but has been more successful in practice. And there are plenty of web frameworks that are closing the gap with how productive it is to expose resources.
Your argument seems to reflect to a desire to make external representations align to the programmer's reality as much as possible, instead of designing the external interface to induce properties for the overall system. That's contrary to good architecture, especially "collaborative systems" architecture, as Rechtin & Maier would call it, where there is no overall owner or controlling entity.
One could argue, that the enterprise isn't like this -- it has a controlling entity (the CIO, or whatever). Except most enterprises that I've seen are decentralized messes, run with a Feudal governance model, or a Federal (i.e. politicized) model. But, it is not centralization vs. decentralization that matters, it is the balance of power. Thus I believe most large organizations could use with a dose of uniformity baked into their systems architecture -- it will help them gain quite a bit of traction in maintaining that balance.
- "XML, XSD, WSDL, SCA, BEPL, WS-CDL (and ebBP), WS-TX(and WS-CAF), WS-Security, WS-Eventing"
Half of these are not implemented widely. WS-Eventing and CDL probably will never be. SCA, I continue to note, is an implementation-level technology and doesn't enhance interoperability at the Ce / Pe level in any way. They help link Ci / Pi to the external representation, and frankly I could see an SCA binding for RESTful interfaces, though I think there would be gaps for dealing with link traversal.
- "They will understand that they have a lot of work to do, very hard work (not just to establish a robust communication infrastructure), to come even close to what WS-* has to offer today (not tomorrow, not in ten years)."
WS-* doesn't offer half of what you seem to claim it does today. Yes, it's a useful stack, yes it has some benefits, but reuse and loose coupling are not part of them.
- "(Stu I will also respond on choreography -I am not caught up on choreography, choreography is just another way to express Pe and Ce in a single artifact. It also adds some sequencing of operation compared to WSDL alone)."
WSDL alone does not specify much about the semantics or constraints on interactions beyond MEPs and expected data types. Ordering constraints are fundamental! In WSDL today, you understand them by reading a human language document! We're back to this fiction that somehow WS-* provides you a machine-readable contract. It doesn't. It gives you tiny slices of it to help generate code or activate your security or messaging subsystem, but the rest is an exercise for the reader.
Anyway, I think I'm finished debating you for a while. Please don't take this as implicit support for the ideas I have not directly addressed. You are on the right track in some ways, and very far away off in others. I look forward to your article -- if you'd like feedback on a draft, I am willing to look at it purely to ensure there are no major strawmen :-)
In any case, off to a New Years party. Happy new year!
December 19, 2007
SimpleDB simply sucks
I mean, I really like the idea of Amazon's SimpleDB. Auto-indexing is great. Scalable is great. The price is great. Forget that their REST API is a joke that will have to change as soon as people start losing or corrupting their data. Why the fuck are they throwing out relational theory? The database barely even supports 1st normal form! You can't do any kind of aggregate operation -- no count, min, max, avg, grouping! There are no integrity constraints anywhere!
Take a look at the example they give:
| ID | Category | Subcat. | Name | Color | Size | Make | Model |
|---|---|---|---|---|---|---|---|
| Item_01 | Clothes | Sweater | Cathair Sweater | Siamese | Small, Medium, Large | ||
| Item_02 | Clothes | Pants | Designer Jeans | Paisley Acid Wash | 30x32, 32x32, 32x34 | ||
| Item_03 | Clothes | Pants | Sweatpants | Blue, Yellow, Pink | Large | ||
| Item_04 | Car Parts | Engine | Turbos | Audi | S4 | ||
| Item_05 | Car Parts | Emissions | 02 Sensor | Audi | S4 | ||
| Item_06 | Motorcycle Parts | Bodywork | Fender Eliminator | Blue | Yamaha | R1 | |
| Item_07 | Motorcycle Parts, Clothing | Clothing | Leather Pants | Small, Medium, Large | Black |
Let's ignore that item_07 has the Color & Size backwards. You'll note that Color and Size are multi-valued attributes. If you look up Multi-Valued Attributes in any relational textbook, they'll usually say something like: "Abandon all hope, ye who enter here."
Lately, however, even the diehards are allowing for nested relations & complex types inside domains, so this in and of itself isn't a bad thing if you treat them as nested relations. With that interpretation, this table is intended to manage "names & options for a particular item". It is interpretable in (at least) 1NF. I can retrieve "item_01", for example, I know that this Cathair Sweater comes in Siamese and Small, Medium, and Large.
But, the danger is if you treat this as a table for, oh, say, ordering items! One needs to know if this is a Small or a Large sweater. The only way to get to 1NF is to treat {ID, Color, Size} as a compound primary key. All of your multi-valued attributes become implicitly a part of your primary key! But there are no integrity constraints, so you better make sure your code and gateway API understands that in the above ITEMs table the primary key for item_01 through item_03 and item_06 through item_07 is {ID, Color, Size} and for item_04 & item_05 it is just {ID} -- for now!
So, while it is possible to treat SimpleDB with some level of logic, beware that it's not necessarily designed to be logical.
I also am looking forward to the nightly SimpleDB extracts to MS Excel or SQLite, or Oracle or MySQL so I can, you know, query my data for trends & business analysis. On the bright side, maybe this is Amazon's way of convincing you to build your data warehouse early.
A rant, followed by RESTful choreography
This entry is a response to this entry from JJ. The first part of this is a rant of frustration. The second part is a discussion about the use for choreography in RESTful services.
[RANT]
"These were the only two people that had the courage to go to the end of the discussion even though they saw some limitations to the REST approach. Others, have stopped all communication as soon as they understood the problems with REST."JJ, I hope might occur to you that people in the REST community do have their own priorities, and answering your pages & pages of debate is not necessarily one of them. I'd personally like to take the time to get into this in detail, but time has been scarce leading up to the holidays.
Secondly, you have not exactly been providing a lot of incentives to participate. You have consistently put words in the community's mouth, you have made outlandish and derogatory claims about the future of REST, made erroneous assumptions as to the motivations of the community, and have questioned the level of knowledge & competency in the community. Yet you expect people to actually give you the time of day.
In short, I believe you are acting like a bully, someone who challenges all to a duel, but claims victory before anyone has the energy & time to go several rounds with you. I don't think many are that interested in trying to prove their architecture "street cred" with you, they really just want to build better network-based software.
Thirdly, it feels as if there is no way to actually have a fruitful conversation with you via your blog because it seems you're not trying to understand how REST might fit into your set of priorities. You seem to be primarily trying to poke holes in it and ultimately try to limit its potential audience in the enterprise. That in and of itself is a good thing, but when you are tearing down strawmen of your own making, it becomes very difficult to communicate.
Most debate rounds so far have resulted in you flooding your blog with observations that are either misrepresentations of REST (redefining terms as you see fit, denying explanations that are spelled out in Roy's thesis, etc.) or are orthogonal to REST (even if interesting & worthy of discussion!). You seem to continue to claim that when REST doesn't somehow auto-magically fix a particular problem, it is a reason to ignore/discard/mock it as a failed architectural style, and to deride the community as a bunch of loons. It's extremely discouraging to have a debate when you continue to flout common courtesy in this way.
Obviously we'd like someone like you to understand where we're coming from, and many of us would like to understand your concerns -- but there's only so much time in the day. Please be patient.
[/RANT]
Having said this, I haven't exactly given up, and hope to have more time to discuss some of your observations. Here are a couple of responses to your latest entry:
"The fact and the matter is that you CANNOT DO WITHOUT A CONTRACT to establish the shared understanding."
This has been the core argument I've seen you make, and I agree with it, but I think WS-* vs. REST is irrelevant here, as they address different concerns. So I think it's time we looked at doing this problem in detail. I do not believe that the WS-* stack gives you any such thing today, and mainstream WS-*, as it currently is led, is not heading in any clear direction to support this. WS-CDL, SCA, and WS-Policy will not get you there, not even 15% of the way, and probably will make life worse.
Today, in WS-* land, a contract is described by human-readable documentation, with certain degenerate yes/no policies described by WS-Policy. WSDL does not give anyone a shared understanding; at best, it is a template to generate code. A developer has to read the documentation that goes with the interface to know ordering constraints, non functional SLAs, any guards, preconds, postconds, etc. WS-CDL is not mainstream and is likely not an option (will discuss below).
SCA is not a pervasive solution to this because it is just an implementation-level container & component composition model -- it's a multi-language (but still Java-centric) alternative to the J2EE deployment model and EJB. It will not be adopted by Microsoft. And it doesn't (yet) help to specify contractual constraints any more than the WS* specs do.
Now, in REST, today, the contract is defined by the transfer protocol, the media type (which is usually a human readable spec), and perhaps an independent contract addendum to talk about specific ordering constraints (though forms & link traversal provide this information too), SLAs, etc. But in REST, just like in WS-*, there is no reasonable way to create a machine-readable shared contract of interactions & expectations.
So far, I would claim the difference is that due to the uniformity constraint, RESTful services naturally have a lot more loose coupling between service implementations than if we defined our own semantic community for service interfaces that include actions unique to a particular business domain. The data transfer protocol should not have to deal with business-semantics!
I *think* that what you're getting at is that you need a choreography language to truly build a shared understanding at a business-action level. If so, I agree! And I think this actually would be *great* for both REST and WS-* if the mainstream would embrace it.
In a RESTful choreography, all interactions, units of work, etc. should boil down into some kind of primitive uniform interface that everyone understands.
So, one might wonder -- what about WS-CDL? Sadly, WS-CDL has a number of problems:
- It doesn't seem to be generating a lot of popularity,
- It has some notable issues so far, mainly because it was blazing new trails way ahead of its time in a committee venue that's not built for such innovation;
- it embraced WSA without giving any love to Webarch, to its detriment;
- it also doesn't have a compact syntax, so many early adopters, especially those that don't like GUI modeling tools, aren't going to touch it.
But it serves as a model to improve on and a set of invaluable lessons.
A choreography language to describe RESTful interactions is absolutely doable, in my opinion.
To me, RESTful choreography would actually fix one of the bigger problems with WS-CDL today: it tightly binds the choreography to a particular WSDL and set of XML namespaces. Yet, a choreography arguably should be reusable across a variety of operation-level interfaces and/or schema documents. Furthermore, a set of services may participate in a variety of choreographies, particularly if we want any sort of reuse.
In short, the WSA way to improve WS-CDL so that it is more "reusable" would be to provide some kind of indirection between WSDL and the choreography and role descriptions.
The Webarch way would be to eliminate variation in the primitive bindings available in any ground choreography, and enforce uniformity. Hyperlinking would also provide a much easier time of managing tokens, identity references and channel references, I think.
"The fact and the matter is that a Result Set IS-NOT a resource"
Sez you.
A result set absolutely can be a resource: when I go to Google and get back a page search results, that's a resource (it has a URI, after all). Anything with identity, no matter how transient or persistent, is, by definition, a resource.
"For those of you who are not convinced yet, I suggest that tomorrow you try to drive your car with a (GET,PUT) interface (no links allowed) and then you tell me how you felt: : a state machine is a state machine and there is no way around it"
This is an absurd strawman. If you have no links, you're not doing REST, sorry. I have no idea what you're trying to prove by suggesting one can't drive a car via hypermedia.... what would the benefit be even if we tried?
"It has been notorious that REST is really bad at versioning (I am preparing an article on this topic that will be published early January)..... Have you tried to bake in versioning in a RESTful resource access? you mean that the URI of the resource depends of the version? Ouch..."
It has only been notorious in your own mind. I caution against writing an article based on a strawman of your own making.
Versioning information is usually included in representation state, not in the URI. There are times where you may want a new resource altogether, but that depends on the extent of the change and whatever backwards compatibility policy you are following.
"The second detail they missed is that Amazon is probably going to publish BigDB at some point and maybe they will want to develop a true CRUD, SQL based API. Have you ever tried to implement this kind of API in a RESTful way? huh? you mean you can't?"
This is the kind of "putting words in people's mouth" I ranted about above.
No one is claiming that REST is the only type of architectural style that's appropriate. Remote Data Access styles like SQL gateways are very useful. Just don't expect millions of diverse users to hit your SQL service with good scalability, reliability, and visibility! I mean, even in component-oriented SOA one tends not to expose a generic SQL endpoint except in scenarios where a generic interface for a relatively small audience is required.
The points against Amazon are that they're claiming that SimpleDB has a "REST API", but they are making a mockery of the term. Their implementation is running *against* the way the web is supposed to work, and means that no pre-fetching user agents or intermediaries can safely be used with SimpleDB as they may be a source of data integrity problems. This has nothing to do with religion, it's about Amazon's REST API author being completely oblivious to 15 year old architecture and recent history like the Google Web Accelerator.
December 11, 2007
A note on science
In reading Gary Taubes' new book Good Calories, Bad Calories, along with his recent UC Berkeley webcast, he drew my attention to the great and quotable Claude Bernard, who was the father of the science of medicine, and the man who discovered homeostasis.
Some quotes I think are quite worthy of reflection:
"Particular facts are never scientific; only generalization can establish science.""A great discovery is a fact whose appearance in science gives rise to shining ideas, whose light dispels many obscurities and shows us new paths."
"In experimentation, it is always necessary to start from a particular fact and proceed to the generalization....but above all, one must observe."
Some ways to look at this:
- If you observe something that contradicts your prevailing theory, perhaps that theory is wrong.
- If you observe something that no mainstream theory explains, perhaps an alternative hypothesis is worthy of further study.
- One does not improve knowledge in a scientific manner by just building, specifying, or explaining new things. One improves knowledge by observing effects, and working back and fitting a consistent hypothesis.
I find in our profession, we most often fall back on arguments from authority over arguments from empirical evidence. This takes several forms: "If a particular vendor/community/person builds it, it MUST be good.", "if the experts agree, it they MUST be right", "if the analysis say it will be so, we MUST invest in it", etc.
Perhaps all of this is because it's so hard to create a controlled experiment when dealing with systems science (except perhaps as simulation). Or because most empirical observations in our field are anecdotal, because we don't have an open environment sharing results due to competition. I also think it may have to do with business managers' need to make technical policy decisions where a YES/NO is required, and tend to be taught that deferrment is bad.
Taubes' book, by the way, is a very deep technical read on the science of obesity, heart disease, fat accumulation and a political history of how policy makers mixed with inconclusive science may lead to a generation or more of disastrous consequences.
I take heart that technologists aren't the only ones known for their great blunders, but I pity the victims. The world needs paradigmatic subversives.
November 13, 2007
To see what is in front of one's nose requires a constant struggle
Monsieur Dubray has posted nearly 5 blog entries critical about REST.
Almost everything Mr. Dubray claims "you're on your own" with REST is either a tremendous misunderstanding, an emotionally projected argument, confuses implementation technologies with protocol-based interoperability (e.g. SCA and SDO are jokes until it binds to the Microsoft stack, JJ), or it is in area where you're equally on your own with WS-*.
Contracts? WSDL is not a contract. XSD is not a contract. WS-Policy neither. They're interface descriptions. True contracts? You're on your own. By the way, REST relies on *very clear* contracts, as clear as anything in a well designed SOA. The difference is in how the architecture determines & applies them.
Versioning? XSD is notoriously flawed in this regard (though they're working on it). And there is more than that -- SLAs (no standard), security (WS-SecurityPolicy covers only some use cases), etc. You're on your own.
I had begun writing a point-by-point debunking, but, life's too short, and I'm busy enjoying Cancun at the moment. No one denies there's a lot of work to do in applying REST (or successor styles) to enterprise work, but that doesn't mean we shouldn't try. JJ, if you would like to have a reasonable conversation about this, let us know, otherwise please keep insulting us, any press is good press. ;-)
REST as a style in support of enterprise SOA is like XML, circa its release in 1997 -- great promise without a lot of satellite specs & infrastructure supporting it (in security, for example, though this is probably going to be fixed next).
WS-* is where CORBA was circa 1997: it will be used to implement some good systems, but there will also be some high profile failures. A number of the specs will likely never be adopted by the mainstream (see WS-CDL, WS-Eventing), though some will definitely improve some ridiculous vendor interoperability disputes (e.g. WS-TX, WS-RM). Plenty of pundits (now bloggers) sing of its imminent triumph (channelling Orfali, Harkey and Edwards), but overall, the framework will not help solve the problem that was used to sell its adoption in the first place: increased agility, reuse, and visibility in IT. I think many WS-* tools actively *hinder* an SOA architect from achieving these goals.
November 10, 2007
RESTful normalization
Why is RESTful design thought to be hard? I said this during Sanjiva's talk at QCon, but here's my one line summary
RESTful design is like relational data normalization.
Even though both are driven by principles, both are an art, not a science. And the popular alternatives, unfortunately, tend to be driven by craft and expediency.
The analogy could be taken further: "good RESTful designs" today, of the WADL variety, are very similar to 1NF. With ROA and the "connectedness principle", we're just starting to move into 2NF territory, I think.
Witty aporisms abound: "The Key, the Whole Key, and Nothing but the Key, So Help me Codd" sounds a lot like "Cool URIs Don't Change".
We haven't quite yet found the RESTful 3rd Normal Form "Sweet Spot".
"Everyone knows that no one goes beyond 3NF", so perhaps RDF and the Semantic Web are REST's 6th Normal Form, because they "scare people". Amusingly, Chris Date actually seems to think so.
I just *really* hope we don't have to go through 20+ years of defending REST the way Codd & Date had to defend the relational model against unprincipled alternatives, a debate that continues to some degree almost 40 years after Codd's original paper. If, in 2037, we're still debating the merits of Roy's thesis, I'd rather be a bartender...
November 09, 2007
QCon San Francisco, Day 2, thoughts
The REST track, hosted by Stefan, was great fun -- Floyd mentioned to me that the track in London wasn't so packed, but the room in San Fran was standing-room only for some of the talks. Stefan has rough notes of most of the proceedings on his site, so here are my reflections.
Steve Vinoski's talk was a good introduction to the crowd on REST's constraints and the desirable properties brought out of those constraints. "SOA Guy" brought out common counter-arguments from the SOA architect's position. A favorite point: SOA does not stand for "Special Object Annotations" :-) I also learned that we share a love of Mountain Dew (sadly decaffeinated in Canada, though).
One question from the crowd was: Isn't REST just pushing the interoperability protocol to the data type, not solving the interoperability problem? Here's my take: application protocols are about expectation management. Even though it's generic, the HTTP methods + metadata + response codes provide a wide range of signs, signals, and expectations for communication. So, while it's not aligned to what you're doing specifically, it means that we can discover & communicate, generically, almost any piece of information -- a very valuable form of interoperability.
This does not, of course, solve the the data (MIME) type tower of babel. That's the next battle. There is a tradeoff between intertwingling syntax and semantics. Doing so, like with XML Schema and its ilk, is easier for programmers, but harder to interoperate if the domain is business-biased. There's more potential for disagreement when designing a data format for an industry than for some general-purpose infrastructure. On the other hand, using a generic syntax, whether Microformat-based XHTML, is a bit harder to program with, requiring tools support, but arguably could lead to better interoperability. And, taking this progression further, a completely generic logical data format, like RDF/XML, is even harder to program for, but once the tools exist (similar to SQL query engines), the potential is vast.
A more few reflections. Why do people misunderstand REST? For example, REST and WOA are about anarchy & avoiding standardization according to this gentleman. Who are these WOA people he speaks of? This strikes me as a projected argument, something that's derived from the emotional reaction of "I'm afraid you are saying X", when the Other isn't actually saying X. It reminds me of the early days of Extreme Programming, where pundits claimed "Egads, XPers say you should not design your software!"
Another example, is "You REST people think it will take everything over and be the only architecture!" Which is again, an emotionally projected argument, something I don't think anyone is actually saying. The points are that effective architecture at scale requires emergent properties to be induced through constraints, and that networked hypermedia might be a shift in thinking in the way that objects were a shift, and deserves attention. (Apparently we're in the mid-70's Smalltalk phase of that revolution, however. :-)
There are two common angles where I think people miss the point of REST here:
- When people don't believe there's such a thing as emergence;
- When people don't get/remember or relate solid software engineering principles to their distributed systems. In particular: interface segregation, and stable dependencies and abstractions. REST is really just a pattern that takes those principles seriously for a collaborative information system.
On to the further talks....
Sanvija's talk brought out the most useful debate of the day -- there's so much more dialogue that could (and SHOULD) happen on every one of those slides, to absorb where we misunderstand each other. Stefan's blog entry captures a lot of my questions and comments that I made during this session; afterwards I thanked Sanjiva for putting up with me. ;-) Hopefully this one will be posted in InfoQ.com sooner rather than later, it was a fun time.
Pete Lacey went through demonstrating the 'ilities' of REST, where he discussed the constraints and properties in more detail and, in code showed an XHTML-based (but also Atom and plain XML representation-based) REST API for an expense reporting system. He proceeded to show integration via a Microformat browser, curl, ruby, Microsoft Excel, and Word.
This sort of demo is very important, as it's the only way I think people will begin to get what serendipitous reuse is about. Not everything is encoded in a managed business process -- Microsoft Office still glues a vast amount of business activity together!
Dan Diephouse discussed building services with the Atom Publishing Protocol. I enjoyed this: it was hands on, code-oriented, and wasn't just a love-in: we spoke equally of the benefits and current open challenges with this approach to publishing data on the web.
And, though I met him at lunch, I unfortunately missed Jim Webber's final talk of the track day, due to some work commitments! Hopefully I'll catch the video when it's posted on InfoQ.
QCon San Francisco, Day 1, thoughts
Kent Beck gave the first keynote speech at QCon, which was a good talk on the trend towards honest relationships, transparency, and sustainable commitments in software development: the "agile way" is aligned with the broader business trends like Sarbanes-Oxley, greater transparency, board and management accountability, etc.. He claimed during the keynote (I'm paraphrasing):
"Agility is an attitude regarding one's response to change."
I asked him the following two part question:
"There seem to be two trends in industry -- the Agile methods movement, which is about Agility as an attitude, and the Agile architectures movement, which is about introducing enterprise-level and "systems of systems" level architectures that help to enable greater agility. The questions are:
1. Do you believe architecture actually can enable greater agility? Regardless of what religious school you belong to, SOA, REST, Data Warehousing, etc.
2. How do Agile teams, with the attitude, build productive relationships with Enterprise Architecture teams, whose goals and attitudes often are at odds with the executing team?"
Kent's Answer for #1 (paraphrasing): "I've always believed that design matters, from the smallest implementation detail, to the largest architectural arrangement of software. Design can enhance communication."
Kent's Answer for #2 (paraphrasing again): "It can be a hard thing, but it's important to recognize that the EA saying 'you can't code without our approval', and the developer having to wait three months, doesn't have to be about a power struggle. There are two different principles and values at play here, both attempting to get to agility. The goal must be to get past the noise of the specifics like 'you need to build things this way' and find a shared understanding of the principles that underlie such decisions. If I, as an Agile team leader, believe in principles like the time value of money, or in the lean principle of flow, I'm going to try my best to ensure that there is a shared understanding of their impacts. Similarly I would hope to understand the principles that underly the EA's decisions and policies. It's the only way to get past the politics."
Richard Gabriel, always thought provoking, gave two talks that I attended. The first was:
"Architectures of extraordinarily large, self-sustaining systems"
So, assuming a system that was trillions of lines of code, millions of elements, thousands of stakeholders, beyond human comprehension, and must provide advantages over an adversary, how would you design such a system?
Firstly, a reflection on the requirements. The "gaining advantages over an adversary" part of this description seems to be similar to the Net Centric Warfare (NCW) movement -- it's very Strategy as Competition oriented, I'm not sure I agree it's the right frame of mind for thinking of this sort of thing, but it probably belies who is funding the effort. Lately I have noticed that NCW is becoming more and more "Web-like" and less "SOA-like". The publication, Power to the Edge, a revised treatise on NCW concepts, really screams out "Web!", or at least some successor to it. Strassmann more or less predicted this in the early 90's while he was running the DoD, and correctly surmised that it's political and human comprehension that's holding up the transition.
Back to the talk. Dick Gabriel explored three approaches to design:
- inverse modeling is tractable -- meaning, we can work out the design of the system top-down, and in advance
- inverse modeling is intractable -- meaning, stepwise refinement (ala. 'agile design')
- evolutionary design -- wherein we use evolutionary techniques, such as genetic algorithms, to "grow" a solution. The design is indistinguishable from the implementation this case.
On #3, he pointed to Adrian Thompson's work on Evolutionary Electronics. This was some of the creepiest, coolest, and most bizarre results one could imagine: Adrian literally "grew" a 10x10 section of an FPGA, using genetic algorithms, to solve a simple tone discrimination task. It executes the task flawlessly. The problem is, they don't actually know how it all works! See the paper here.
Reflection: I was surprised he did not speak about the work on "collaborative systems" or "systems of systems" by Mark Maier (of IEEE 1471-2000 fame) and Eberhardt Rechtin. This approach fits in with Roy Fielding's REST dissertation on the beginnings of an architecture science: inducing emergent properties on a system by way of constraints. I was going to speak with him about it, but he was mobbed by several attendees at the end, and figured I'd get my chance some other day....
Dick noted that "the Internet" as a whole isn't really an "ultra large scale system" that he's looking at because it doesn't have a directed purpose. This is curious -- the Web, an application of the internet, had a goal: increase the sharing information of any type, globally, exploiting Reed's law.
The Web doesn't have an adversary though... does it? Hmmm, maybe it does.
Dick's second talk was a repeat of his OOPSLA presentation 50 in 50, a whirlwind tour of many programming languages over the past 50 years, accompanied by music. This presentation is available via OOPSLA podcast, and while it doesn't quite work without the visuals, I recommend it if you're interested in how much creativity there has been out there (and how, we're only starting to regain some of that creativity now after 10+ years of JavaJavaJava). Hopefully the slides will be eventually made available as a Quicktime...